


Nutanix CE よろず相談所が長くなってきた&Nutanix CE 2.0 がリリースされたいい機会なので、こちらに移行したいと思います。
- Community
- International Forums
- 日本語フォーラム (Japanese)
- Nutanix CE 2.0 よろず相談所
Nutanix CE 2.0 よろず相談所
- March 2, 2023
- 90 replies
- 12906 views
This topic has been closed for replies.
90 replies

- Trailblazer
- July 16, 2024
お忙しい中、コメントありがとうございます。色々試したのですが、br0とbr1のブリッジ間でのAHVとCVM通信に支障がきたして、結局このパターンはNGでした。
その後、RHEL VMのKVM(ブリッジではNAT利用で問題回避)を利用して、NestedなNutanix CEの導入までは問題なくいったのですが、頻繁にCVMがダウンしたりでPrism Elementへの接続が不安定で、検証とはいえ実用に耐えない状況で、こちらの方式も諦めました。
現在、手元にESXi8.0のDVD ISOがあったので、評価版でNetstedなNutanix CEを試すところです。ただ、VMC環境のVSANを利用したデータストアは、VMCの物理ESXi上でroot権限で設定変更しないとVMFSフォーマットできないので、別のRHEL VMをNFSサーバとしてデータストア提供して試しています。また、仮想ESXiにvNICを2枚搭載させ、2枚目はRHEL VMをNATルータとして、Nutanix CEのAHVとCVMが外部ネットワークと疎通できるように回避させる予定です。
この手の環境で、Nutanix CEを利用されるケースはニッチかと思いますが、この方式で問題解決したら、また情報共有させていただこうと思います。
- Voyager
- July 16, 2024
お世話になっております。
現在、NutanixCE2.0のインストールを試みておりますが、以下のエラーが発生し、インストールが進みません。
```
ERROR SVM imaging failed with exception: Traceback (most recent call last):
File "/root/phoenix/svm.py", line 673, in image
self.deploy_files_on_cvm(platform_class)
File "/root/phoenix/svm.py", line 309, in deploy_files_on_cvm
shell.shell_cmd(['mount /dev/%s %s' % (self.boot_part, self.tmp)])
File "/root/phoenix/shell.py", line 53, in shell_cmd
raise StandardError(err_msg)
StandardError: Failed command: [mount /dev/None /mnt/tmp] with error: [mount: special device /dev/None does not exist]
out: []
INFO Imaging thread 'svm' failed with reason [None]
FATAL Imaging thread 'svm' failed with reason [None]
```
ストレージ構成は以下の通りとなっております。
```
[root@phoenix ~]# lsscsi
[4:0:0:0] disk ATA HUA723020ALA640 A870 /dev/sda
[5:0:0:0] disk ATA SPCC Solid State 9A0 /dev/sdb
[6:0:0:0] disk ATA CT500MX500SSD1 023 /dev/sdc
[10:0:0:0] cd/dvd ATEN Virtual CDROM YS0J /dev/sr0
[root@phoenix ~]# lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
sdb 8:16 0 477G 0 disk
sr0 11:0 1 5.2G 0 rom /mnt/iso
sdc 8:32 0 465.8G 0 disk
sda 8:0 0 1.8T 0 disk
```
sdaにはData、sdbにはHypervisor、sdcにはCVMをインストールする想定となっております。
また、インストーラーの起動時に自動的にインストール先が指定されており、
自動的に指定された場合は、sdaにはData、sdbにはCVM、sdcにはHypervisorという
構成となり、この構成の場合はエラーが発生せず、インストールが完了します。
情報をお持ちの方がいれば、ご教示いただけると幸いです。
- Adventurer
- July 16, 2024
sda 8:0 0 1.8T 0 disk DATA
sdb 8:16 0 477G 0 disk AHV
sdc 8:32 0 465.8G 0 disk CVM
AHVは一番小さくしなくてはいけないという問題じゃないですかね。
redditでgruftさんが書いているのを見ました。
あと関係ないと思いますがportの順番も見ているそうなのでDATAは一番下に持っていったほうが良いかもしれません。
- Trailblazer
- July 20, 2024
お世話になっております。またもやマニアックな質問を申し訳ありませんが、情報お持ちでしたらよろしくお願いいたします。
トラブル内容:
AHVとCVMが稼働するvlanを、初期状態のvlan1ではなく、vlan1000に変更したい。しかし、実際にvlanを指定したところCVM・AHVに疎通が取れなくなりました。
意図:
自宅のネットワークですが、これまではRTX1200配下の単一セグメント(192.168.50.0/23)のみで運用していました。
これに加え、L3スイッチを追加してNutanix用のネットワークを構築しようとしています。
正直、自宅ネットワークでここまでやるのは過剰かもしれませんが、L3スイッチの設計としては以下のように考えています
VLAN1: ホームネットワーク(192.168.50.0/23)
VLAN1000:Nutanix検証環境:10.254.0.0/24
※VLAN1000配下の機器は日中電源をOFFにする想定。
L3スイッチに様々な検証NWを集約する想定です。
※仕事ではないので、設計は場当たり的です。
この構成で、具体的な設定や注意点についてアドバイスいただけると助かります。
試した手順
①Nutanix Communityを3クラスタでデプロイ。
Communityのインストーラはvlan idを指定できない。
仮にL3スイッチのvlan1(10.254.0.1)をAHV・CVMのデフォルトGWとして設定。
後ほどVlan1000へ移動する作戦。
インターネットに抜けるため、本来のvlan1(192.168.50.0/23)をvlan 150に収容
下記のconfig(抜粋)を投入。各クラスタ1本づつLANケーブルを接続。
>>config
interface port1.0.13-1.0.28
switchport
switchport mode trunk
interface vlan1
ip address 10.254.0.1/24
interface vlan150
ip address 192.168.51.2/23
<<
②LACP設定
Network→vs0のuplink設定を変更しact-actにする。
全クラスタローリングアップデートしたことを確認しスイッチにLACP設定を投入
AHV/CVMの疎通を確認。
>>config
interface port1.0.13-1.0.16
switchport
switchport mode trunk
channel-group 2 mode passive
lacp timeout short
interface port1.0.17-1.0.20
switchport
switchport mode trunk
channel-group 10 mode passive
lacp timeout short
interface port1.0.21-1.0.24
switchport
switchport mode trunk
channel-group 1 mode passive
lacp timeout short
interface port1.0.25-1.0.28
switchport
switchport mode trunk
<<
③Vlan id 変更
https://blog.ntnx.jp/entry/2020/11/20/014320 様を参考に
cluster stopしてから
AHV上でovs-vsctl set port br0 tag=1000
CVM上でchange_cvm_vlan 1000を実行
④L3スイッチ 設定変更
L3スイッチと疎通が取れなくなるため、vlan1のアドレスを消去
>>Config
interface vlan1
no ip address
<<
vlan1000にアドレスを付与
>>Config
interface vlan1000
ip address 10.254.0.1/24
«
結果:
④の時点で10.254.0.0/24がvlan1→1000に移動したと思っており、CVM・AHVと
疎通できる想定でしたが、残念ながらCVM/AHV→L3スイッチ(10.254.0.1)への
疎通が成立しません。
楽しく一日溶かしてしまいました(笑)どなたかナレッジお持ちでしたら、ヒントだけでもいただけますと幸甚です。おそらく、Communityはその辺いじらずにvlan1で運用せよ。がベストプラクティスな気はしております...
- Trailblazer
- July 20, 2024
keroro9です。半分自己解決しましたので、書き込みます。
調査していたところ、L3スイッチの設定が抜けているようようでした。
利用しているスイッチ(X510)のマニュアル中
「各種コマンドでLACPチャンネルグループを指定するときは、「poX」(XはLACPチャンネルグループ番号)という形式の名前を指定してください。」という記載があり、LACPを組んだ仮想IFでさらにTrunkの設定を入れなければならないようです。
仮で構築したPrism上で仮想マシンを作成し、vlan1001を当てたNICを接続したところ、全く疎通せず。これはスイッチが怪しいということでマニュアルを読んでいたところ...でした。Configが似ているCiscoのL2スイッチのconfigを適当にコピーしたのが敗因です。(そのconfigも間違っているかも)
LACPで束ねた仮想IFに対して入れるべき設定はおそらく下記のとおりと思われます。
!
interface po1-2,po10
switchport
switchport mode trunk
switchport trunk allowed vlan all
switchport trunk native vlan none
!
今日はだいぶ遅くなってしまったので、明日クラスタを壊す前提で試してみる予定です。
- Trailblazer
- July 20, 2024
keroro9です。
無事、問題解決しましたので報告します。
やはり原因は、L3スイッチに適切な設定が入っていないことでした。
アライドテレシス X510系のL3スイッチでわざわざ1GインターフェースをLACPし、
かつ、CVM/AHVの稼働するVlanを指定する際に必要なconfigは下記のとおりです。
※タイプミスでchannel-groupが10になっていますがこのままにしています。
! 一台目
interface port1.0.13-1.0.16
switchport
switchport mode trunk
switchport trunk allowed vlan add 2-200,1000-1009,1254
channel-group 2 mode passive
lacp timeout short
! 二台目
interface port1.0.17-1.0.20
switchport
switchport mode trunk
switchport trunk allowed vlan add 2-200,1000-1009,1254
channel-group 10 mode passive
lacp timeout short
! 三台目
interface port1.0.21-1.0.24
switchport
switchport mode trunk
switchport trunk allowed vlan add 2-200,1000-1009,1254
channel-group 1 mode passive
lacp timeout short
! PortChannel設定
interface po1-2,po10
switchport
switchport mode trunk
switchport trunk allowed vlan add 2-200,1000-1009,1254
!
- Trailblazer
- July 22, 2024
先ほど投稿したのですが、反映されておらず再投稿させていただきます。
Nestedな環境でNutanix CE導入、3ノードのクラスタ環境構築まで完了したのですが、
Prism Centralの導入に苦戦しております。
原因を調査したところ、qcow2からimgへの変換処理のタスクが、デフォルト30分のため時間が足らずにエラーとなっているところまで確認できています。(genesis.outログで確認済み)
海外のコミュニティ投稿で、デフォルト30分を変更して解決したとの記述を見つけましたが、肝心な設定箇所の記述がなく、色々調べていますが未だ見つからず、何か情報をお持ちの方はいらっしゃらないでしょうか?
- Adventurer
- July 22, 2024
お探しのものかわかりませんが
タイムアウトのこと書いてある記事です。
https://liberation-of-se-like-slaves.net/prism-central-create/
- Trailblazer
- July 22, 2024
早速のレスありがとうございます!
こちらの記事は私も認識していて、Neverに設定変更していたのですが、
恐らくWebUIのセッションタイムアウト値のようでした。
再度、CVM3台の初期化デプロイを実行中で、引き続き調査してみようと思います。
問題解決しましたら、恐らくNestedな環境でNutanix CEを利用している方は、
同事象に遭遇しやすいので、情報共有させていただこうと思います。
- Adventurer
- July 22, 2024
VMware workstation 17 proでPrism Centralインストールしてみました。
シングルクラスターですが処理時間は約38分でした。
19:41 deploy start
20:19 deploy end
https://note.com/myaoumyaou/n/n2c05a741c753
↑参考までに記録を残しました。
kfujita0731さん3ノードということですがデプロイ方法(1node or 3node)、
ESXi上の3台のcpu/memory/diskスペックはどれくらいでしょうか。
根本解決で無いですが、cpuを盛れば30分以内で抜けられるのではないかなと思っております。
私の環境でPC2台128GBメモリがあるのでVMware workstationで3ノードクラスタ作ること可能です。
今はまだインストールとかで遊んでいる段階なのでこれ確認してくれというのあれば情報提供可能です。
- Trailblazer
- July 23, 2024
ディスクI/O周りのチューニング(物理環境はVMC環境のVSANデータストアを利用。仮想マシンストレージポリシー設定変更にて性能向上)、及び、3ノードでなくシングルノード構成のクラスタ環境に変更して、ようやくqcow2からimgへの変換処理のタイムアウト値をクリアーし、何とかPrism Central導入までこぎつけました。
ただ、選択可能な2バージョンのPrism Central、いずれも何回かデプロイが失敗(Tarball Extraction以外の後続タスクでもエラー終了)し、最終的に互換性のない最新バージョンを選択して導入に成功しました。
Nested環境でのCE導入がそもそもの原因かと思いますが、
1クリックデプロイといいながら、こんなに不安定で導入に苦戦するものなのでしょうか・・・
- Trailblazer
- July 24, 2024
コメントありがとうございます!
>kfujita0731さん3ノードということですがデプロイ方法(1node or 3node)、
>ESXi上の3台のcpu/memory/diskスペックはどれくらいでしょうか。
>根本解決で無いですが、cpuを盛れば30分以内で抜けられるのではないかなと思っております。
私の環境は、VMC環境の潤沢なリソースを利用したNestedな環境でのNutanix CE導入となります。
CVM/AHV各々、最終的なデプロイ時には64core/64GBmem/100GB,1.5TB,1.5TBという仮想マシンの構成のため、スペック自体は問題ないと考えております。
ただ、仮想マシンのvHDD1,2,3の大元のストレージは、VMC環境のVSANデータストアとなり、
また、VMCの諸々制約から、RHEL仮想マシンをNFSサーバとして10TBの領域をNFSデータストアとして提供し、ESXi仮想マシンにマウントさせています。
ESXi仮想マシンの仮想マシン(Nested)としてNutanix CEをデプロイさせています。
その関係で、DiskI/O周りが複数階層構成でのオーバーヘッドで性能が出ていないため、qcow2からimgへの変換処理がデフォルト30分のタイムアウトまで間に合わずエラーとなっていました。
直前のコメントにも記載させていただきましたが、VSANの仮想マシンストレージポリシーを耐障害性を犠牲にして性能向上させるポリシーに変更し、3Node構成からシンプルに1Nodeクラスタ構成にして、初めて導入に成功しました。
ただ、導入成功したのは互換性がない最新のPrism Centralではありましたが・・
- Trailblazer
- July 24, 2024
お世話になります。
下記同じ構成を持つサーバー3台でクラスタを作成して3カ月間ほど正常稼働しましたが、
2週間前からノード#3にてディスク1つがオフラインになったアラートが発生し、
同じタイプのSSDで交換を実施しました。実施後、ディスクが正常に認識されていました。
■物理サーバー構成
・サーバー:DELLPowerEdgeR620
・RIADコントローラ:PERC H710 Mini
・ディスク情報:
①sdc SSD 256GB(Micron1100 2.5インチ) (AHVブートディスク)
②sda SSD 1TB (Crucial MX500 2.5インチ) (CVMブートディスク)
③sdb SSD 1TB (Crucial MX500 2.5インチ) (データ)
④sdb SSD 1TB (Crucial MX500 2.5インチ) (データ)
昨日Moveを利用して一台の仮想マシンをNutanixCEクラスタに移行する途中に、再びディスクオフライン
アラートが発生し、ノード#2とノード#3のディスクがすべてオフラインになりました。
知識不足で申し訳ございませんが、ディスクがオフラインになる要素をご教授いただける幸いです。
- Adventurer
- August 5, 2024
お世話になっております。
Nutanix CE 2.0のPrism Central(pc.2022.6.0.11)デプロイが失敗してしまい質問させてください。
■環境:物理PCノード
CPU:i7-10700
AHV:64GB SSD
CVM:1TB NVMe
DATA:2TB SSD
NIC:オンボード I-219V 1Gbps
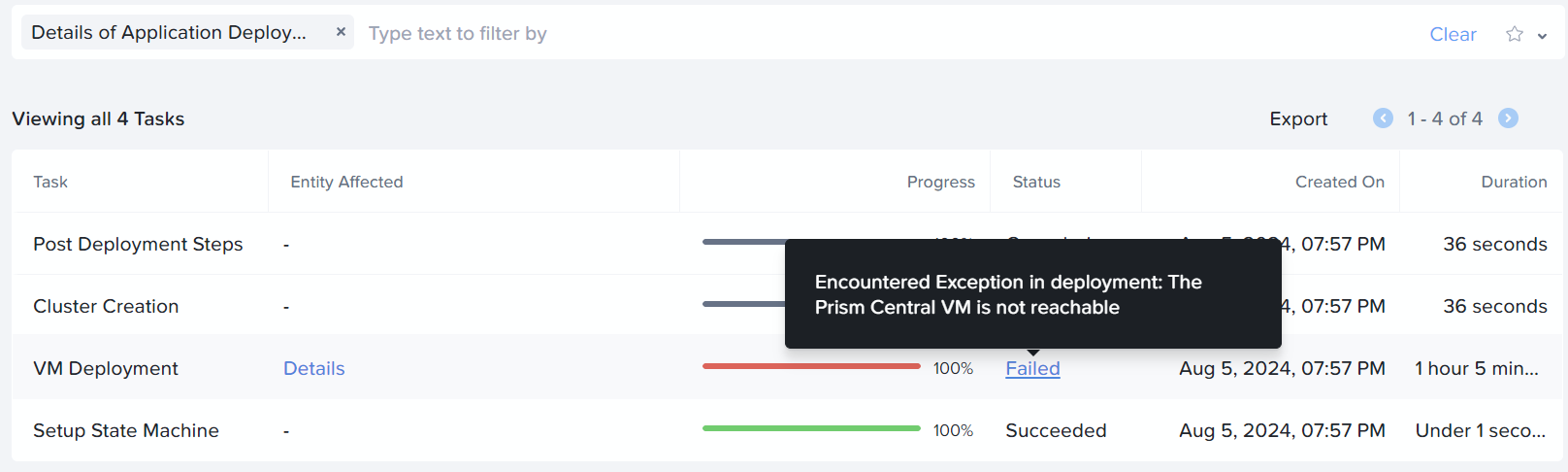
Prismのタスクには、次のエラーが記録されています。
"message": "Encountered Exception in deployment: The Prism Central VM is not reachable",
https://portal.nutanix.com/page/documents/kbs/details?targetId=kA00e000000LLeBCAW
エラー違いますが、こちらのURLを参考にVlanIDを変えてみたり色々試しているのですが上記エラー変わらず。
Prism CentralのネットワークはAHV、CVMと同じアドレス帯にしています。
ちなみにVMware Workstation 17 proのNestedで試すとすんなりPrism Centralが入るので物理はネットワークで対応必要なのかと思いましたが、このエラーで調べてもナレッジが出てこず
初歩的なところで失敗しているという気もしますが何かわかればご教授いただきたいです。
nutanix@NTNX-9733548d-A-CVM:192.168.0.21:~$ ecli
<ergon> task.list
Task UUID Parent Task UUID Component Sequence-id Type Status
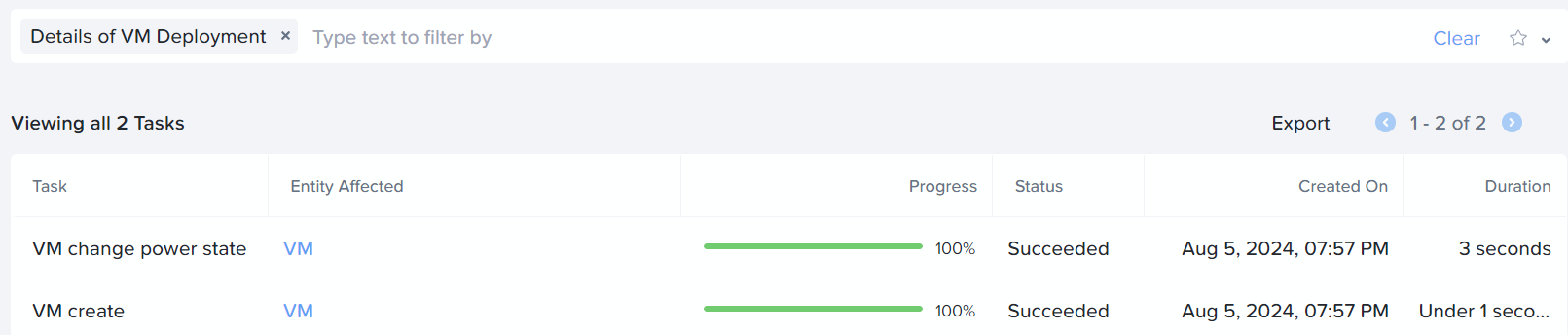
7c0ebdaf-d672-4d53-bc2f-525209d6dd2f a87b05a5-7c2b-4ed4-a5ad-3b41de421b72 Acropolis 7 kVmSetPowerState kSucceeded
b7ceefab-720b-541b-82da-f71696a0056d anduril 2 VmSetPowerState kSucceeded
a87b05a5-7c2b-4ed4-a5ad-3b41de421b72 e0641eb9-ed63-40f5-55c7-2583369fa901 Uhura 2 VmChangePowerState kSucceeded
cdf43c57-64e2-472d-868c-6fed2a253fa7 3b752413-2815-4684-bce4-16e6f5c20442 Acropolis 6 kVmCreate kSucceeded
e53fdb33-c7d6-5076-891d-10ad684f91d3 anduril 1 VmCreate kSucceeded
3b752413-2815-4684-bce4-16e6f5c20442 e0641eb9-ed63-40f5-55c7-2583369fa901 Uhura 1 VmCreate kSucceeded
e0fbcae9-8c81-48a5-76f2-709741b4617e 863fb2d3-ece6-4476-592e-afe7e8dce225 kCluster 4 Post Deployment Steps kAborted
3c00ad72-d17a-4a58-71ee-909b77094c92 863fb2d3-ece6-4476-592e-afe7e8dce225 kCluster 3 Cluster Creation kAborted
e0641eb9-ed63-40f5-55c7-2583369fa901 863fb2d3-ece6-4476-592e-afe7e8dce225 kCluster 2 VM Deployment kFailed
7f1bc18a-d6ce-460c-61c0-4d01852c58b4 863fb2d3-ece6-4476-592e-afe7e8dce225 kCluster 1 Setup State Machine kSucceeded
863fb2d3-ece6-4476-592e-afe7e8dce225 f125a21d-65ff-4e00-4202-da2f3bd09cb0 infra 3 AppDeployment kFailed
62e1fc09-6064-4fbc-5398-297ad3163275 f125a21d-65ff-4e00-4202-da2f3bd09cb0 infra 2 Tarball Extraction kSucceeded
f125a21d-65ff-4e00-4202-da2f3bd09cb0 3520d13e-91ff-445c-770f-9cff272fb59c infra 1 Prism Central Deployment kFailed
ea37f864-cf5a-40e6-4ff6-99e2efebe297 3520d13e-91ff-445c-770f-9cff272fb59c cluster_config 2 kDownload kSucceeded
3520d13e-91ff-445c-770f-9cff272fb59c cluster_config 1 kPrismCentralDeploymentRequest kFailed
69127429-8945-4a67-ae8f-44a30d129892 Acropolis 5 kNetworkCreate kSucceeded
3a6e3b0d-d0d3-4fe5-8e84-e3e67714945a Acropolis 4 kHandleRf1VmAfterAosMaintenance kSucceeded
a69ba2ce-23c8-48a9-b76e-dc2ee180da44 Acropolis 3 kHostRestoreVmLocality kSucceeded
1e386c37-d20b-4435-bc96-690e70cd1fb5 Acropolis 2 kHostSwapAttach kSucceeded
68bed9c3-04c2-4605-98e0-44c7312422ef Acropolis 1 kHostRestoreVmLocality kSucceeded
<ergon>
<ergon> task.get e0641eb9-ed63-40f5-55c7-2583369fa901
{
"canceled": false,
"cluster_uuid": "00061eed-437e-28eb-1204-a4bb6de3290c",
"complete_time_usecs": "2024-08-05T12:02:32.944891Z",
"component": "kCluster",
"create_time_usecs": "2024-08-05T10:57:18.380217Z",
"deleted": false,
"disable_auto_progress_update": true,
"display_name": "VM Deployment",
"ext_id": "ZXJnb24=:e0641eb9-ed63-40f5-55c7-2583369fa901",
"internal_task": false,
"last_updated_time_usecs": "2024-08-05T12:02:32.944890Z",
"local_root_task_uuid": "3520d13e-91ff-445c-770f-9cff272fb59c",
"logical_timestamp": 5,
"message": "Encountered Exception in deployment: The Prism Central VM is not reachable",
"operation_type": "VM Deployment",
"parent_task_uuid": "863fb2d3-ece6-4476-592e-afe7e8dce225",
"percentage_complete": 100,
"requested_state_transition": "kNone",
"response": {
"error_detail": "Encountered Exception in deployment: The Prism Central VM is not reachable"
},
- Adventurer
- August 6, 2024
genesisのログでエラーが吐いているのは確認できました。
ネットワーク系の問題なんだろうなという認識は変わらずです。
https://zenn.dev/myaoumyaou/scraps/13b6dea6a11c05
■ネットワーク
ahv 192.168.0.20
cvm 192.168.0.21
cluster virtual ip 192.168.0.22
prism central 192.168.0.23
subnet 255.255.255.0
default gateway 192.168.0.1
vlan 10
Enter your E-mail address. We'll send you an e-mail with instructions to reset your password.