

本記事は2021年1月11日にJosh Odgers氏が投稿した記事の翻訳版です。
X-Ray 向けの「Platform Availability, Resiliency & Integrity (プラットフォームの可用性、回復力、そして整合性)」のシナリオをもうすぐ(※原文記載時ママ)リリースできることを喜ばしく思います。
X-Rayにあまり馴染みのない方のためにご紹介しますと、X-Rayは自動化された検証とベンチマーキングのフレームワークのソリューションで、主なハイパーコンバージドインフラソリューションの包括的な360°でのアセスメントを提供します。
「Platform Availability, Resiliency & Integrity」シナリオ(これは現在ではvSphere 7 Update 1 のサポートのためのNutanixの公式なQAプロセスの一部でもあります)はHCIプラットフォームのメンテナンスモードへ入れたり、システムの再起動のような制御下で行われるメンテナンスはもちろん、ノード障害のような状況における仮想マシンのI/Oアクティビティ(可用性/回復力)を維持し、I/Oの整合性(エラーがないこと)を再現することを念頭に設計されています。
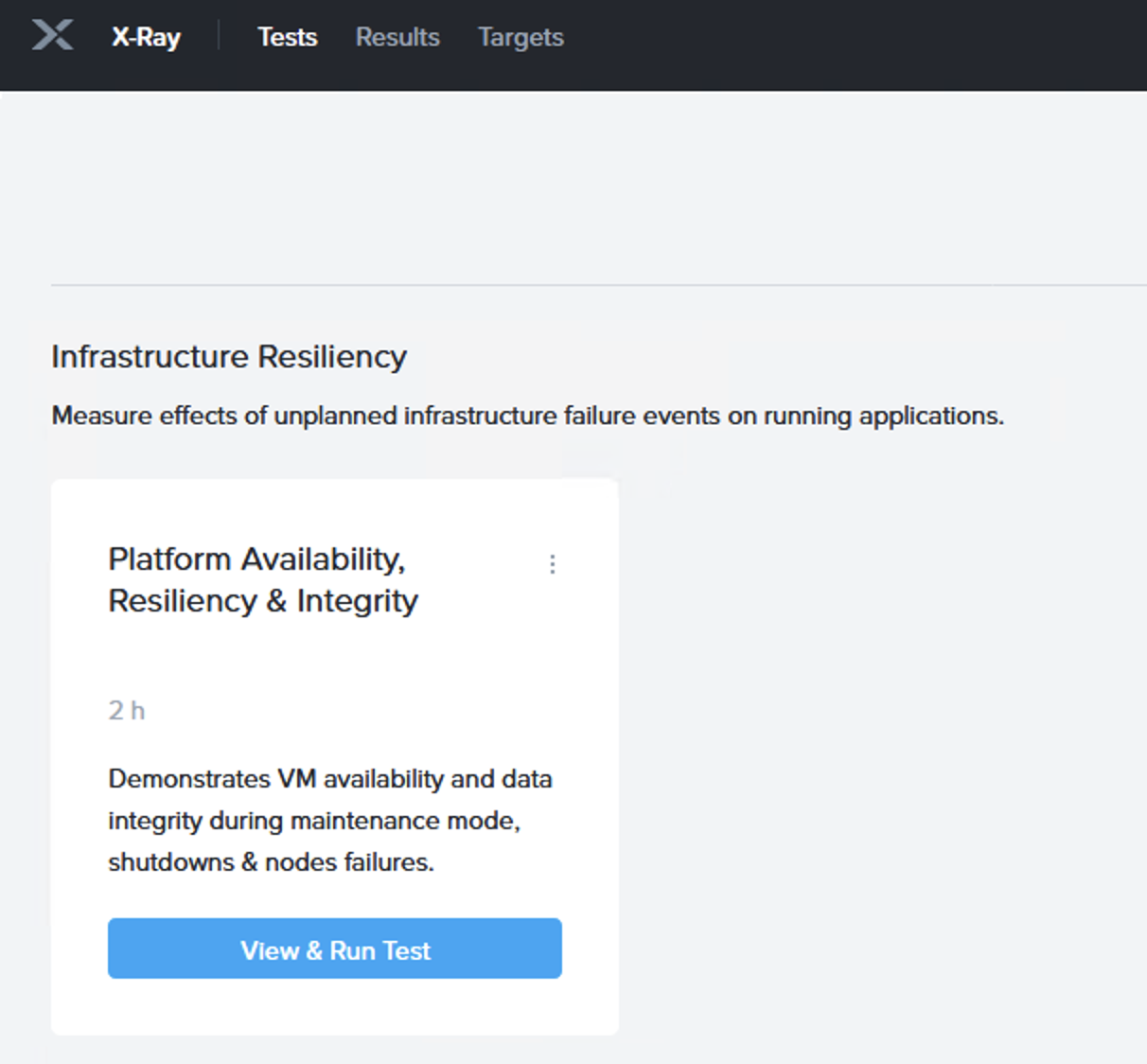
この検証では1台を除いたそれぞれノード上に1台の仮想マシンを展開すると、クラスタ内のノードに応じて自動的にテストをスケールアップします。これはN+1で適切に実際の環境でのサイジングをシミュレーションするためで、それぞれのノード内のフラッシュドライブの数をベースとして適切に目標となるI/Oレベルに合わせるためでもあります。
I/Oレベルをフラッシュドライブ数をベースとして調整していくことは、検証において比較的小さなノードやクラスタに過負荷をかけるだけで、結果として現実的ではない、人為的に生み出される多くのエラーを避けることができます。
それでは検証の内容とそのオプションを見ていきましょう。
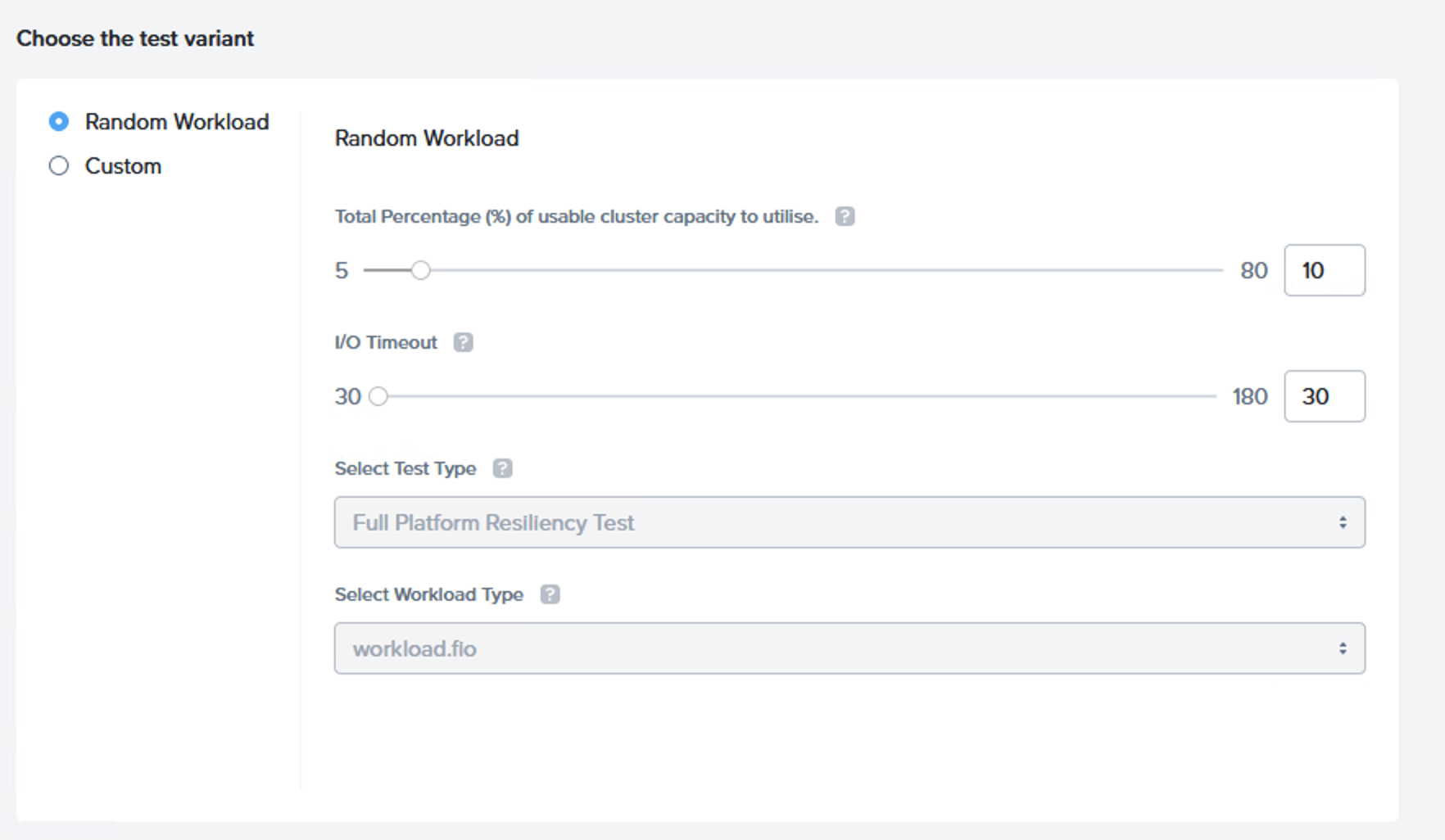
この検証の主な目標は検証自体を大変シンプルで使いやすくすることで、迅速/簡単に概念検証(PoC)、インストール後の運用の確認の一部、そして構成変更後の期間での検証の一部として利用できるようにすることです。
特に手を加える必要もなく、検証は自動的に利用可能なクラスタ/利用可能なストレージキャパシティを検出し、そのキャパシティのうちの10%を検証に利用しますが、これは80%まで増やすこともできます。
次に検証では業界標準のI/Oタイムアウト設定である30秒を用いて、3つのフェーズからなる完全なプラットフォームの回復力の検証を実施します。
フェーズ1: メンテナンスモードのサイクル
このフェーズではクラスタの最初の4ノードのそれぞれは再起動を行う前に順番にメンテナンスモードへ切り替えられていきます。仮想マシンはクラスタ内を動き回りながら、I/Oの実行を継続します。
3ノードのクラスタでは検証は自動的に3ノードで行われます。
フェーズ2: 再起動のサイクル
このフェーズではクラスタ内の最初の4ノードはそれぞれ順番にメンテナンスモードへ切り替えられることなく再起動されていきます。仮想マシンは再起動実施前にノードから退避し、I/Oの実行は継続されるはずです。
フェーズ3: 電源OFFのサイクル
このフェーズではアウトオブバンド管理から電源OFFを行うことでクラスタ内の最初の4ノードのそれぞれが順次ノード障害を起こした場合をシミュレーションしていきます。仮想マシンは電源OFF操作実施前にノードから退避し、この場合もまたI/Oの実行は継続されるはずです。
検証のそれぞれのフェーズを通じて、I/OアクティビティとI/Oエラーは監視されており、別々にレポートが生成されます。
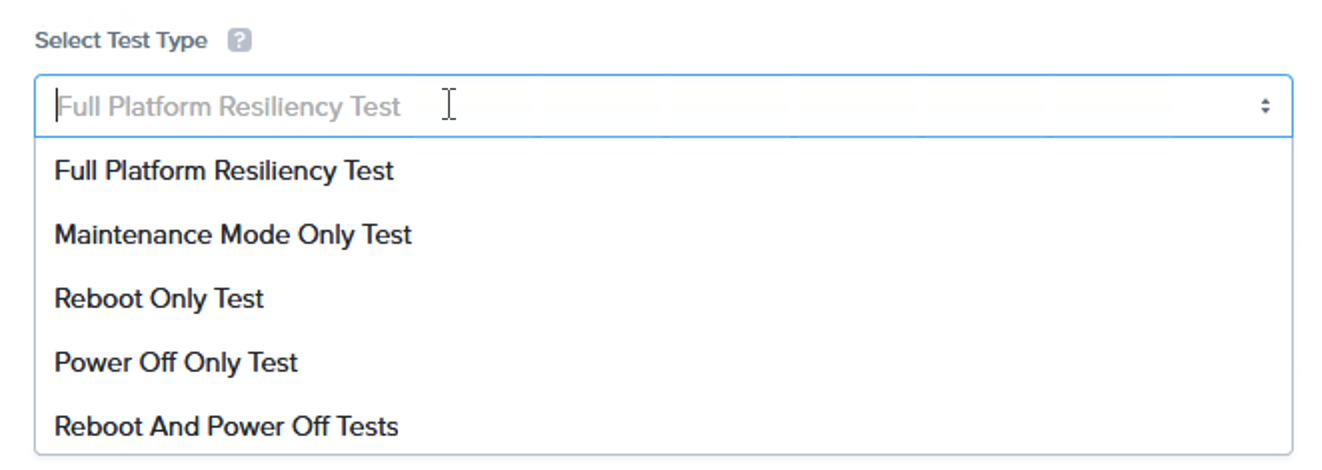
検証ではサブセットとなる検証において「カスタム」の検証の変数を利用して検証を行うためのオプションがあり、これによってそれぞれのフェーズを単独で実行することも、再起動と電源OFFの検証を連結して実施する事もできます。
それぞれの仮想マシンは非常に軽量なFIOの12の仮想ディスク(VMDK/vDisk)にまたがって広がるワークロードを動作させます。
12 個のvDiskという数字はVMware ESXi上で適切に複数のPVSCSIコントローラーに分散されて行われることを保証するために選択されています。これは、vSANのようなプラットフォームではクラスタ全体にオブジェクトを分散させ、最高の可用性と性能を得るられるようにするためです。
Nutanix AOSはもちろん仮想ディスクの数に関係なくインテリジェントに動的にデータをクラスタ全体に分散させます。Nutanix AHVもまたvDiskの数に関係なく最適なデータパスを維持します。これはそれぞれのvDiskがそれぞれ自身で直接ローカルノンストレージコントローラー(CVM)へ直接TCP/IP接続を行うからです。このHCIにフォーカスした設計によって、複数のPVSCSIコントローラーを展開し、コントローラー全体から適切な性能を引き出すために手動でVMDKへのアクセスを分散させるといった複雑さは必要なくなります。
このシナリオはI/Oタイムアウトの設定も標準の「30」から最大の「180」まで変更することができるようになっています。
なぜタイムアウトは標準で30秒なのでしょうか?
これはKVM(これはAHVでも利用されています)のVirtIOドライバーが標準で30秒にタイムアウトを設定しており、一方でvSphereのPVSCSIコントローラーは標準で180秒に設定をしているからです。
ですから、プラットフォームによっては、Nutanix AOSほどに回復力が高くないため、I/Oエラーを回避するのにより長い時間のタイムアウトが必要になる場合があるので、タイムアウトをカスタマイズできるようにするのがベストだと考えました。
それではNutanix AOS 5.19上で行った検証結果を見ていきましょう:
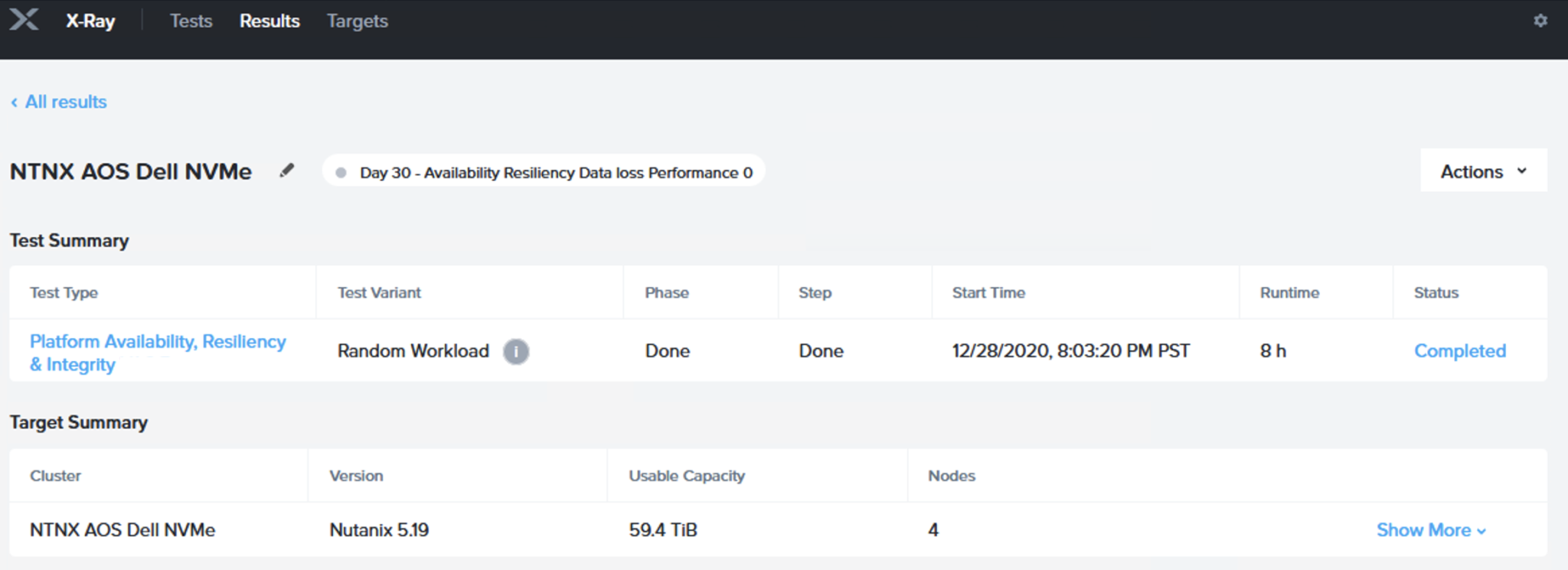
上の図はプラットフォームの可用性、回復力、そして整合性の検証を標準の「ランダムワークロード」という検証変数を利用して実施した検証のサマリです。検証は59.4TBの利用可能なキャパシティのある4ノードクラスタ上で実施されています。これはつまり、5.9TB程度のアクティブなワーキングセットが3つの仮想マシン(それぞれ2TB程度)で利用されたということです。
[Show More (更に詳細)]ボタンをクリックすると、X-Rayは検証時のハイパーバイザー(ソフトウェア)のヴァージョンを含む、CPUタイプ、RAMの総量、ドライブタイプと総数のハードウェアの詳細を表示します。
スクロールダウンしていくと、[Detailed Graphs (詳細なグラフ)]のセクションがあります。
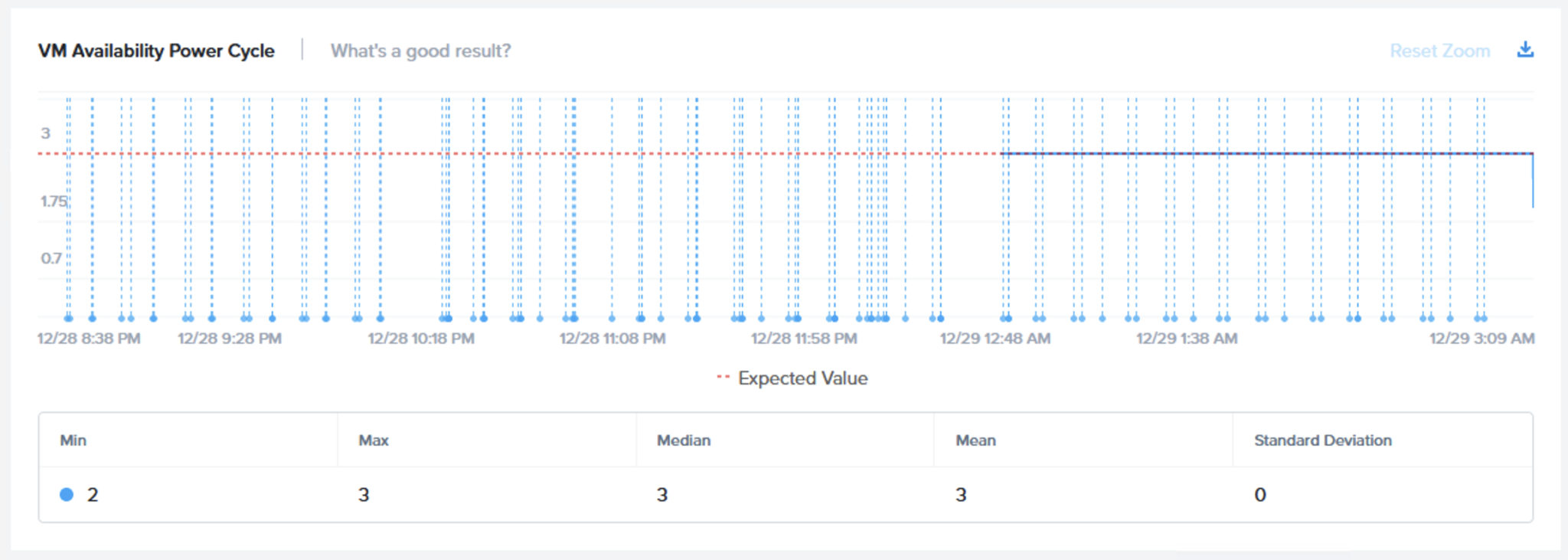
最初のチャートでは[VM Availability Maintenance Mode(仮想マシンの可用性 メンテナンスモード)]のチャートを確認することができます。ここでは継続して3という値が示されており、3台の仮想マシンが検証のメンテナンスモードのフェーズにおいて継続してI/Oを実行しているということを顕しています。
以下の図は3台の仮想マシンがこのフェーズ全体を通じてオンライン(利用可能)でI/Oを実行しているということを示しています。
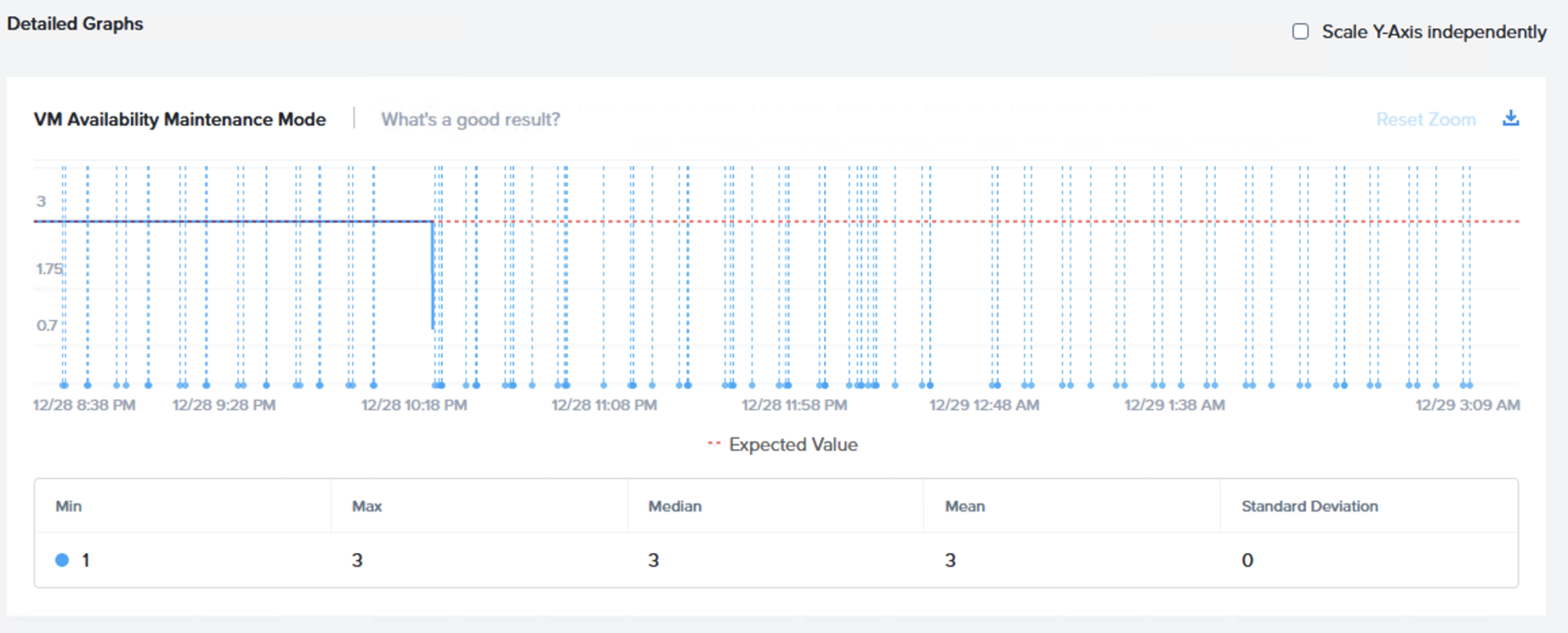
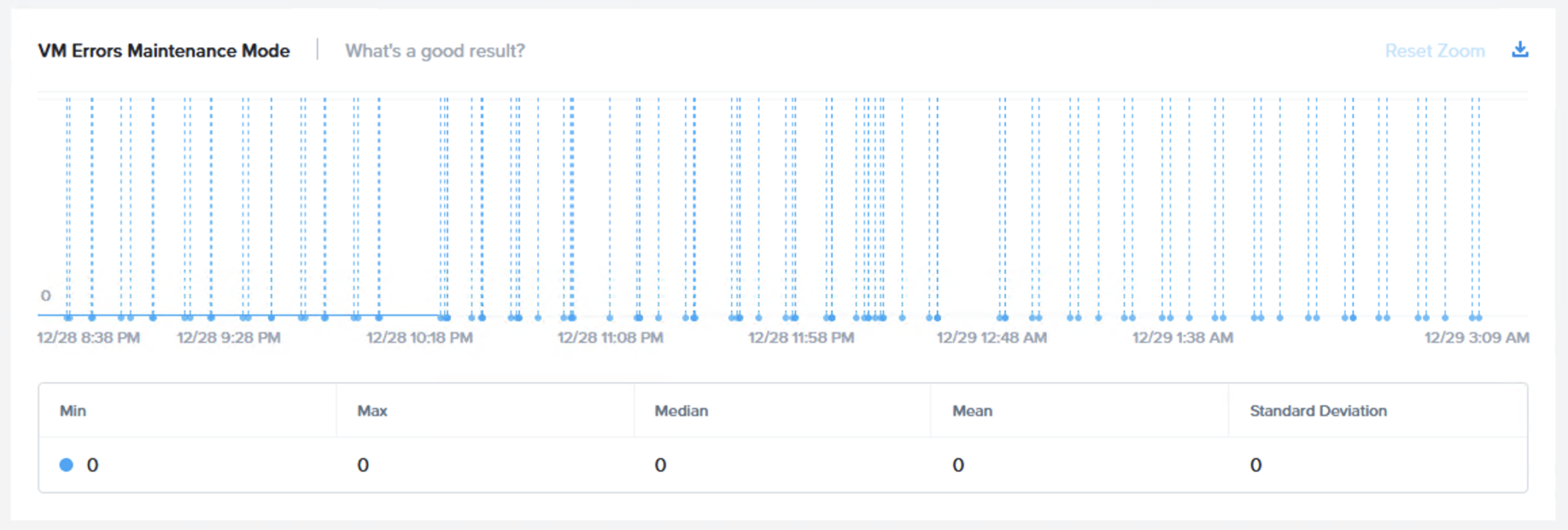
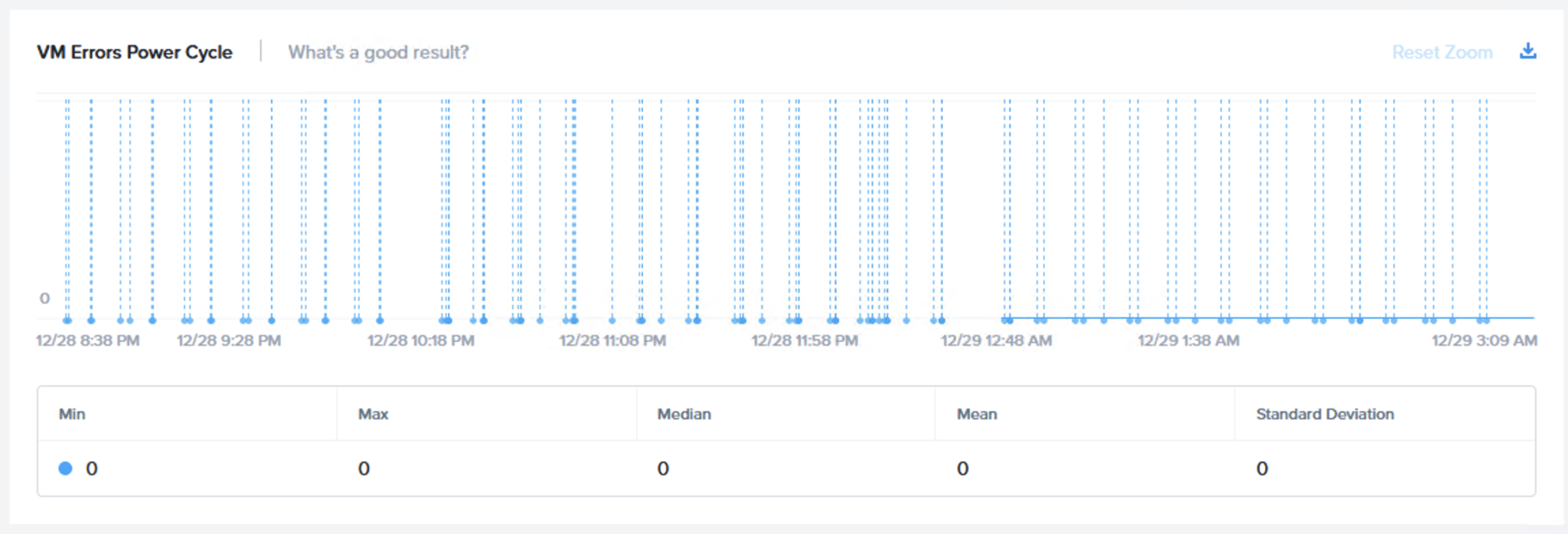
次のグラフ(VM Errors Maintenance Mode)は仮想マシンのI/Oエラー(メンテナンスモード)を示しています。もちろん、期待されるのはエラーなしで、そのとおりにチャートに示されています。
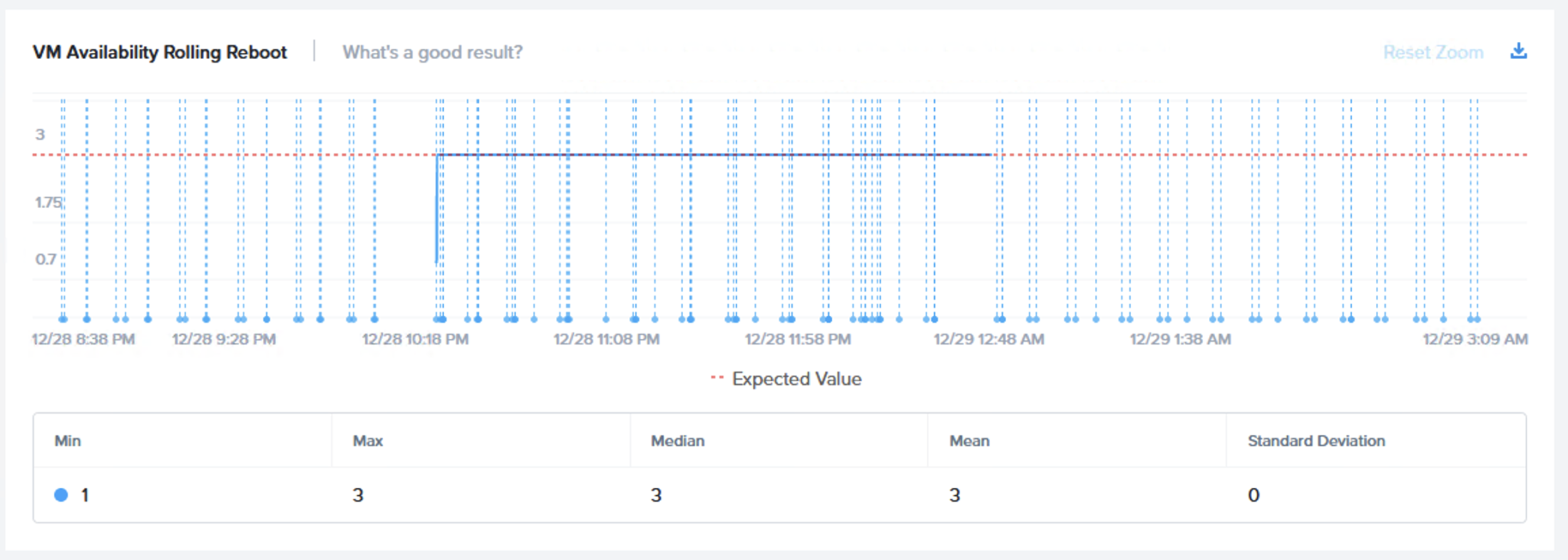
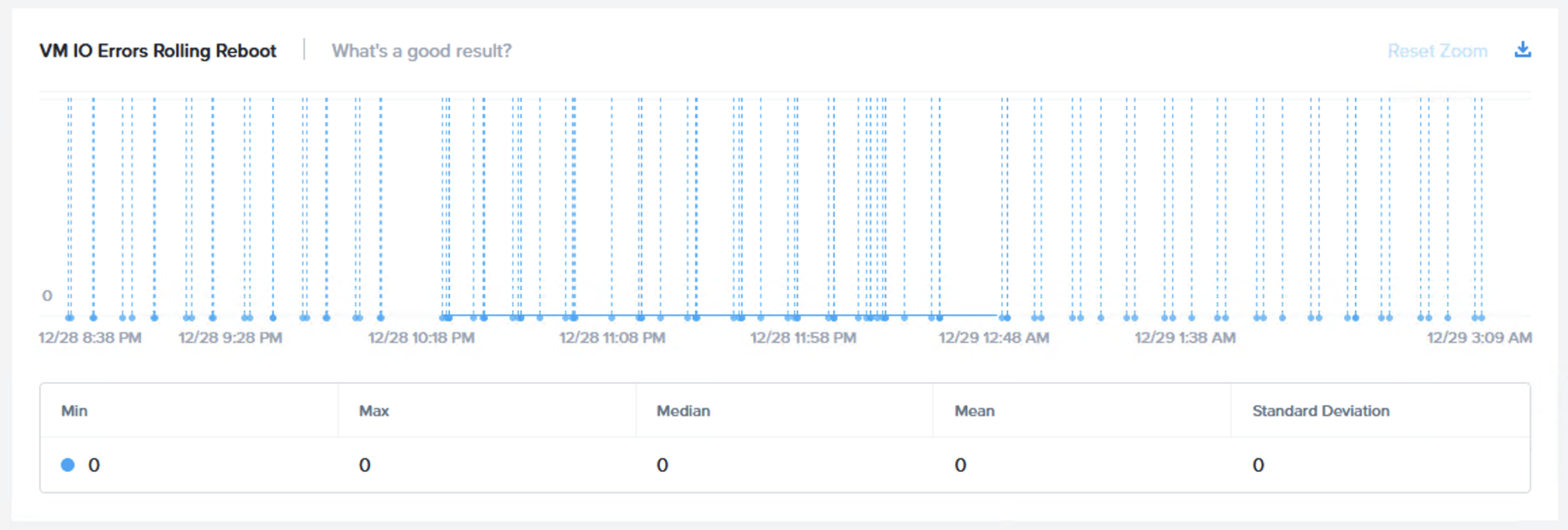
次のフェーズはローリングでの再起動で同じ2つのチャートで仮想マシンの可用性 (ローリング再起動)と仮想マシンのI/Oエラー (ローリング再起動)です。
メンテナンスモードのフェーズと同じく、検証ではノードあたり1台の仮想マシンでI/OアクティビティはI/Oエラーなく検証を通じて維持されることが期待されます。
最後に、電源サイクルのフェーズですが、ここではアウトオブバンド管理(IPMI/iDRACなど)から特段の配慮も行わずに電源をOFFします。以下で仮想マシンの可用性が維持されていることとI/Oエラーが発生していないというサンブルを見ることができます。
上の検証はESXi上で実行されており、PVSCSIのタイムアウトは標準で180秒なのですが、30秒のI/Oタイムアウト設定を含む標準の検証オプションで実行されています。
ESXi 7 Update 1上で動作するNutanix AOS 5.19は30秒のI/Oタイムアウト設定を利用した場合で完全な仮想マシンとI/Oの整合性をプラットフォームの回復力検証のすべてのステージで維持しています。
検証が失敗するとどうなるか?
もしも仮想マシンの可用性が期待されたレベル(赤の破線で表示されています) で維持されない そして/あるいは障害で I/Oエラーが検出された場合はどうでしょう。
以下のチャートは我々のよく出くわす競合でのチャートの例で、仮想マシンの可用性は維持されていますが、仮想マシンは数百ものI/Oエラーに苦しめられています。
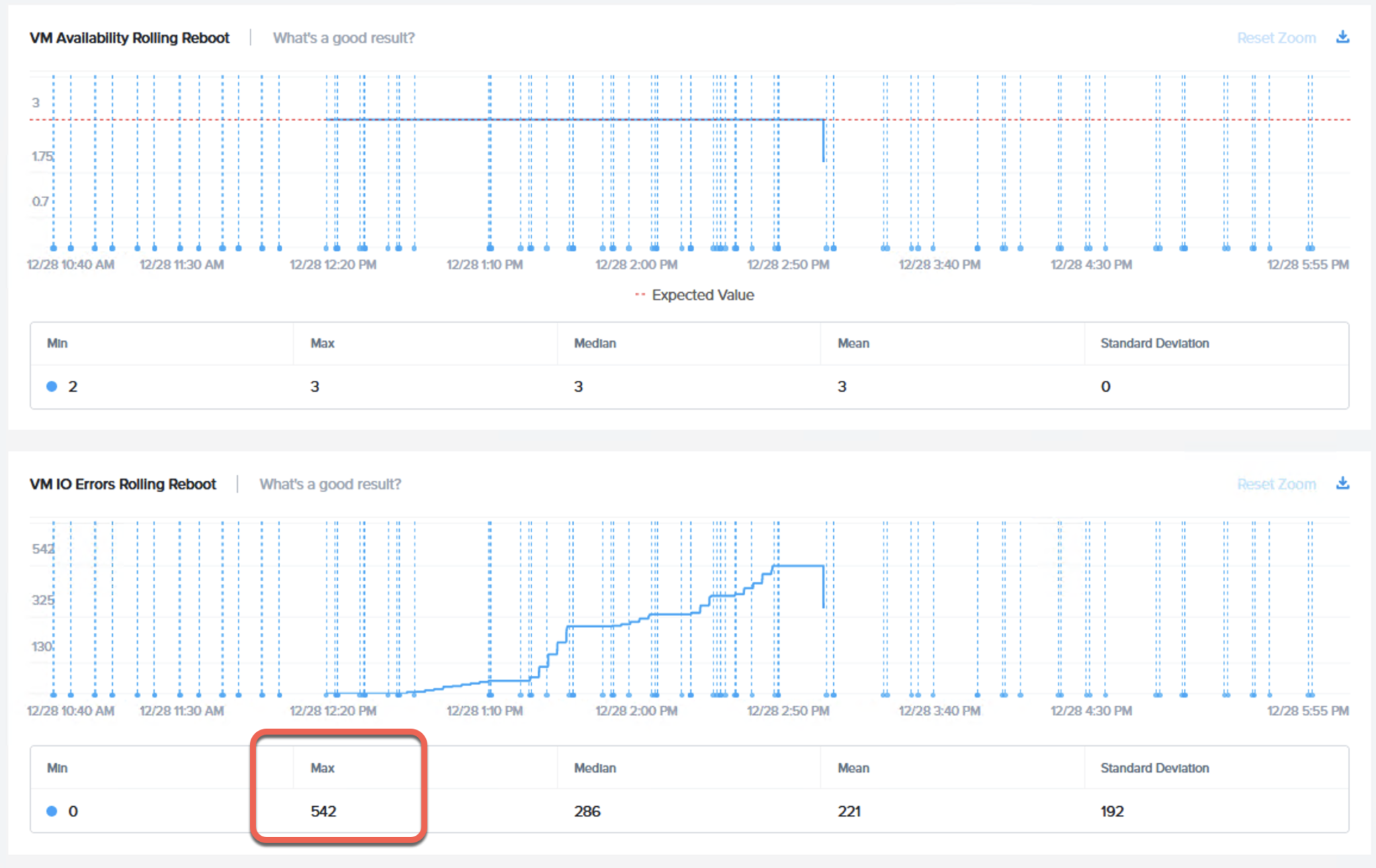
現実の世界ではこうしたタイプの結果はデータが喪失あるいは利用不可になるということを示唆しており、エンドユーザーにとってアプリケーションの性能の低下、更に悪い場合にはアプリケーションの障害/ダウンタイムとして影響を及ぼす上に、HCIプラットフォームに追加で負荷(バックエンドのCPU利用 & I/O負荷)をかけてしまうことになります。
パート2では更に詳細にテスト結果を見てゆき、Nutanix AOSとVMware vSAN 7 Update 1を比較していきたいと思います。