

本記事はJosh Odgers氏が2020年8月21日に投稿した記事の翻訳版です。
パート2ではVMC/vSANが「ディスクグループ」アーキテクチャを採用していることからNutanix Clustersのほうが劇的に多くの利用可能なキャパシティを提供しながら、高いしなやかさを保証できることを学びました。
パート3ではこの先進性が環境のサイズが拡張していくにつれてより良くなっていくだけであることを見てきました。
パート9ではVMware社の直近のAWS i3en.metalインスタンスとNVMeネームスペースについてのアナウンスについて見ていきます。
この記事において興味深いのは私がVMC/vSANがそれを支える物理フラッシュストレージデバイスにおいて非効率すぎると言い続けてきたことを確認できるということです。
この新しいホストで利用可能になるRawハードウェアを見ると、8本の7.5TB NVMeデバイスを見つけることができます ― ほぼ60TBのRawメディアで劇的なまでの量のリソースを保証してくれます。残念なことにvSANで7.5TBのNVMeデバイスを利用するには課題があります。もしもi3.metalでの実装をコピーしてメディアをディスクグループの一部へと分解していくと、キャッシュ層における利用されることのないリソースについてどうすることもできなくなってしまいます。
リファレンス: HTTPS://BLOGS.VMWARE.COM/VIRTUALBLOCKS/2020/07/15/I3EN-METAL-ENHANCED-CAPACITY/
ですから、「ディスクグループ」のアーキテクチャ上の成約を回避するために、VMC on AWSはNVMeのネームスペースを利用し、フラッシュデバイスのキャパシティを論理的に分割し、別々のデバイスとして認識させています。
これによって、VMC/vSANはWriteキャッシュレイヤーにおけるキャパシティの無駄を最小化することができるため、その意味ではこれは良い改善になるように思えます。
VMCのソリューションでは7.5TBのNVMeフラッシュストレージデバイスを4つのネームスペースで分割し、32の独立した認識デバイスを作り上げます。そしてそれらはそれぞれのディスクグループが2つの専用デバイス利用した8つのネームスペースを利用する4つのディスクグループへと分割されます。
ディスクグループが増えることでNVMeのネームスペースを利用しない場合の2つに比べて、4つの「キャッシュ」ドライブが利用できることになり、パフォーマンスの改善に貢献します。
このブログのタイトルの繰り返しになりますが、ハイレベルではパフォーマンスに妥協することなくキャパシティを改善するという事ができそうに聞こえます。
しかし、これで追加されることもあります。4つのディスクグループということはより多くのメモリ(RAM)がストレージ(vSAN)層のためだけに必要になるということでもあります。
どのぐらいのメモリでしょうか?
計算は以下のとおりです。(私の計算にミスがないかチェックしてください!!)
7100 + 4 * (1360 + 600 * 20 + 7 * 160) = 65020MB これは重複排除と圧縮がない場合です。
65GBがvSANストレージ層のためだけに使われるのです!
VMCがNVMeのネームスペースを利用しない場合のメモリの利用はどうだったでしょうか?:
7100 + 2 * (1360 + 600 * 20 + 3 * 160) = 34780MB これは重複排除と圧縮がない場合です。
随分現実的にはなりますが、vSANストレージ層のために34GBです。
これはVMCのディスクグループアーキテクチャにある多くの欠点のうちの一つです。
NVMeネームスペースを利用することでのキャパシティと潜在的なパフォーマンスについての効果のために、VMCをご利用されるお客様はホストあたり32GBの追加メモリの高いコストを払うことになります(これは重複排除と圧縮がない場合)、更にドライブ障害から回復力は劇的に低下し、より大きな影響を及ぼします。
Nutanix Clusters(Nutanix AOSベース)はその一方ではじめからキャッシュ+キャパシティのアーキテクチャ上の欠陥を回避するように設計されています。
メモリ利用量の観点からはVMwareが継続的にコントローラーVM(CVM)のリソースについて批判をしていますが、コントローラーVMはフラッシュデバイスの数が変わっても利用するRAMの量は32GBから変わることはありません。
ビジネスクリティカルアプリケーションを動作させているお客様は1つもしくは複数のCVMにより多くのRAMを割り当てることでより大きな効果をご提供でき、48GBは大容量のノード上で、大規模なアクティブなワーキングセットを持つようなワークロードを動作させる際のスイートスポットですが、これは大抵の場合ワークロード全体から見ると小さな割合です。
VMware vSANとNutanix AOSの直接的なメモリの比較については: Memory Usage Comparison – Nutanix AOS vs VMware vSAN / DellEMC VxRAIL をご参照ください。
NVMeのネームスペースのトピックスへと戻りましょう、AOSはすでにネイティブで書き込まれるwriteとReadのI/Oの両方ですべてのフラッシュデバイスを利用します。
これはi3en.metalのようなベアメタルインスタンスにとっては、VMCがNVMeのネームスペースを利用してさえ、4つしか利用できないのに対して、Nutanixはサーバー内のすべての8つのフラッシュデバイスを活用できるということです。
これはNutanixにとってはすべてのドライブにドライブの摩耗が分散し、デバイスのライフ期間を改善できること(これについてはクラウドではこれまでほどには議論すべき内容ではなくなります)は言うまでもなく、明らかなパフォーマンス上の優位性となります。しかし、これはドライブ障害のリスクを低減しますし、それに紐付いた本稼働ワークロードへの影響も低減することができます。
NVMeのネームスペースを利用することで、VMCは利用可能なキャパシティの観点と、論理的なパフォーマンスの観点からはより競争力がでてきますが、それはノードあたり32GB前後の追加メモリ、トータルで重複排除と圧縮がない場合でも65GB以上のコストを伴うものです。
それではもっと重要な回復力いついての制限を見ていきましょう。
VMCはVMwareのブログにある以下の図のように論理的に4台のキャッシュに利用されるデバイスと、4台のキャパシティにのみ利用されるデバイスを利用することになります。
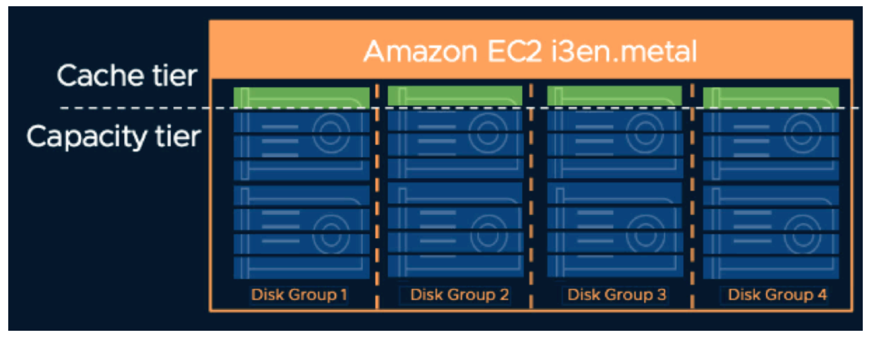
これはドライブ障害イベント時に、VMCの顧客は50%の確率(8のうち4つ)でディスクグループ全体を失うということであり、最大で15TB(2 x 7.5TB)のデータのリビルドが必要であるということになります。
NVMeのネームスペースを利用しない場合の2つのディスクグループ構成の場合、暖いつドライブの障害時に単一ディスクグループが失われる確率は25%だけになります。
そして繰り返しになりますが、もしもお客様がVMCで重複排除と圧縮を利用している場合、あらゆるディスクドライブの障害はNVMeのネームスペースを利用しているか、いないかに関わらず、ディスクグループ全体の喪失を引き起こします。
これはディスクグループアーキテクチャが本稼働系ワークロードで利用するにおいては欠陥品であることを示すもう一つの例になります。このデザイン上の制約とリスクの高さはNutanix Clustersのようなはじめから拡張性、弾力性、効率性そして性能を妥協することなく組み込んでデザインされたソリューションはおろか、従来型のSAN/NASソリューションにさえ劣るものです。
まとめると、概念上の欠陥をもつディスクグループアーキテクチャにNVMeのネームスペースを利用することで、弾力性についてはVMwareは単一NVMeフラッシュデバイス障害でディスクグループ全体が障害となるリスクを2倍に増加させており、それが発生した場合15TBものデータのリビルドが必要になります。
キャパシティまたはパフォーマンスのために回復力を妥協するということは絶対に避けるべきアーキテクチャ上の間違いの一つであり、オーストラリア税務署(ATO)がそのシステム停止の後に経験したようなニュースでのように、悪い事態を更に悪化させることにも繋がりかねません。
ATOのコミッショナーのChris JordanはITnews.com.auの記事で以下のように述べています:
3PAR SANの障害は複数のイベントの同時発生の結果もたらされました : 光ファイバーケーブルからの入力がSANに適切にフィットせず、ソフトウェアのバグによってSANのディスクドライブに保存されたデータがアクセス不能、読み込めなくなった結果、HPEのモニタリングツールがエンドツーエンドで有効にならなかった、そしてSANの構成が安定性や弾力性ではなくパフォーマンスよりの構成になっていた、とJordanは述べています。
同じハードウェア(i3en.metal)であっても、あらゆる単一のフラッシュデバイスの障害がそのフラッシュデバイスのキャパシティ(7.5TB)のみのリビルドで済む、Nutanix Clustersのお客様は同じ障害シナリオであっても、影響はその半分で済むのです!
VMware社からは他にも興味深い見解がでています:
NVMeインターフェイスとプロトコルはPCIe上で直接ストレージクラスメディアへ接続、アクセスするために1から作り上げたものです。SATAやSASにこれまで依存していたレガシーなSCSIレイヤーを取り除き、ストレージメディアをCPUの近くへと移動させることができました。
リファレンス: HTTPS://BLOGS.VMWARE.COM/VIRTUALBLOCKS/2020/07/15/I3EN-METAL-ENHANCED-CAPACITY/
データをCPUの近く(ローカル)に保つことは効果があるのでしょうか? これはとても不思議です、VMwareは継続してパート1でネットワークへの要件と依存関係を低減するNutanixのユニークな最初のWriteを(リアルタイムに)最適に配置し、Read I/OがCPU(と仮想マシン)のそばで行なわれることを保証するデータローカリティアーキテクチャを意味がないものだと主張し続けて来たことに疑問が生じます。
まとめ:
vSANをベースとしたVMwareのVMC製品はディスクグループでの設計上の欠陥をより多くの利用可能なキャパシティ(と幾ばくかの性能)の向上のためにNVMeのネームスペースをワークアラウンド(もしくはその場しのぎ)として利用しています。しかしこれは回復力のためのコストとリスクそして、フラッシュストレージデバイスの障害時の影響を伴います。
VMwareのブログ記事ではNVMeのネームスペースによってソリューションは素晴らしいものになるかのようにアナウンスされていますが、私の目からは統合性を欠いていることによる回復力への影響について伝えていないどころか言及さえしていません。
Nutanix Clusters(AOS)は、VMwareのブログに記載されているのと同様にはじめからすべてのNVMeネームスペース(それがコモディティのSSD上であったとしても)の恩恵をすべて提供できるのみならず、追加のRAMや議論すべき全ての回復力への影響は伴いません。
パブリッククラウドでの課題の索引へと戻りましょう。