

本記事は2021年3月5日にJosh Odgers氏が投稿した記事の翻訳版です。
私はしばらくの間、社内のエンジニアリング/QAだけでなく、お客様がNutanixのより詳細な機能を迅速/容易にかつ反復してテストできるように、新しいX-Rayシナリオの構築に取り組んできました。
HCIプラットフォームの可用性、回復力、そして整合性シリーズでは、Nutanix AOSとVMware vSANの両方でテストがどのように機能するかを詳細に説明しており、AOSがvSANに対して大きな優位性を持ち、最小3ノードの構成で障害が発生しても常にデータの整合性(可用性と回復力の両方)を維持できることを強調しています。
一方、vSANは、より高いI/Oタイムアウト、より大きなクラスター、3つのデータコピー(FTT2)でもI/Oエラーが発生します。
しかし、私の言葉を鵜呑みにせず、ご自身でもテストを行ってみてください。
Nutanix ポータル から X-Rayバージョン3.10.2の、vSphere用のOVAまたはAHV用のQCOWイメージをダウンロードし、テストを行う予定のクラスターとは別のクラスターにデプロイするだけです。
その後、WebブラウザでX-Ray VMのIPアドレスに移動し、「ターゲット」クラスターを設定し、検証を実行して、すべての帯域外管理と認証情報が機能していることを確認すれば、準備完了です。
デフォルトのオプションでは、メンテナンスモード、再起動、および10%の稼働率でのノード障害のシミュレーションを含む、プラットフォーム全体の回復力テストを実行します。
このテストでは、クラスター内の1つのノードを除くすべてのノードに1つの仮想マシンをデプロイすることで、クラスター内のノード数に応じて自動的にスケールします。これにより、適切なサイズの実環境であるN+1をシミュレートするとともに、各ノードのフラッシュドライブ数に基づいて目標I/Oレベルを調整します。
フラッシュデバイスの数に基づいてI/Oレベルを調整することで、現実的ではない、あるいは人為的に高いエラー数につながる、小規模ノードやクラスターへの単純な過負荷を避けることができます。
このテストの目的は何でしょうか?
簡単に言えば、もしもHCIプラットフォームが、VMの可用性に影響を及ぼしたり、I/Oエラーに悩まされたりすることなく、テストのすべての段階に繰り返し合格できなければ、それは本番用途における最低限の要件すら満たしていない製品です。
そして、本番環境での使用に適していないものは、テストや開発にも使用すべきではないと私は思います。
それでは、テストとそのオプションについて見てみましょう。
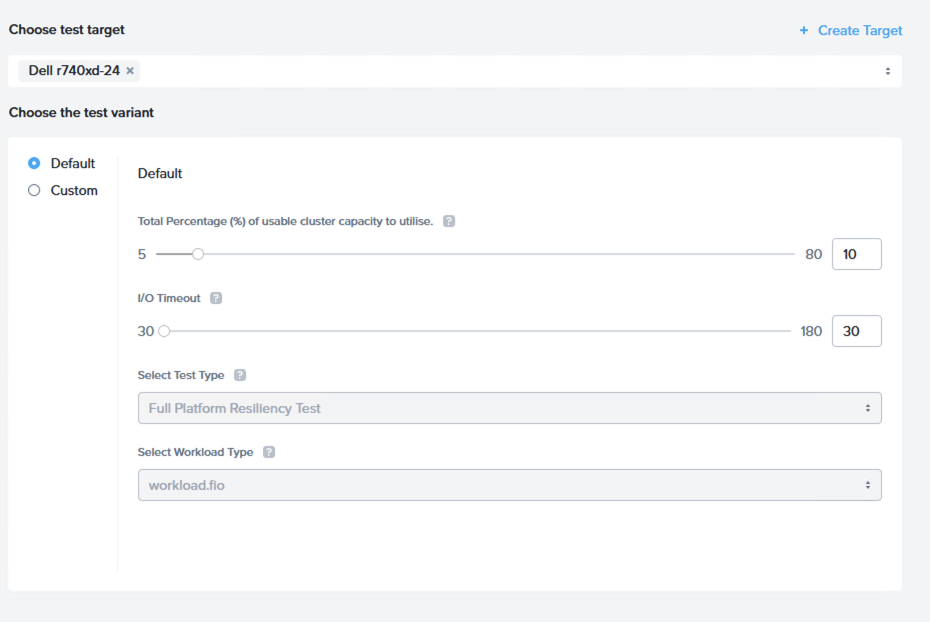
このテストの主な目的は、概念実証、インストール後の運用検証、構成変更後の検証の一部を、迅速かつ容易に実行できるよう、非常にシンプルな操作性を実現することです。
このテストでは、クラスターの有効/使用可能なストレージ容量を自動的に検出し、そのうちの10%をテストに使用しますが、80%まで増やすことも可能です。
次に、この業界における標準的なI/Oタイムアウト設定(30秒)を使用して、3つのフェーズで構成される、プラットフォーム全体の回復力テストを実行します。
フェーズ1:メンテナンスモードサイクル
このフェーズでは、クラスター内の最初の4つのノードそれぞれが、再起動前にメンテナンスモードに移行されます。仮想マシンはクラスター内(のノード間)を移動し、I/Oを実行し続けます。
3ノードのクラスターの場合、テストは自動的に3ノードにのみ適用されます。
フェーズ2:再起動サイクル
このフェーズでは、クラスター内の最初の4つのノードが、メンテナンスモードへ移行せずに再起動されます。仮想マシンは再起動処理の前にノードから移動され、I/Oを継続します。
フェーズ3:パワーオフサイクル
このフェーズでは、クラスター内の最初の4つのノードを帯域外管理によってパワーオフすることで、ノード障害をシミュレートします。仮想マシンはパワーオフ操作の前にノードから移動され、I/Oを継続します。
テストの各フェーズでは、I/OアクティビティとI/Oエラーがそれぞれ監視・報告されます。
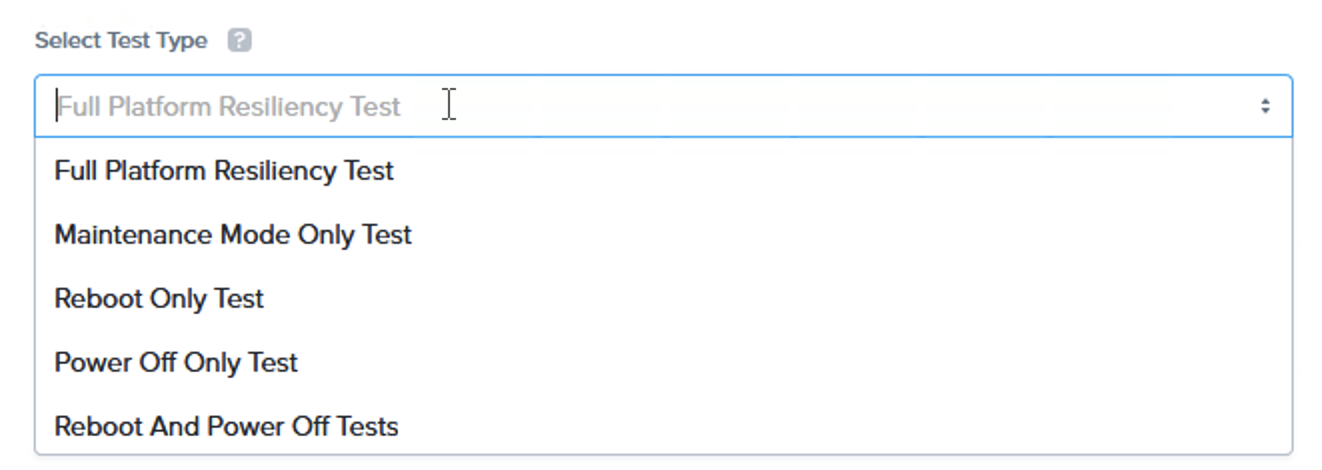
「カスタム」テストを使用して、テストのサブセットのみを実行することもできます。これにより、各フェーズを個別に実行したり、再起動とパワーオフを組み合わせたテストを実行したりすることができます。
各VMは12個の仮想ディスク(VMDKs/vDisks)に分散された、非常に軽いFIOワークロードを実行します。
12個のvDiskを選択しているのは、ワークロードをVMware ESXi上の複数のPVSCSIコントローラーに最適に分散させることで、vSANのようなプラットフォームが最大の可用性とパフォーマンスを得られる、クラスター全体にオブジェクトが分散された最良の状態を得られるようにするためです。
もちろん、Nutanix AOSは、仮想ディスクの数に関係なく、データをクラスター全体に動的に分散させます。Nutanix AHVは、各vDiskがローカルストレージコントローラ(CVM)に直接TCP/IP接続されているため、vDiskの数に関わらず、最適なデータパスを維持します。このHCIに特化した設計により、複数のPVSCSIコントローラーを導入したり、最適なパフォーマンスを得るためにコントローラー間でVMDKを手動で分散させたりする、といった複雑さが解消されます。
また、このシナリオでは、I/Oタイムアウトをデフォルトの「30秒」から最大「180秒」まで変更することができます。
なぜタイムアウトはデフォルトで30秒に設定されているのでしょうか?
これは、KVM用のVirtIOドライバー(AHVでも使用されています)はデフォルトで30秒 のタイムアウトを使用しているのに対し、vSphereのPVSCSIコントローラーはデフォルトで180秒となっているためです。
このように、プラットフォームによってはNutanix AOSほどの回復力がなく、I/Oエラーを避けるためにもっと高いタイムアウトが必要な場合があるので、タイムアウトをカスタマイズできるようにするのがベストだと考えました。
それでは、Nutanix AOS 5.19でのテスト結果を見てみましょう。
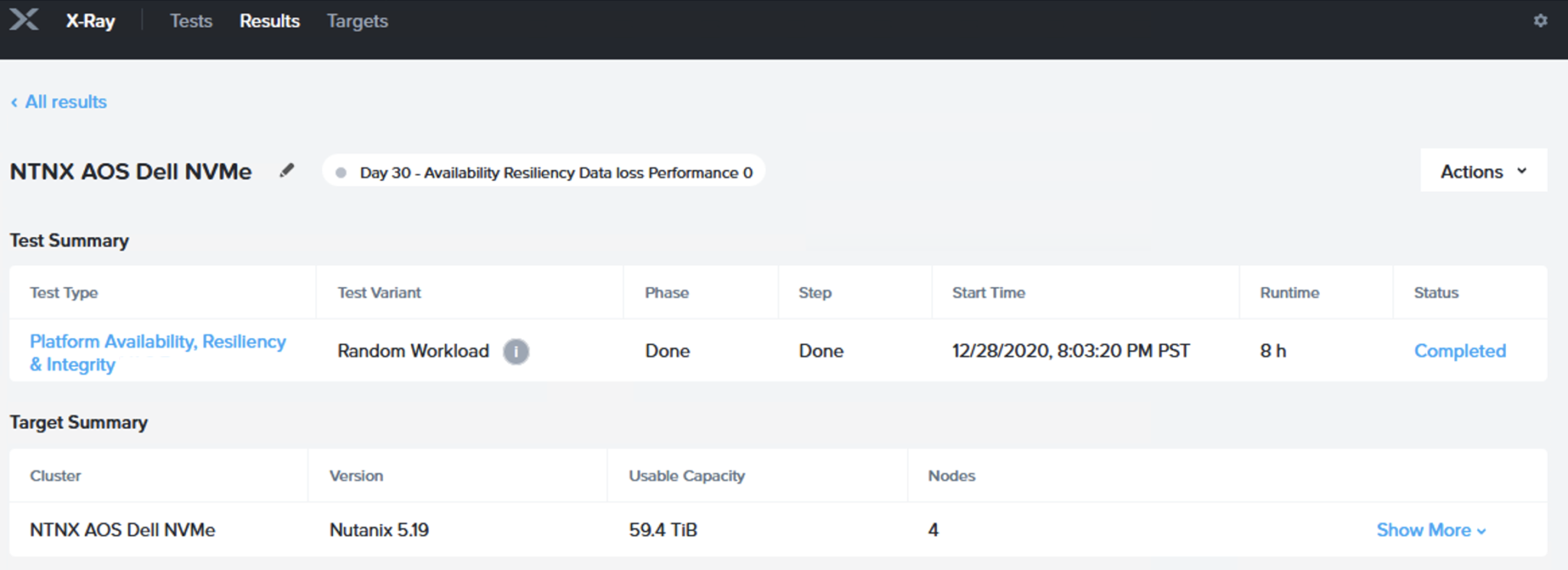
上記のテスト概要は、59.4TBの使用可能な容量を持つ4ノードクラスターを使用して、プラットフォームの可用性、回復力、および整合性のテストを実行したことを示しています。これは、3つのVMで約5.9TB(つまり各々が約2TB)のアクティブなワーキングセットが使用されたことを意味します。
「Show More」ボタンをクリックすると、X-Rayはハイパーバイザー(ソフトウェア)のバージョン、CPUの種類、RAMの容量、ドライブの種類と容量など、基盤となるハードウェアの情報を表示します。
下にスクロールすると、「詳細グラフ」のセクションがあります。
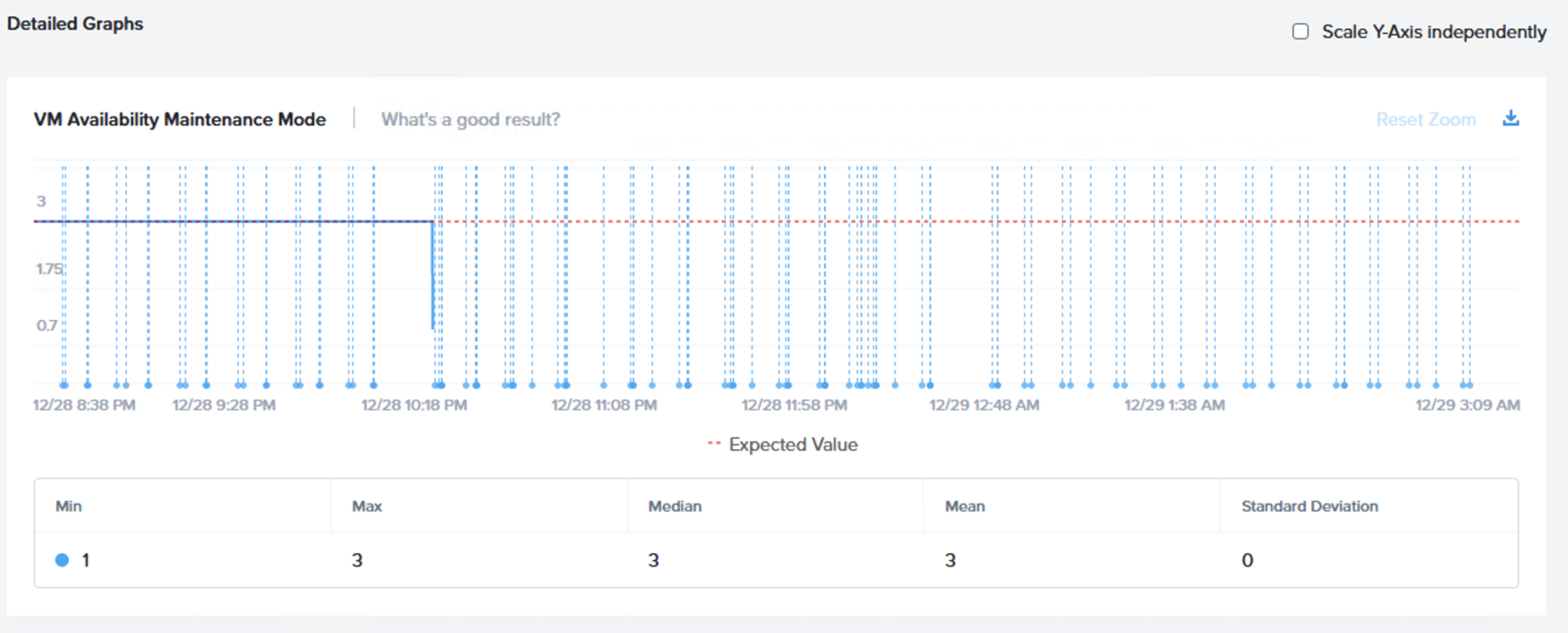
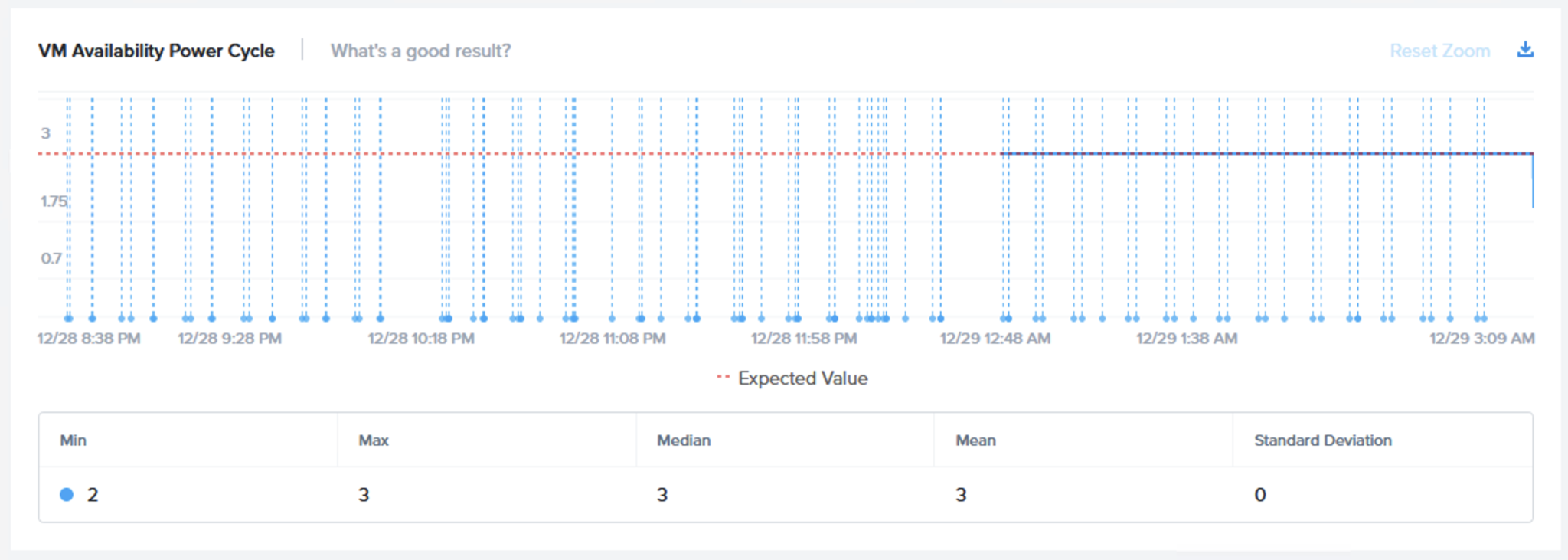
最初は「VM Availability – 仮想マシンの可用性(Maintenance Mode – メンテナンスモード)」チャートです。テストにおけるメンテナンスモードのフェーズで3台の仮想マシンがI/Oを持続していたことを示す3が表示されることが期待されます。
次のグラフは、このフェーズで3つの仮想マシンがオンライン(利用可能)で、I/Oを実行していたことを示しています。
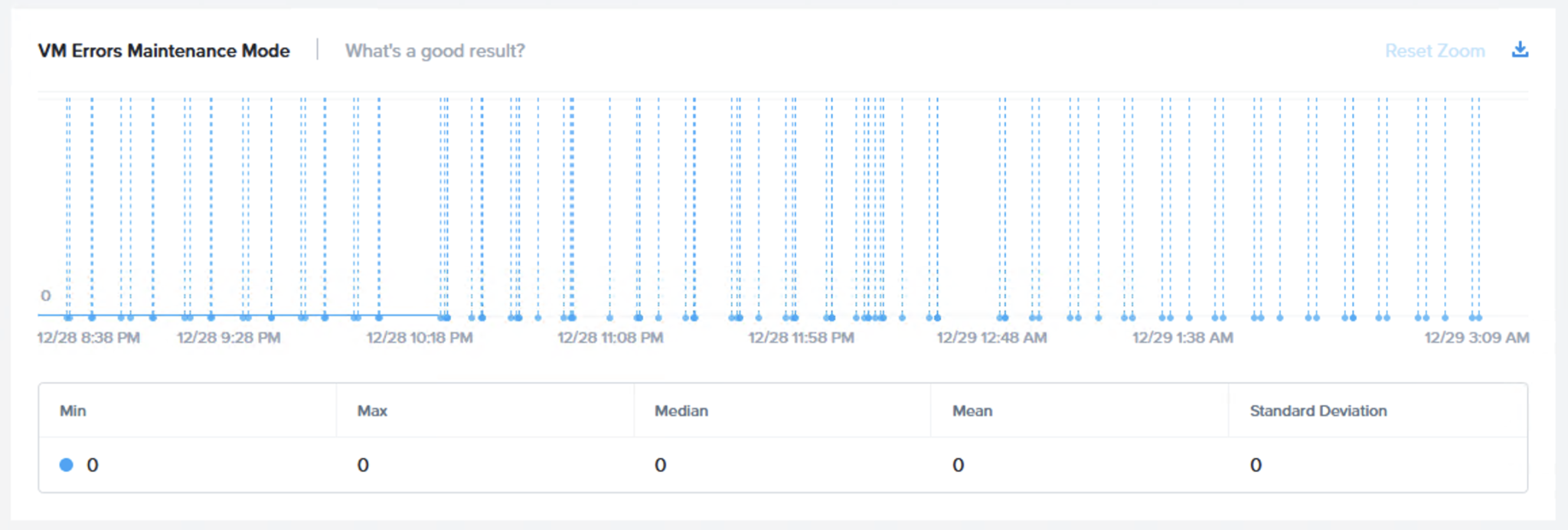
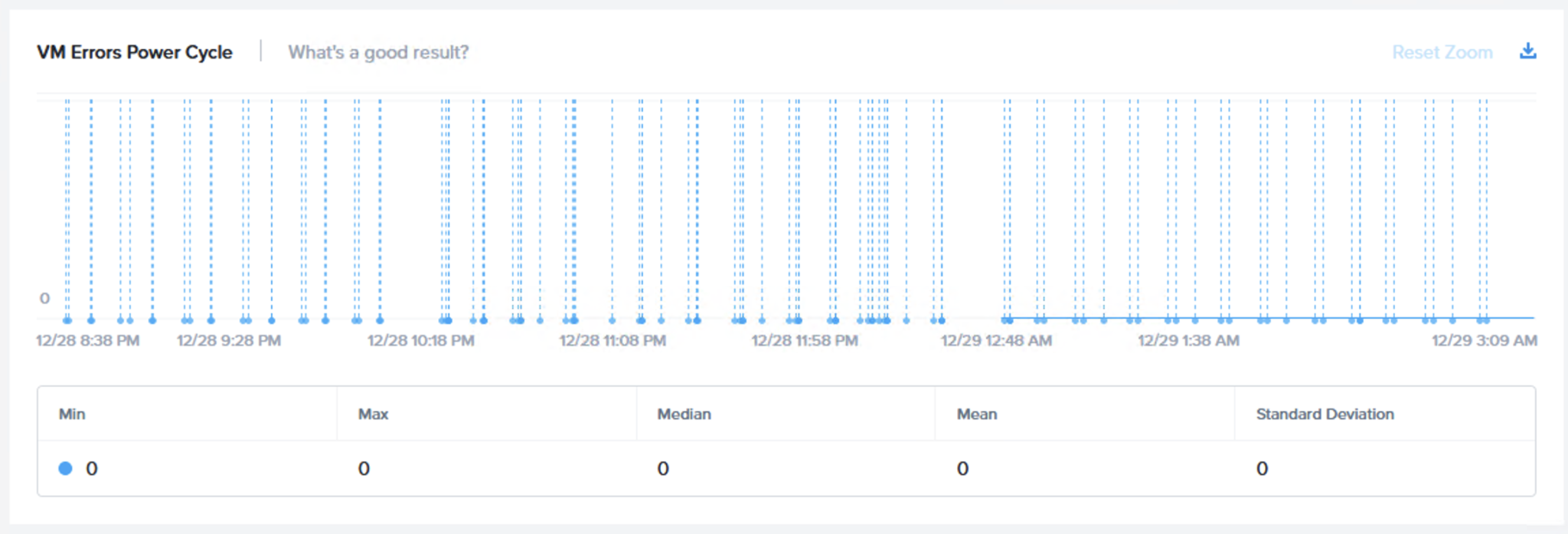
次のグラフは、「VM I/O Errors – 仮想マシンのI/Oエラー (Maintenance Mode – メンテナンスモード)」です。もちろん、期待される結果はエラーがないことであり、このグラフはそれを示しています。
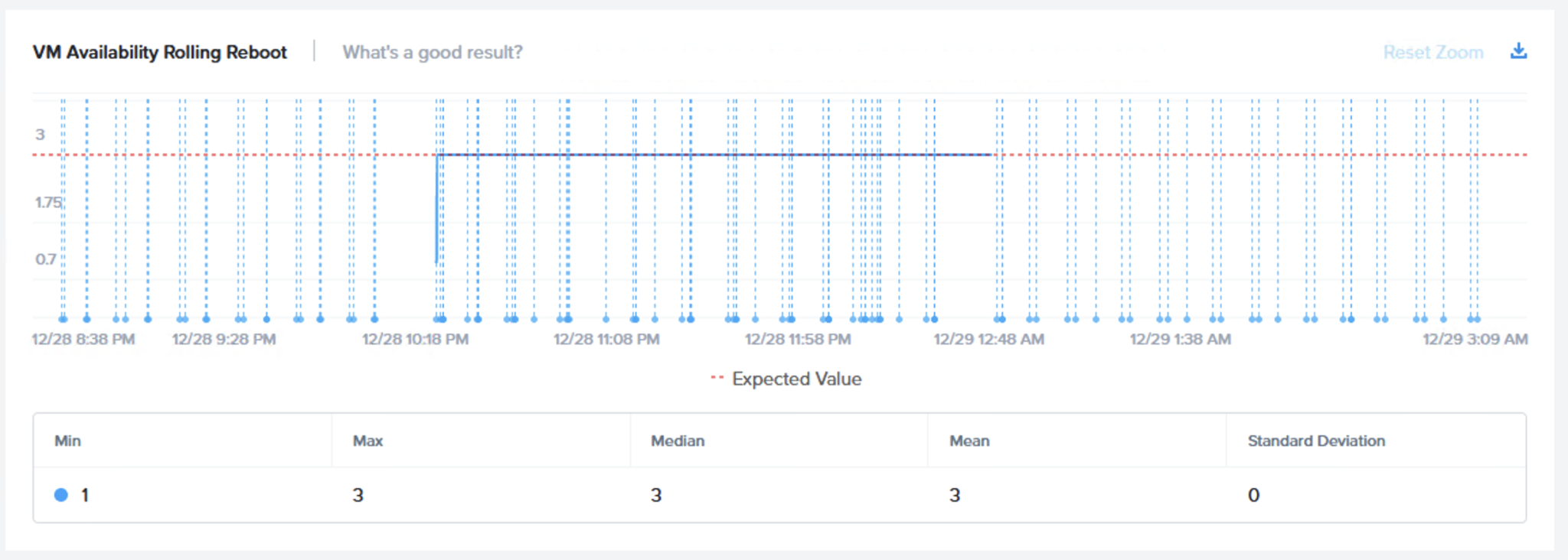
次のフェーズはローリングリブートです。同じように「VM Availability – 仮想マシンの可用性 (Rolling Reboot – ローリングリブート)」と「VM IO Errors – 仮想マシンのIOエラー (Rolling Reboot – ローリングリブート)」の2つのグラフが表示されます。
メンテナンスモードのフェーズと同様に、このテストでは、ノードごとに1つのVMがテスト中にI/OエラーなくI/Oアクティビティを維持することが期待されます。
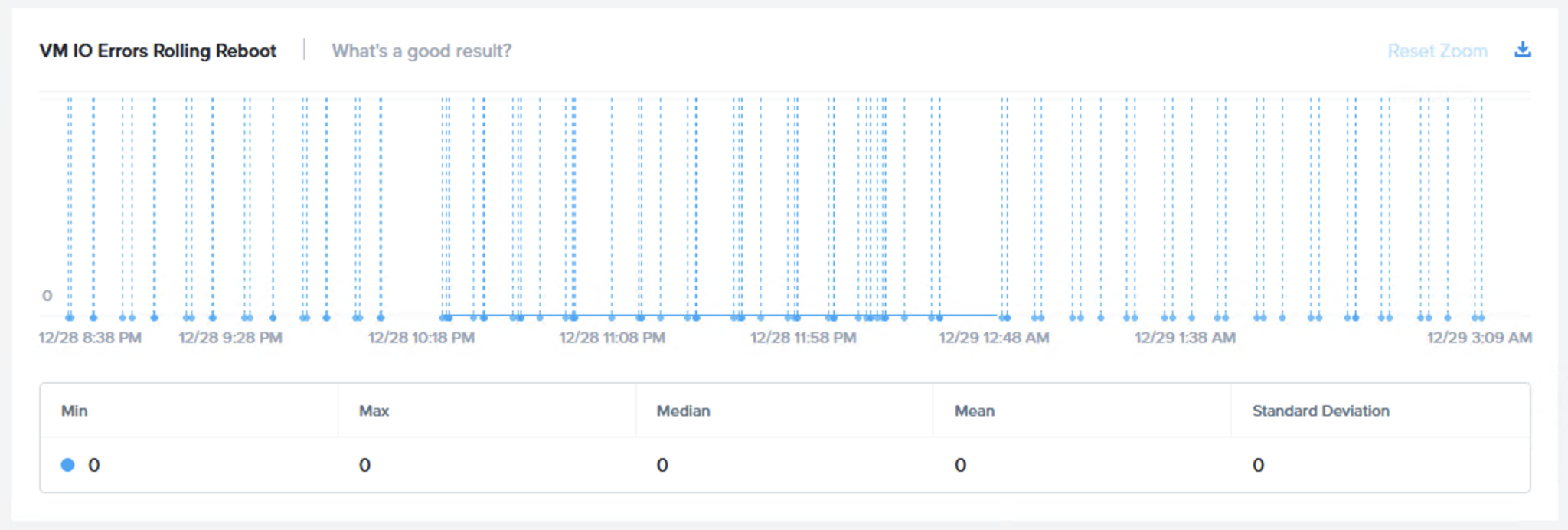
最後に、パワーサイクルのフェーズでは、帯域外管理(IPMI/iDRACなど)を介してノードの電源を不自然にオフにします。下の図は、VMの可用性が維持され、I/Oエラーが発生しなかった例です。
上記のテストは、デフォルトのPVSCSIタイムアウトが180秒であるESXi上で実行されたにもかかわらず、I/Oタイムアウト設定が30秒であるデフォルトのテストオプションを使用して実行されました。
ESXi 7 Update 1上で動作するNutanix AOS 5.19は、30秒のI/Oタイムアウト設定を使用したプラットフォーム全体の回復力テストのすべてのフェーズで、仮想マシン(の可用性)とI/Oの完全性を維持しました。
テストに失敗した場合はどのように見えますか?
仮想マシンの可用性が期待されるレベルで維持されていない場合(赤い点線で表示されます)、 かつ/あるいは、何らかのI/Oエラーが検出された場合は、障害が発生したことを意味します。
次のチャートはある大手競合製品の例ですが、VMの可用性は維持されているものの、VMに何百ものI/Oエラーが発生していることを示しています。
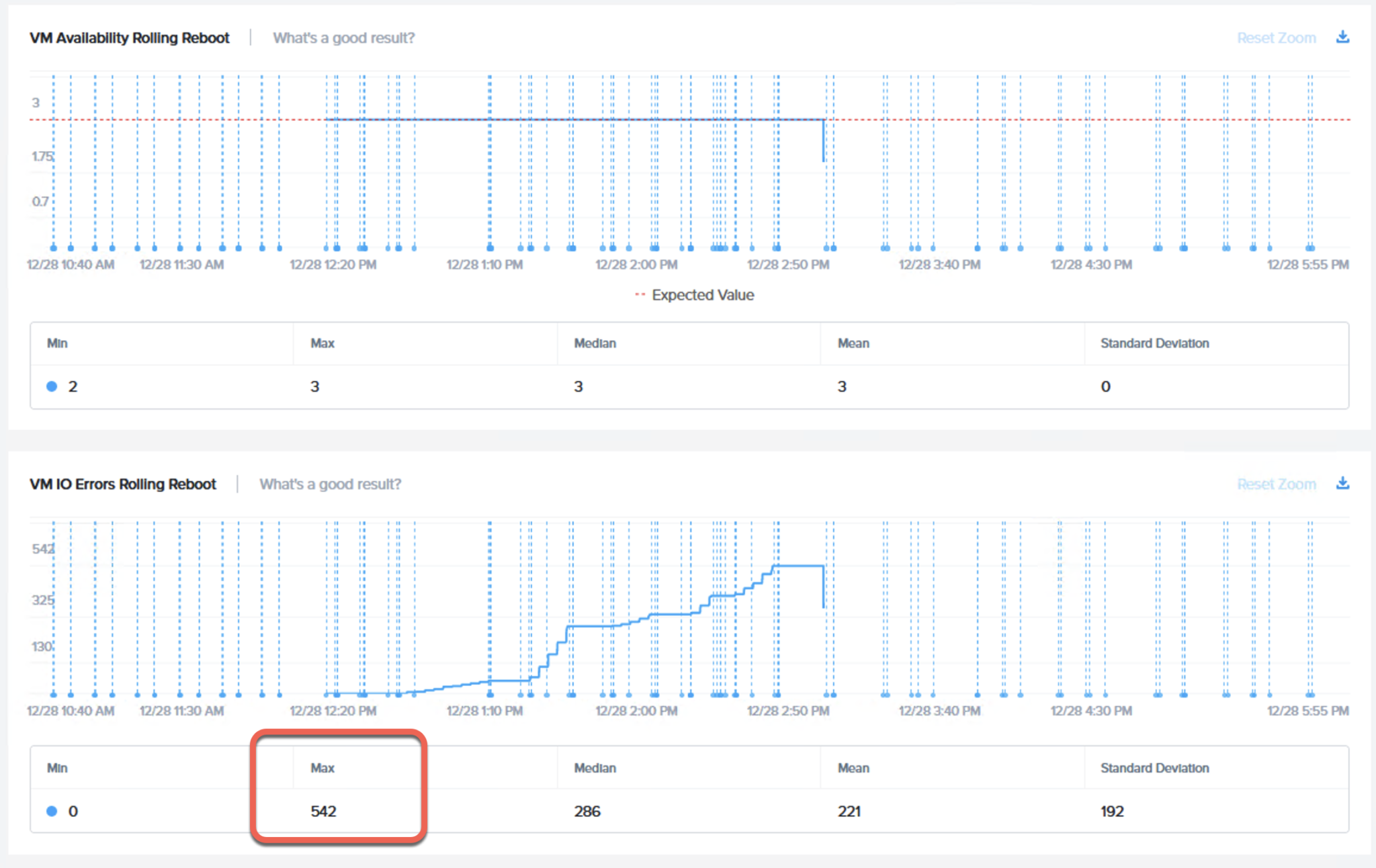
現実の世界において、このような結果は、データロスまたは可用性喪失のいずれかを示しています。アプリケーションパフォーマンスの低下、または最悪の場合、アプリケーションの障害/ダウンタイムでエンドユーザーに影響を与え、HCIプラットフォーム自身にも余計な負荷を与えます(例:バックエンド処理のCPU負荷 および I/O負荷)。
より詳細な結果と比較については、Nutanix AOSとVMware vSAN 7 Update 1を比較したシリーズのパート2をご覧ください。
今後の機能強化は?
現在、以下のようなテスト機能の追加に取り組んでいます。
1. RF3 / FTT3 / RAID 6環境における2ノード障害テスト
2. 1つおよび2つのディスクの障害シナリオ
3. N+1およびN+2の構成におけるノードとドライブの複合故障シナリオ
これ以外の障害シナリオのご要望も承っておりますので、お気軽にお問い合わせください。