

Nutanix CE よろず相談所が長くなってきた&Nutanix CE 2.0 がリリースされたいい機会なので、こちらに移行したいと思います。
- Community
- International Forums
- 日本語フォーラム (Japanese)
- Nutanix CE 2.0 よろず相談所
Nutanix CE 2.0 よろず相談所
- March 2, 2023
- 90 replies
- 12906 views
This topic has been closed for replies.
90 replies
 +9
+9- Author
- Nutanix Employee
- March 2, 2023
CE 2.0について取り急ぎ簡単にブログにまとめましたのでご参考まで。
[2023令和最新版]Nutanix Community Edition 2.0
https://smzklab.net/2023/03/nutanix-ce2-lauched.html
+9- Author
- Nutanix Employee
- March 15, 2023
英語版のフォーラムで話題になっていた問題の再現&解決ができたのでブログ書きました。
ESXi上でマルチノードクラスタを作りたい方はご注意ください。
CE 2.0 Nested on ESXiによるマルチノードクラスタ作成に失敗する件の原因と回避方法
https://smzklab.net/2023/03/ce-2-0-nested-on-esxi-multi-node-issue.html
+9- Author
- Nutanix Employee
- March 19, 2023
書きました。CE 2.0でUSBメモリやAHCI SATAを使ってる方は要注意。
Nutanix CE 2.0のAHVをアプデしたら起動しなくなった場合の対処法
https://smzklab.net/2023/03/nutanix-ce-20-how-to-fix-ahv-after-upgrade.html
+9- Author
- Nutanix Employee
- March 28, 2023
Nutanix CEの動作実績情報を集めるためのコミュニティHCLを作成しました。
CEのインストールを検討中の方は、HW購入時のご参考に。
CEのインストールに成功した方は投稿ご協力お願い致します!
(※Nutanixの公式の取り組みではありません)
Nutanix CE Community HCL
https://github.com/smzksts/NutanixCE-Community-HCL
- Voyager
- March 31, 2023
Nutanix CEを省スペースPCで構築しようとしていますが・・・
どうもSSDが足らないというエラーにぶち当たっています
2023-03-31 23:16:13,652Z ERROR MainThread cluster:923 Cannot create one node backup cluster as not enough boot ssds are present to facilitate backup on this cluster Available no of boot ssds is 1 2023-03-31 23:16:13,652Z ERROR MainThread cluster:3106 Operation failed
qiitaで作業ログ的なものを記載しているので、御助力願えないでしょうか。
https://qiita.com/strat/items/aeb309b687e21bf5f288
+9- Author
- Nutanix Employee
- April 1, 2023
Qiita拝見しました。
cluster -s 192.168.11.171 create
を
cluster -s 192.168.11.171 --redundancy_factor=1 create
にしてみてください。
Nutanix CEでは1, 3, 4ノード構成に対応していますが、Nutanixのアーキテクチャは本来複数ノードにまたがってデータを多重化するものであるため、1ノードの場合データの多重化ができません(※商用版だとエッジ環境向けや小規模バックアップ向けに1ノード内でデータを2重化する構成も存在するのですが、より多い本数のディスクが必要です)。
そのため、CEでの1ノード構成の場合にはクラスタ作成時に「データは多重化しない」と明示的に指定するために--redundancy_factor=1というオプションを指定する必要があります。必然的に冗長性が無い状態となりますので、大事なデータは外部にバックアップを取っておくようにしてください。
ついでにQiitaに書かれていた疑問点にもお答えしておくと
[C](CVM)がHot TIer, [D](Data)がCold Tierという理解でOKです。そのため、[C]はSSD必須ですが、[D]はHDDでも大丈夫です。ただしHot/Cold Tierという概念は速度の異なるディスク向けに作られた仕組みなので、仮に[C]と[D]が同タイプのSSD同士だとHot/Cold Tierという階層の使い分けは行われなくなります。いずれにせよTier間のデータの移動は自動で行われるのであまり意識する必要はありませんが…。
また、2台構成で構築予定と書かれていたのですが、↑に書いた通り2ノードでのクラスタは組めないので、2ノード縛りであれば1ノードでそれぞれ作成して、リモートレプリケーション(Protection Domainのリモートサイト)でディザスタリカバリの実験をするのがおススメです。
- Adventurer
- April 27, 2023
シングルノードクラスタで一度構築できていた環境を作り直している過程(ISOからAHVインストール・再起動をしてクラスターの作成・確認をする段階)で下記エラーに遭遇しました。これまで正常にこのハードウェアで動作していたことからその線の可能性はちょっと考えづらく、CVMの構築をやり直すことになるのかなと推測していますが…
nutanix@NTNX-d0ef5e0a-A-CVM:172.30.202.3:~$ cluster -s 172.30.202.4 --redundancy_factor=1 create
2023-04-27 13:06:41,152Z INFO MainThread cluster:2943 Executing action create on SVMs 172.30.202.4
2023-04-27 13:06:44,191Z CRITICAL MainThread cluster:1001 Could not discover all nodes specified. Please make sure that the SVMs from which you wish to create the cluster are not already part of another cluster. Undiscovered ips : 172.30.202.4- CVM(172.30.202.4)内からゲートウェイ(172.30.202.1)・1.1.1.1へのpingは通ります。
- genesis stop && genesis start を実行しても結果は変わらず。
- インストーラーの再実行やAHV上でfirstbootフラグを立て直しても同様。
環境は以下の通りです。
- AHV(ホスト): 172.30.202.2/24
- DHCP/DNSサーバー(インストール時に入力): 172.30.202.1
- ハードウェア: ThinkStation P920
- CPU: Xeon Gold 5218 * 1
- Mem: 256GB (Optane DCPMM128GB*2をメモリーモードで使用、キャッシュは16*4)
- freeコマンドで見たCVMへのメモリ割り当て量は20GB
- CVMのfirstboot.logを見るとauditでFailしている個所があるので増やしてみるのは一手なのか…?
- freeコマンドで見たCVMへのメモリ割り当て量は20GB
- ストレージ:
- AHV → Optane SSD 800P 118GB
- CVMインストール領域として指定 → Samsung PM963 1.92TB、Optane SSD 900P 280GB
- データ領域として指定 → SATA SSD(P920のSATAスロットに直差し) 1TB*2
- NIC:
- Intel I219 (P920マザーボード直結)
- ConnectX-4 4121-ACAT
- 両方上位のSW(AT-x510-28GPX)に接続していましたが、途中からAHVのdmesgで`IPv4: martian source~`のエラーが出力されたため、ConnectX-4のみをつなげて試行しましたが、CVM側のエラーは変化なし。
情報が少ないかもしれません、その時は追加します。よろしくお願いいたします。
+9- Author
- Nutanix Employee
- April 27, 2023
ハードウェアの認識等の段階で問題があった場合はそもそもCVMが上がってくれないので、今回はその線は薄いかなと思います。
気になったエラーメッセージとしては
Please make sure that the SVMs from which you wish to create the cluster are not already part of another cluster.
という部分でして、こちらは -s オプションで指定したCVMが既にクラスタに組み込まれている可能性がある場合に表示されるものです。試しに私の構築済み環境で cluster createした場合も同じメッセージが表示されました。
nutanix@NTNX-4fe1d95c-A-CVM:192.168.10.37:~$ cluster -s 192.168.10.37 --redundancy_factor=1 create
2023-04-27 13:57:04,322Z INFO MainThread cluster:2943 Executing action create on SVMs 192.168.10.37
2023-04-27 13:57:07,355Z CRITICAL MainThread cluster:1001 Could not discover all nodes specified. Please make sure that the SVMs from which you wish to create the cluster are not already part of another cluster. Undiscovered ips : 192.168.10.37
nutanix@NTNX-4fe1d95c-A-CVM:192.168.10.37:~$ Connection to 192.168.10.37 closed by remote host.cluster status コマンドを実行した際、クラスタ作成済みですと下記のようにズラリと稼働中のサービスおよびプロセスIDが表示されますが、同じようなものが表示されないでしょうか。
nutanix@NTNX-4fe1d95c-A-CVM:192.168.10.37:~$ cluster status
2023-04-27 17:59:18,492Z INFO MainThread zookeeper_session.py:191 cluster is attempting to connect to Zookeeper
2023-04-27 17:59:18,507Z INFO Dummy-1 zookeeper_session.py:625 ZK session establishment complete, sessionId=0x187c0b7714918e7, negotiated timeout=20 secs
2023-04-27 17:59:18,515Z INFO MainThread cluster:2943 Executing action status on SVMs 192.168.10.37
The state of the cluster: start
Lockdown mode: Disabled
CVM: 192.168.10.37 Up, ZeusLeader
Zeus UP [3891, 3939, 3940, 3941, 3951, 3968]
Scavenger UP [16781, 16884, 16885, 16886]
Xmount UP [16776, 16912, 16913, 16915]
<長いので中略>
ClusterHealth UP [22289, 23132, 23384, 23385, 23389, 23393, 23472, 23473, 23475, 23476, 23478, 23480, 23483, 23484, 23496, 23497, 23498, 23524, 23525, 23527, 23614, 23615, 23632, 23633, 23642, 23643, 23652, 23653, 23914, 23916, 23918, 23919, 23920, 23921, 23922, 23924, 23925, 23926, 23927, 23928, 23932, 23933, 24008, 24009]
2023-04-27 17:59:20,307Z INFO MainThread cluster:3104 Success!今回、シングルノードクラスタとのことですので、インストーラーのメニューで
[ ]Create single-node clsuter?\
にチェックを入れていれば、少し時間はかかりますが手動でのcluste createはしなくても自動的にクラスタ作成およびクラスタ起動が行われ、ブラウザから https://<CVM-IP>:9440/console を開けばPrismにアクセス可能となりますので、そこにチェックが入っていた可能性があるかなと思っています。
- Adventurer
- April 27, 2023
確認ありがとうございます。
cluster statusコマンドを打ったところ、以下のように未構成というエラーメッセージが表示されました。
nutanix@NTNX-c8b707e8-A-CVM:172.30.202.3:~$ cluster status
2023-04-27 18:21:02,808Z CRITICAL MainThread cluster:2930 Cluster is currently unconfigured. Please create the cluster.
[ ]Create single-node clsuter?\
にチェックを入れていれば、
今回こちらのほうはチェックを入れてインストール処理を行ったので、私もこの点不審に思いAHVのログ(/var/log/firstboot.log)を確認したところ、下記のようにIPv6のパースエラーの後、クラスタの作成処理が中断しているように見えました。いったんv6が配られないようにして試みるのは手かもしれないです。
(v6アドレスはマスクしています。ただ、この状態でもログにあるようにfirstbootの成功フラグ?(/root/.firstboot_success)は作成されているんですよね。)
stderr: FIPS mode initialized
Warning: Permanently added '192.168.5.2' (ECDSA) to the list of known hosts.
Nutanix Controller VM
bash: line 0: [: 240b:11:xxxx:xxxx:xxxx:xxxx:xxxx:xxxx binary operator expected
2023-04-27 15:38:38,185 INFO Cluster could not be created. Please do so manually via the command line. See the online documentation for further details.
2023-04-27 15:38:38,186 INFO Running cmd ['touch /root/firstboot/phases/create_one_node_cluster']
2023-04-27 15:38:38,189 INFO Running cmd ['touch /root/.firstboot_success']
2023-04-27 15:38:38,192 INFO Running cmd ['service ntpd start']
2023-04-27 15:38:38,255 INFO Running cmd ['/sbin/chkconfig ntpd on']
2023-04-27 16:07:51,145 INFO first_boot_config = {
"phoenix_version": "phoenix-5.3.4_78fff4a2",
"svm_ip": "172.30.202.3",
"http_proxy": [],
"factory_folder": null,
"is_secureboot": null,
"foundation_ip": null,
"foundation_version": "unknown",
"rdma_passthrough": false,
"driver_package": "/tmp/drivers/driver_package.tar.gz",
"use_ten_gig_only": false,
"ce_eula_viewed": true,
"factory_drivers_location": [],
"boot_disk_info": null,
"svm_rescue_args": [],
"cluster_name": "NTNX",
"nos_version": "6.5.2",
"svm_numa_nodes": [
0
],
"host_backplane_ip": null,
"hyp_install_type": "clean",
"factory_partition_label": null,
"hyperv_sku": null,
"block_id": "c8b707e8",
"node_position": "A",
"hyp_image_path": null,
"host_ip": "172.30.202.2",
"hyp_version": null,
"foundation_payload": null,
"factory_lun_label": null,
"factory_phoenix_lun_index": null,
"factory_lun_index": null,
"pmem": {},
"monitoring_url_root": null,
"factory_success_flag_file": null,
"ce_disks": [],
"esx_path": "",
"hyperv_external_vswitch_alias": null,
"cvm_vlan_id": null,
"fio_detected": false,
"factory_iso_size": null,
"host_interfaces": [],
"boot_disk_model": "INTEL SSDPEK1W120GAH",
"hyperv_driver_spec_enabled": false,
"iso_whitelist_path": null,
"vswitches": [],
"boot_disk_sz_GB": 118.41044480000001,
"factory_error_flag_file": null,
"is_factory": false,
"svmboot_iso_path": "/mnt/svm_installer/install/images/svmboot.iso",
"factory_hyp_lun_label": null,
"factory_iso_path": null,
"hypervisor_hostname": null,
"factory_hyp_lun_index": null,
"factory_logfile_error": null,
==以下いったん省略していますあと気になった点としてはCVMのjournalにauditのエラーがバーストするくらい記録されていたことですが、一般のソフトウェアでもたまに見かけるので正常系か否かは判断できず…
nukopal
+9- Author
- Nutanix Employee
- April 28, 2023
詳細ありがとうございます。
AHVの.firstboot_successがあるのでAHV自体のfirstbootによるセットアップ(Open vSwitchの設定等々)は完了しているものの、CVMでのcluster createは出来ていない、という状態ですね。
気になっているのは今この状態で cluster create が出来ないにも関わらず cluster status は unconfigured な点ですね…。unconfiguredと認識されているということは、cluster destroy コマンドも通らなさそうでしょうか?
クリーンな状態で手動で cluster create した場合にどのようになるかを確認するために、いったん、
[ ]Create single-node clsuter?
のチェックを入れずに再インストールしてから、手動で cluster create してみると何かヒントが得られるかもしれないなと考えています。
+9- Author
- Nutanix Employee
- April 28, 2023
ちなみに、Single node clusterの自動作成に成功していると、AHVの/var/log/fistboot.logには下記のようなログが残ります。貼り付けて頂いた部分よりも前に、IPv6パースエラーの以外のメッセージはありませんでしょうか?(※投稿エラーになるので画像にしました…)
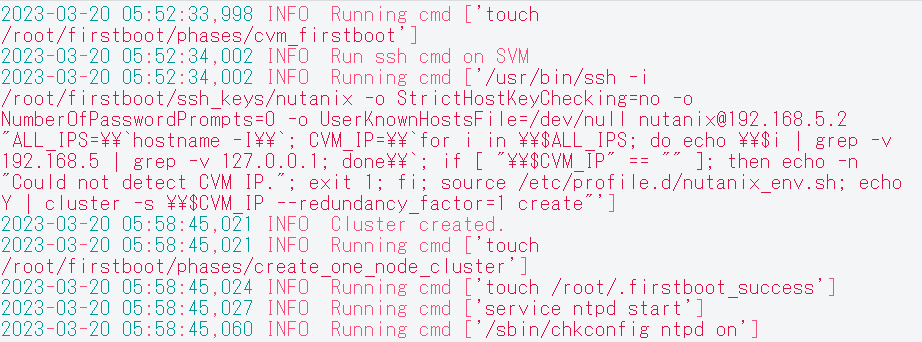
- Adventurer
- April 28, 2023
確認ありがとうございます。クリーンな環境での手動作成を試す前に、AHV・CVMが属するセグメントのIPv6を無効にしてグローバルなv6アドレスが降ってこないようにしたところ自動作成が何事もなく完了してしまいました。AHVの/var/log/firstboot.logにはエラーメッセージは確認されませんでした。
AHVの.firstboot_successがあるのでAHV自体のfirstbootによるセットアップ(Open vSwitchの設定等々)は完了しているものの、CVMでのcluster createは出来ていない、という状態ですね。~~
cluster destroy コマンドも通らなさそうでしょうか?
cluster destroyコマンドなどは通らなかったですね。unconfiguredでした。
Single node clusterの自動作成に成功していると、AHVの/var/log/fistboot.logには下記のようなログが残ります。貼り付けて頂いた部分よりも前に、IPv6パースエラーの以外のメッセージはありませんでしょうか?(※投稿エラーになるので画像にしました…)
そしてこちらについては、AHVのログを保存しきる前に作業元PCでトラブってしまったため、完全なログが手元から消えてしまったのですが、catコマンドで出力した先頭部分がそこで、前掲のエラーが出る前の出力はなかったと思います。
- Trailblazer
- May 2, 2023
ご教授いただいた方法でSSDと認識させて、インストールが進めましたが、
再起動の時(インストーラUSBを抜いた状態)に、ブートできるディスクが
見つかりませんと表示されています。
■物理サーバー構成
・サーバー:DELLPowerEdgeR620
・RIADコントローラ:PERC H710 Mini
・ディスク情報:
①sda SSD 1TB (Crucial MX500 2.5インチ) (CVMブートディスク)
②sdb SSD 1TB (Crucial MX500 2.5インチ) (データ)
③sdc SSD 256GB(Micron1100 2.5インチ) (AHVブートディスク)
④sdd USB 32GB (インストーラ)
①、②、③はそれぞれRAID0で構成しています。
お手数をおかけしますが、なにか対応策がありますでしょうか?
- Adventurer
- May 2, 2023
2020.9.20が動作している環境から、2.0へアップデートしようと思い、
再構築したところ、以下のエラーでCVMが起動しません。
2020.9.20を再インストールして動作するのですが、何が問題でしょうか。
機材は、
富士通 TX200 S6 CPU:xeon E5606×2 メモリ:64GB
SSD:1TB onbord HDD:1TB onbord
AHV:128GB SSD USB接続
[root@NTNX-83a3006f-A ~]#virsh start NTNX-83a3006f-A-CVM
error: Failed to start domain NTNX-83a3006f-A-CVM
error: internal error: qemu unexpectedly closed the monitor: 2023-05-01T23:36:50 .757659Z qemu-kvm: -object memory-backend-file,id=ram-node0,mem-path=/dev/hugepa ges/libvirt/qemu/NTNX-83a3006f-A-CVM,share=yes,prealloc=yes,size=21474836480: un able to map backing store for guest RAM: Cannot allocate memory
[root@NTNX-72daeebc-A ~]# tail -f /var/log/firstboot.log
2023-05-02 05:16:47,657 FATAL Execution of command [u'virsh start "NTNX-72daeebc-A-CVM"'] failed, exit code: 1, stdout:
, stderr: error: Failed to start domain NTNX-72daeebc-A-CVM
error: internal error: qemu unexpectedly closed the monitor: 2023-05-02T05:16:41.779012Z qemu-kvm: warning: Large machine and max_ram_below_4g (536870912) not a multiple of 1G; possible bad performance.
2023-05-02T05:16:41.790119Z qemu-kvm: unable to map backing store for guest RAM: Cannot allocate memory
+9- Author
- Nutanix Employee
- May 3, 2023
イメージング(CEインストーラー自体の挙動)についての問題は解決したようですので、あとはBIOS/UEFIが③のデバイス(AHVブートディスク)からOSをブートできれば問題ないと思うのですが、ブートデバイスの選択肢に出てこないのか、あるいはそのデバイスを選択してもOperating System Not Foundのような状態になってしまうのか、どちらでしょうか?
+9- Author
- Nutanix Employee
- May 3, 2023
qemu-kvm: unable to map backing store for guest RAM: Cannot allocate memory
このエラーが直接的な原因だと考えられます。何らかの原因で指定されたサイズのメモリを確保出来ない場合に表示されるエラーなのですが、AHV上でvirsh edit <CVM名>で設定を開いた際、CVMのメモリサイズの表記はどのようになっていますでしょうか?
(memoryの行、currentMemoryの行、およびcpu > numa > cellの行)
+9- Author
- Nutanix Employee
- May 3, 2023
マシン側で利用可能なHugePageのサイズも確認出来ると手がかりになるかもしれません。
cat /proc/meminfo | grep Huge
をAHVで実行して、結果をベタ貼りして頂けますと幸いです。
- Adventurer
- May 4, 2023
シングルノードクラスター作成オプションはチェックせずにインストール進めておりますが、AHV再起動後の処理が途中(CVM初回起動時処理のあたり?)で停止しているように見受けられます。
切り分けの確認ポイントはほかに確認すべきところはございますでしょうか?
(状況)
・再起動後にAHVログインしてコマンド確認するとCVMは動いているように見える。
・CVMへのssh接続とログインは可能。
・CVMから確認して稼働しているプロセスがfoundationとgenesisのみ。
・genesisのログにはZookeeperのエラーが出力している。
1.virsh list --allの結果
Id Name State
-------------------------------------
1 NTNX-fac608fe-A-CVM running
2.genesis statusの結果
2023-05-04 14:17:10.515726: Services running on this node:
foundation: [3461, 3525, 3526]
genesis: [2799, 2915, 2939, 2940]
3./home/nutanix/data/logs/genesis.out(抜粋)
2023-05-04 13:44:10,867Z INFO 32878672 foundation_service.py:161 Foundation service started successfully
2023-05-04 13:44:10,868Z INFO 32878672 node_manager.py:7084 Waiting for node to become configured through RPC
2023-05-04 13:44:11,453Z ERROR 59867984 node_manager.py:7046 Zookeeper mapping is unconfigured
2023-05-04 13:44:11,465Z ERROR 59867984 node_manager.py:7046 Zookeeper mapping is unconfigured
2023-05-04 13:59:24,213Z ERROR 59867984 node_manager.py:7046 Zookeeper mapping is unconfigured
2023-05-04 14:06:40,988Z ERROR 59867984 node_manager.py:7046 Zookeeper mapping is unconfigured
2023-05-04 14:14:34,990Z ERROR 59867984 node_manager.py:7046 Zookeeper mapping is unconfigured
4./var/log/firstboot.log(抜粋)
2023-05-04 13:38:24,795 INFO Running cmd ['touch /create_cvm']
2023-05-04 13:38:49,187 INFO [1/160] Waiting for CVM to initialize network
2023-05-04 13:39:13,572 INFO [2/160] Waiting for CVM to initialize network
2023-05-04 13:39:37,957 INFO [3/160] Waiting for CVM to initialize network
2023-05-04 13:39:55,086 INFO [4/160] Waiting for CVM first boot to create /tmp/svm_boot_succeeded
2023-05-04 13:40:10,471 INFO [5/160] Waiting for CVM first boot to create /tmp/svm_boot_succeeded
2023-05-04 13:40:25,784 INFO [6/160] Waiting for CVM first boot to create /tmp/svm_boot_succeeded
2023-05-04 13:40:41,176 INFO [7/160] Waiting for CVM first boot to create /tmp/svm_boot_succeeded
2023-05-04 13:40:56,562 INFO [8/160] Waiting for CVM first boot to create /tmp/svm_boot_succeeded
2023-05-04 13:41:11,808 INFO [9/160] Waiting for CVM first boot to create /tmp/svm_boot_succeeded
2023-05-04 13:41:27,048 INFO [10/160] Waiting for CVM first boot to create /tmp/svm_boot_succeeded
2023-05-04 13:41:42,483 INFO [11/160] Waiting for CVM first boot to create /tmp/svm_boot_succeeded
2023-05-04 13:41:58,660 INFO [12/160] Waiting for CVM to finish first boot
2023-05-04 13:42:14,937 INFO [13/160] Waiting for CVM to finish first boot
2023-05-04 13:42:30,690 INFO [14/160] Waiting for CVM to initialize services
2023-05-04 13:43:35,350 INFO Running cmd ['touch /root/firstboot/phases/cvm_firstboot']
2023-05-04 13:43:35,354 INFO Running cmd ['touch /root/.firstboot_success']
2023-05-04 13:43:35,357 INFO Running cmd ['service ntpd start']
2023-05-04 13:43:35,405 INFO Running cmd ['/sbin/chkconfig ntpd on']
Nobuta
+9- Author
- Nutanix Employee
- May 4, 2023
CVMのfirstboot処理は終わっているようですので、この状態からCVMでクラスタの手動作成を行うことは出来ないでしょうか?
- Adventurer
- May 4, 2023
早速のご返信ありがとうございました。
クラスタの手動作成は未だ試みておりませんでしたので実行してみます。
Nobuta
- Adventurer
- May 8, 2023
メモリサイズの表記は、20971520 となっており、問題無いかとおもわれます。
cat /proc/meminfo | grep Hugeの結果については、以下の通りです。
[root@NTNX-ce0eb74d-A ~]# cat /proc/meminfo | grep Huge
AnonHugePages: 0 kB
ShmemHugePages: 0 kB
FileHugePages: 0 kB
HugePages_Total: 0
HugePages_Free: 0
HugePages_Rsvd: 0
HugePages_Surp: 0
Hugepagesize: 2048 kB
Hugetlb: 0 kB
以上、宜しくお願い致します。
- Trailblazer
- May 8, 2023
ご返事いただき、ありがとうございます。
再起動の時(インストーラUSBを抜いた状態)に、「No boot device available」と表示されています。
またBIOSブートマネージャーから表示されている「Integrated RAID PERC H710 Mini(bus 02 dev 00) を選択しても、「No boot device available」と表示されています。
+9- Author
- Nutanix Employee
- May 8, 2023
ご返信ありがとうございます。CVMのメモリサイズ指定自体は問題無さそうです。
一方で、Hugepagesに関する出力結果を見ると、Hugepagesize以外の行が軒並み0になっているので、お使いのマシンではHugepageが有効でないように見えます。有効な場合AnonHugePages, HugePages_Total, HugePages_Free, Hugetlbあたりに容量が反映されています。
これを頼りに少し掘り下げるため、virsh edit CVM名 でCVMの構成情報を開いてみると、CPU周りの設定がCE 2.0では
<cpu mode='host-passthrough' check='none'>
<numa>
<cell id='0' cpus='0-3' memory='20971520' unit='KiB' memAccess='shared'/>
</numa>
</cpu>となっていました。
https://libvirt.org/formatdomain.html
によると、以下の記載がありました。
Since 1.2.9 the optional attribute memAccess can control whether the memory is to be mapped as "shared" or "private". This is valid only for hugepages-backed memory and nvdimm modules.
よって
・memAccess='shared'という設定があることでhugepagesが要求されている
・このマシンには払い出し可能なhugepagesがない
という状態が原因でCVMが起動しなくなっているものと推測しています。
比較のためce-2020.09.16のCVMの構成情報を確認したところ、CVMのCPU設定は以下のようになっていました。
<cpu mode='host-passthrough' check='none'>
<feature policy='disable' name='spec-ctrl'/>
</cpu>memAccess='shared'(というかnuma自体の設定)がありませんでしたので、
CE 2.0のCVMのCPU設定をまるっとこの内容に書き換えることで起動可能とならないでしょうか?
同世代のマシンを持っていないので机上の推測ですが、お試し頂けますと幸いです。
Enter your E-mail address. We'll send you an e-mail with instructions to reset your password.