

本記事はJosh Odgers氏が2020年8月18日投稿した記事の翻訳版です。
パート1では、AWSでVMwareのVMC製品を使用する場合、VMwareやその顧客はネットワーク帯域幅を制御できないという、VMCのコアアーキテクチャーが及ぼす重大な影響について紹介しました。
パート1をお読みいただいていない場合は、この投稿を読み進める前に目を通していただくことをおすすめします。パート1で紹介している概念は、この投稿のテーマである「デバイス障害と回復力への影響」について理解を深めていただくために重要です。
パート2、パート3、およびパート4では、AOSの機能のおかげで、Nutanix ClustersではVMCよりも高いフロントエンドパフォーマンスを発揮しながら、使用可能な容量も多くなるということについて紹介しました。
また、パート4では、VMC(vSAN)で圧縮と重複解除を使用すると、ドライブ障害のリスクや影響が大きくなるのに対して、Nutanix Clustersでは、このようなデータ効率テクノロジーを使用するかどうかに関係なく、回復力への影響がないことを紹介しました。
このようにNutanix ClustersはVMC/vSANに対して優位性がありますが、プラットフォームが障害に対して高い回復力を備えていなければ意味がありません。
この投稿では、AWS i3.metalインスタンスを使用する場合に、Nutanix ClustersとVMware VMCがさまざまなドライブ障害シナリオをどのように対処し、どのように回復するのかについて紹介します。
AWS EC2 i3.metalインスタンスなどのパブリッククラウドサービスを使用する際、NVMeフラッシュデバイスは耐久性が高くないと考えられるため、VMC/vSANなどの製品がディスクグループごとに単一キャッシュドライブに大きく依存する場合は、Drive Writes Per Day(DWPD:1日当たりのドライブ書き込み数)の指標が適切でない可能性がある、ということを考慮することが重要です。
VMwareは記事「Understanding vSAN Architecture: Disk Groups」の中で、キャッシュドライブに関して以下のように述べています。
高耐久性フラッシュデバイスをキャッシュ層に適用して、大部分のI/Oを処理するようにします。このようにすると、キャパシティ層で、低いスペックのフラッシュデバイスを使用できます。
参照先:HTTPS://BLOGS.VMWARE.COM/VIRTUALBLOCKS/2019/04/18/VSAN-DISK-GROUPS/
AWS EC2インスタンスでは、NVMeデバイスの仕様は公表されていないため、アーキテクチャー上のリスクを軽減したい観点のために、NVMeデバイスは耐久性が低くコモディティのフラッシュデバイスであると想定し、この想定に従ってソリューションの回復力を設計する必要があります。
Nutanix Clustersでは、ノード内のすべてのフラッシュデバイスを新規の書き込みに使用するインテリジェントな分散ストレージファブリックのおかげで、標準仕様でこのリスクが軽減されます。一方でVMCにおいては、本質的に単一フラッシュデバイス(ディスクグループ当たり)上で書き込みに対するキャッシュが実行されます。
つまり、VMCの場合は、フラッシュデバイスの品質に関係なく、基盤となる「キャッシュ+キャパシティ」のディスクグループアーキテクチャーのために、キャッシュデバイスに障害が発生するリスクが高くなります(大幅に高くなると言えます)。
本ブログの読者の中にはNutanix AOSに詳しくないという方もいらっしゃると思いますが、Nutanix AOSにはVMC/vSANのディスクグループのような概念や複雑さはありません。すべてのドライブがクラスター全体または「グローバルな」ストレージプールに含まれ、すべてのフラッシュ環境内ですべてのドライブが書き込みI/Oおよび読み取りI/Oにアクティブに使用されます。限られた数のキャッシュドライブで書き込みI/Oが実行されてからキャパシティ層にデステージされるのとは対照的です。
Nutanix Clustersではすべてのドライブが使用されるため、ドライブの摩耗もさらに軽減されます。そのため、ホットスポットが少なくなり、回復力とパフォーマンスが向上します。
つまり、Nutanixのアーキテクチャーは、基盤となるフラッシュの耐久性にそれほど依存しません。パブリッククラウド環境を使用する場合、顧客はフラッシュストレージデバイスの品質に対処できないため、このことはアーキテクチャー上の大きな利点となります。
詳しくは、私が最近行ったNutanixとvSAN(VMCのベース)の比較High Endurance Flash Device requirement comparison(高耐久性フラッシュデバイス要件の比較)をご覧ください。
以前の記事で紹介したように、「チェックボックス」形式のマーケティングスライドでは、重要なアーキテクチャーやサイジング、回復力を検討する際に誤った認識を前提としてしまうことが多いです。
この問題は回復力に関しても当てはまり、ここではドライブ障害に関して以下のような簡単な例を示そうと思います。
| 対障害性 | Nutanix | VMware VMC/vSAN |
| SSD/HDDのうち1台の障害 (RF2/FTT1) |  | |
| SSD/HDDのうち2台の障害 (RF3/FTT2) | | |
チェックボックスを比べると、どちらのプラットフォームも、それぞれNutanix回復ファクタRF2またはvSAN Failures to Tolerate FTT1を構成するとSSD/HDDの障害を許容でき、それぞれNutanix RF3またはvSAN FTT2を使用するとSSD/HDDの障害が2つ同時に発生しても許容できます。
また、以下の障害が発生した場合、両製品とも自己治癒を実行できます。
| 対障害性 | Nutanix | VMware VMC/vSAN |
| 1台のドライブ障害発生後の自己治癒 (RF2/FTT1) | | |
| 2台のドライブ障害発生後の自己治癒 (RF3/FTT2) | | |
チェックボックスからは、どちらの製品も対応していると読み取れます。
ただし、実際はそうではありません。障害の影響は、VMCで使用されている基盤となるvSANアーキテクチャーのために大きく異なります。Nutanixプラットフォームの場合、障害はデータ削減機能の構成やホスト内のストレージデバイスの数に関係なく常に処理されます。
例1:VMCノードの「キャッシュ」ドライブ障害
AWS i3.metalインスタンスでVMC/vSANを使用する場合、2ディスクグループ構成がデプロイされます。この構成では、回復力やパフォーマンスが単一ディスクグループよりも高くなりますが、そのために、使用可能な容量が犠牲になります。2つの「キャッシュ」ドライブの1つに障害が発生すると、その影響として、ディスクグループ全体(1つのキャッシュドライブと3つのキャパシティドライブ)がオフラインになるのです!。
VMCで単一キャッシュドライブ障害が発生すると、他の3つのキャパシティドライブがオフラインになり、リビルドが必要になるということです。つまり、4つの1.9TBドライブが使用不可能になり、帯域幅に大きなばらつきがあるネットワークを介してVMC/vSANによってこれらのドライブをリビルドする必要があります。
Nutanixでは、単一ドライブ障害の際は文字通り単一ドライブ障害分の対応をすれば良く、1.9TBドライブ1つをリビルドすれば済みます。
この例では、i3.metalインスタンスを使用する場合、Nutanixでの影響はvSANの4分の1になっています。
現時点で、VMC/vSANは実用最小限の製品ではないと判断しているかと思いますが、Nutanixをデプロイしていただけるなら時間に余裕ができることと思いますので、このまま読み進めていただければ幸いです。
例2:重複排除と圧縮使用時のVMC/vSANのドライブ障害
重複排除と圧縮を使用する場合、例1で紹介したように、いずれかのキャッシュドライブに障害が発生した場合、ディスクグループがオンラインになりますが、いずれかのキャパシティドライブに障害が発生した場合も、ディスクグループ全体の4つのドライブが使用不可能になります(AWS i3.metalインスタンスの場合)!
Nutanixでは一貫して、皆様ご承知の通り、単一ドライブ障害が発生した場合は、1.9TBドライブ1つのリビルドで済みます。
例2においても、Nutanixでの影響はVMC/vSANの4分の1になったことがお分かりいただけたことでしょう。
まだ読み続けていただいているでしょうか。それとも、Nutanix Clustersのデプロイに取り掛かっていただいているかもしれませんね。
例3:VMC/vSANでは分散型のきめ細かいリビルドを行えない
VMC/vSANは、最大255GBのオブジェクトを格納して同じレベルでリビルドする「オブジェクトストア」設計を基盤としており、この設計の制約を受けます。
つまり、VMCのリビルドは、オブジェクトもリビルドできる場所(クラスター内)に限られます。各オブジェクトを格納できるだけの十分な容量が必要なためです。オブジェクトからオブジェクトへのリビルドは本質的に1つのドライブから別のドライブに対して行われる(2ノードでの2つのフラッシュデバイスなど)ため、パフォーマンスが低下します。またフラグメンテーションも発生するため、先に紹介したように、VMwareでは25~30%のスラックスペースを推奨しています。さらに、VMC/vSANのリビルドはキャッシュドライブを使用して実行されるため、最短のMTTR(Mean Time to Recovery:平均修復時間)を達成できる可能性も低くなります。
つまり、VMC/vSANでは、Nutanix Clustersよりも使用可能な容量が少なくなり、かつ、リビルドにかかる時間も長くなるのです。
では、リビルドに関して、Nutanix ClustersはVMware VMCよりもどの程度優れているかをご紹介しましょう。
Nutanixでは4MBのきめ細かいリビルドが実行され、ラージオブジェクトの制約はありません。vDiskは、必要なだけの数の4MBエクステントグループで構成され、クラスター全体のパフォーマンスと容量に基づいて分散されます。つまり、Nutanix Clustersのリビルドでは、単一ドライブのリビルドにクラスター内のすべてのノードとすべてのドライブが使用されるため、リビルドにかかる時間が短くなり、影響も小さくなります。結果として、クラスターの容量バランスが向上し、後処理やリアクティブなディスクバランシングの必要性がゼロになるか、もしくは最小限に抑えられます。
Nutanix Clustersでリビルドをいかに短時間で実行できるかの例については、私が2018年に執筆したノードリビルドのパフォーマンスに関する記事をご参照ください。この記事では、Nutanix AOSが効率性に優れており、物理SSDのほぼ最大限のパフォーマンスでリビルドを実行できることを紹介しています。
以下に、AWS i3.metalインスタンスでNutanixを使用し、11ノードのクラスターでノード削除を実行した場合のパフォーマンス例を示します。
注:ノード削除とノード障害は両方とも、クラスター内のすべてのノードとドライブを利用する完全な分散操作です。そのため、ノード障害が発生した場合、同等のスループットを達成できます。
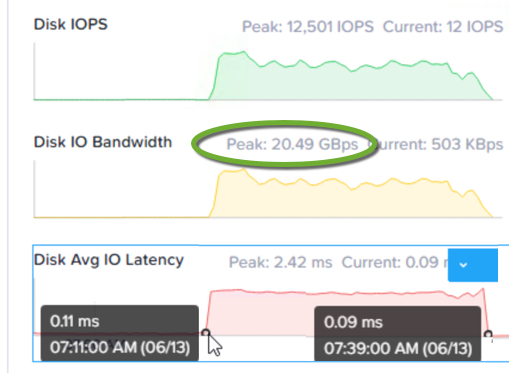
削除やノード障害からのリカバリを28分で実行できると、非常に魅力的なMean Time To Recover(MTTR:平均修復時間)を実現し、かつデータ整合性を最大まで高めることができます。クラスターの規模が大きいほど、リビルドにかかる時間が短くなり、MTTRも向上します。
ピークストレージスループットは20GBpsを超え、持続的なスループットも約16GBps(ノード当たり約1.6~2.0GBps)となっています。
パート1で、効率的なネットワーク使用がいかに重要かについて紹介しましたが、Nutanixのデータローカリティなしでは、このプロセスを実行するにはノード当たり12.8~16Gbpsのネットワーク帯域幅が必要です。そのため、各ノードで使用可能な帯域幅がほぼ飽和状態になる可能性があり、仮想マシントラフィックの使用可能な帯域幅はゼロ、もしくは最小限になります。他のストレージやクラスター操作のトラフィックについても言うまでもなく同様です。
読者の中で、まだVMware VMCを検討しているという方がいらっしゃいましたら、例4を参照いただくことで考えが変わるでしょう。
例4:VMC(vSAN)では保守時/障害発生時にI/O整合性が維持されない
回復力に関してNutanixがVMC/vSANよりも優れている点として、すべての障害シナリオや保守シナリオにおいて、Nutanix Clustersの書き込みI/Oは、構成されている回復ファクタに常に従うということが挙げられます。
ただし、VMCでは、すべてのホスト保守シナリオや障害シナリオにおいて構成されている回復力レベル(FTT)が維持されるわけではありません。VMCでVMをFTT1で構成した場合、1つのvSANディスク「オブジェクト」が配置されたホストが保守のためにオフラインになると、新たな上書きは保護されないため、単一ドライブ障害が発生するとデータ損失につながります。保守のためにノードがオフラインになっており、ノードからすべてのデータを退避させることを顧客が選択していない場合、書き込みはFailure to Tolerate(FTT)ポリシーに従って維持されません。
詳しくは、回復力について触れたシリーズの投稿の一つであるパート6、保守時または障害時の書き込みI/Oに関する投稿をご参照ください。
まとめ
- Nutanixでは、レガシーな「キャッシュ+キャパシティ」スタイルのディスクアーキテクチャーの制約を受けないため、ドライブ障害の影響が大幅に小さくなります。
- データローカリティのおかげで、Nutanixのリビルド(またはノード削除)は極めて短時間で実行でき、ネットワークへの影響も最小限に抑えられます。そのため、大部分の帯域幅を仮想マシンやクラスターのトラフィックに使用できます。
- Nutanixでは、単一ディスク障害は単一ディスクデータにしか影響しません。「ディスクグループ」全体のドライブ(i3.metalの場合、4つの1.9TBドライブ)に影響が及ぶわけでばありません。
- 重複排除や圧縮などのデータ効率テクノロジーが適用されているかどうかに関係なく、Nutanixのドライブ障害は同じように処理されるため、効率と回復力のどちらを取るべきかについて妥協する必要がありません。
- Nutanixでは、ドライブ障害のシナリオ、および保守時において、書き込みI/Oの整合性が常に維持されます
- vSANをベースとするVMCでは、障害シナリオや保守時にデータ回復力が維持されない場合があります。
次は、パート6で、Nutanix ClustersとVMware VMCのノード障害のシナリオについて紹介します。