

本記事はJosh Odgers氏の記事の翻訳版です。
AWS EC2などのパブリッククラウド製品は「ベアメタル」サーバーをレンタルする機能を長年提供しており、顧客やパートナー企業はこの機能を利用することで、それぞれ選択したワークロードやソリューションをデプロイしています。
追加のハードウェアはスタンバイ状態になっており、これまでと比べ短時間でのデプロイが可能なため、ハイパーコンバージド・インフラストラクチャー(HCI)ベンダーは、オンプレミス環境よりもさらに柔軟にオンデマンドで拡張できる形でベンダーのソリューションを提供できるようになりました。
AWS EC2などのサービスは、ベアメタルインスタンス当たりの接続数や使用可能な帯域幅に関して、顧客がネットワークをほとんど制御できない点が課題となります。
例えば、よく使用されているi3.metalインスタンスには、36個の物理CPUコア、512GBのメモリー、および25ギガビットネットワーク(公表値)が、8本の1.9TB NVMe SSDとともに含まれています。

この構成は、Nutanixのような高度なHCIソリューションには最適ですが、ネットワークへの依存度が高いvSANのような製品にはそれほど適していません。
「25ギガビットネットワーク(公表値)」とした理由
実際に25Gbpsが使用可能なわけではないためです。使用できるのは、i3.metalインスタンスが同じ1台のラック内に配置されている場合は接続当たり最大10Gbps、複数のラックにまたがって配置されている場合は最大5Gbpsです。
以下の例は、最新のアイドル状態のクラスターでテストした結果、AWS EC2で大きなばらつきが発生するということを示しています。
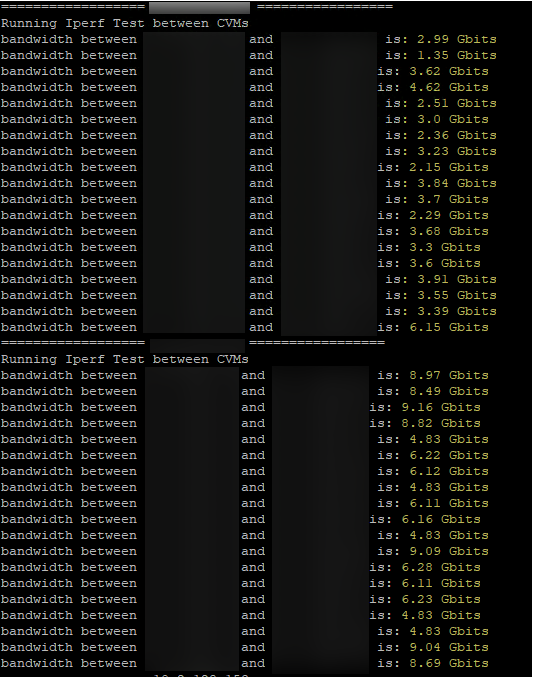
次に、HCIソリューションをAWS EC2にデプロイした場合の、ネットワークの利用状況への影響について紹介します。
- ストレージトラフィックと仮想マシントラフィック
ストレージトラフィックがネットワークを独占的に使用する場合、仮想マシントラフィックが使用できる帯域幅はごくわずかであるため、ストレージ層のパフォーマンスが高くても、エンドユーザーアプリケーションやビジネスクリティカルなアプリケーションでは、全体的なパフォーマンスが不十分になる可能性があります。
- インフラストラクチャの操作トラフィック
vMotionなどの操作を実行する場合、「バースト」するような動作を正常かつタイムリーに実行するには、クラスターにネットワーク帯域幅が必要です。
vMotionに時間がかかると、ビジネスアプリケーションへの影響が大きくなり、vSphere DRSやNutanix ADSでの保守動作やパフォーマンス最適化動作にかかる時間も長くなります。
また、環境内で実行されるハイパーバイザー層やストレージ層のアップグレードにも影響が及びます。
- ビジネス継続性のトラフィック
ドライブやノード、もしくはラックに障害が発生した場合はどうなるのでしょうか。
データを再保護(レプリカ)するため、プラットフォームはネットワークを最大限に活用する必要がでてきます。仮想マシンやストレージトラフィック、さらにはvMotionなどのためのトラフィックがネットワークを大幅に使用している場合、プラットフォームでデータを再保護する機能が低下し、最終的には基幹業務アプリケーションのパフォーマンスが低下するリスクが高くなり、さらにはデータ損失が発生するリスクも高くなります。
Nutanix Enterprise Cloudアーキテクチャーによってリスクが軽減される理由
- 障害の影響を最小化
Nutanixでは、単一ドライブ障害(この場合、AWS i3.metalインスタンスに含まれている1.9TB NVMe SSDの障害)が発生した場合、再構築が必要になるのは、多くともその単一ドライブの容量だけです。
その理由は、Nutanixでは、キャッシュドライブとディスクグループの概念を適用していないためです。この概念を適用している場合、単一キャッシュドライブ障害が発生すると、ディスクグループ全体(最大7ドライブの容量、つまり1.9TBのドライブ7つ分)のデータを再構築することが必要になり、リスクが高くなります。
重複排除および圧縮をキャッシュドライブとディスクグループで使用する場合、単一ドライブ障害が発生すると、ディスクグループ全体の再構築が必要になり、最大13.3TBのデータを再構築することが必要になります。一方で、Nutanixの場合は最大1.9TBのデータ再構築で済みます。
- ネットワークへの依存を最小化
Nutanix AOS固有のデータローカリティ機能を使用すると、大部分の読み取りI/Oはネットワークを経由せず、通常は書き込みI/Oの半分(1個のレプリカ)のみがネットワーク経由で送信されます。
その結果、読み取りI/Oと書き込みI/Oの比率が70対30の場合、ネットワーク経由で送信されるのはI/O全体の15%(書き込みレプリカの半分)だけになります。
Nutanixでは、VMが別のホストに移行された場合でも、ネットワーク経由で送信された1個のレプリカを使用して、新しい書き込みはローカルで実行されます。新規データはもっともアクティブなデータであることが多いため、通常、それ以降の読み取りはローカルから実行されます。
これに対して、収益の公表値で首位に立つ他社のHCIプロバイダーの場合は通常、仮想化ストレージによって大部分の読み取りI/Oと書き込みI/Oがネットワーク経由で送信されます。
データローカリティのメリットについては、投稿「Think Data Locality is just about Storage Performance? Think again!(データローカリティはストレージパフォーマンスにしか関係しないと思っていませんか。ぜひ再考を!)」で紹介しています。データローカリティの目的はストレージパフォーマンスだけではなく、考えられるさまざまな制約に対処することであることを記載していますので、ぜひ一読ください。
実際に確認してみましょう
以下の図は、4ノードから32ノードまでのi3.metalインスタンスを使用してNutanixで達成した読み取り帯域幅を示しています。
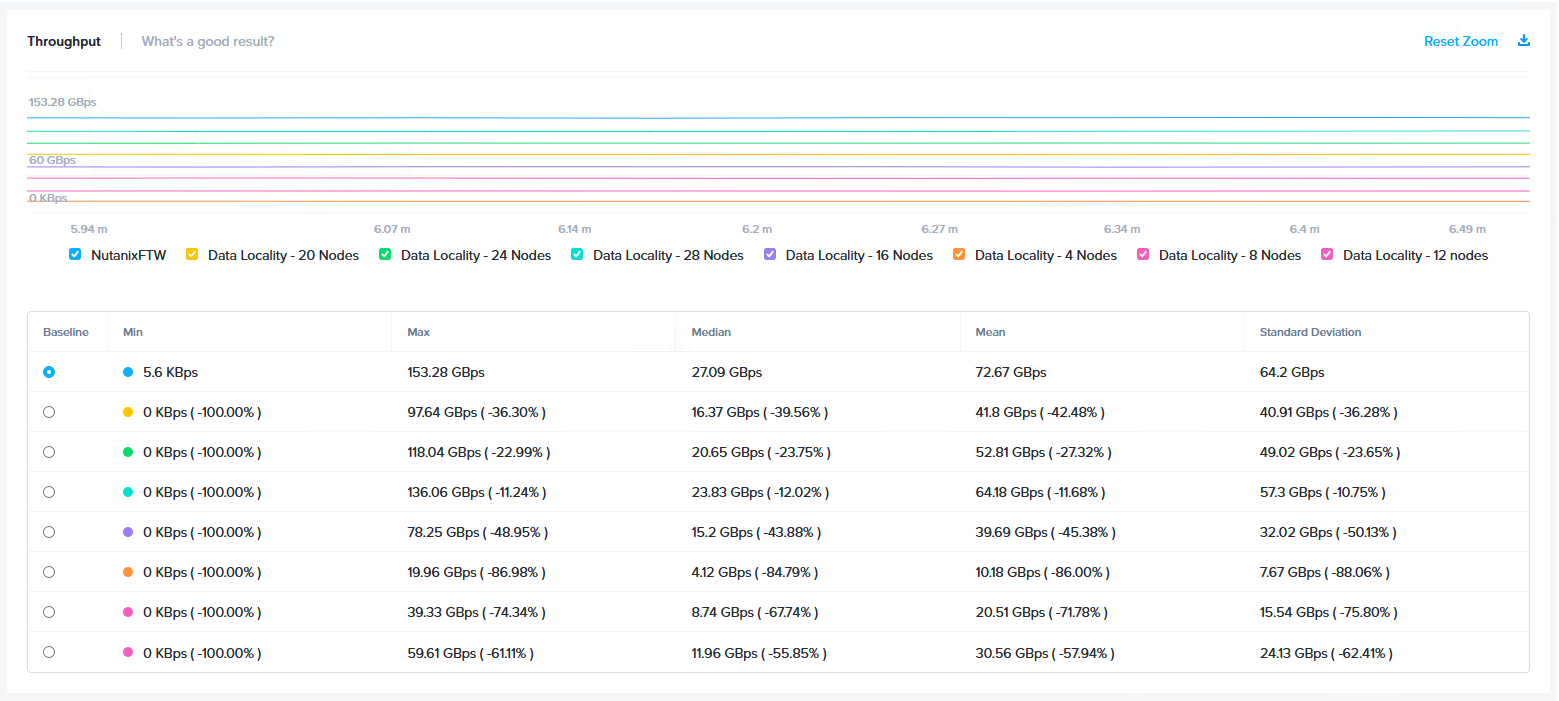
クラスターの拡張とパフォーマンスの向上が比例していますが、そのパフォーマンスレベルは驚異的なものであることが分かります。
この結果は、VMをクラスター全体に渡って分散させることで達成されているということに着目していただければと思います。Nutanixでこのような高パフォーマンスが達成されるのは、新規データが常にローカルに書き込まれて、以降の読み取りが常にローカルに実行されるためです。
19.96GBpsのスループットを達成した4ノード(オレンジ)を例に挙げます。このスループット値は159Gbpsのネットワークトラフィックに相当しますが、4つのノードで使用できるのはそれぞれ1個の25Gbps NICだけであるため、仮にAWS EC2で25Gbpsが常にすべて使用可能だったとしても、データローカリティなしではこのレベルのパフォーマンスを達成するのは現実的に不可能です。
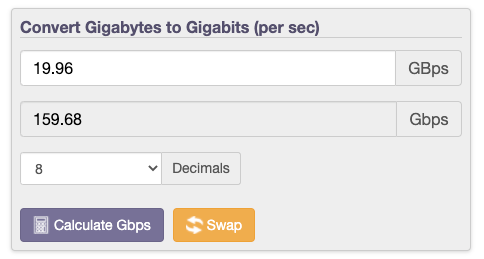
25Gbpsが100%使用可能であると想定しても、ノード当たりのストレージスループットは最大3.125GBpsであり、この場合に4ノードで達成されるパフォーマンスは、Nutanixで達成された19.96GBpsに対して12.5GBpsと低くなります。
AWS EC2のi3.metalホストではすべてNVMeが使用されており、ネットワークに依存するアーキテクチャーの場合はハードウェアの使用効率が低くなるため、TCOの増加やROIの低下が生じます。
Nutanix AOSでは、データローカリティを使用することで、ネットワークの使用をゼロに抑えつつ、19.96GBpsを達成しているのです。
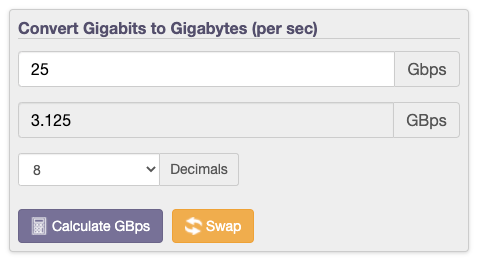
AWSでの実際のネットワークの制限や、ネットワークパフォーマンスに影響を及ぼす要因(例えば、VMware NSXなどのオーバレイテクノロジー)を考慮すると、達成可能なストレージパフォーマンスは大幅に低くなります。
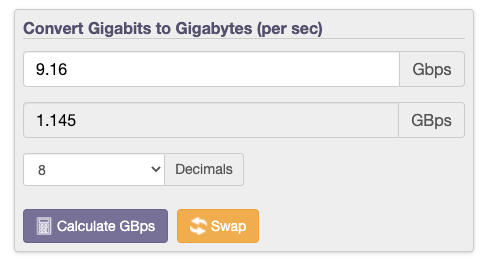
例えば、上記のiPerfのテストでは、データローカリティなしの場合、パフォーマンス最高値は9.16Gbpsであり、ノード当たりわずか1.145GBpsのストレージトラフィック(読み取りおよび書き込み)しか達成できません。
書き込みI/Oでの仕様
Nutanixのデータローカリティを使用すると、1個のレプリカがVMにローカルに書き込まれるため、ネットワーク帯域幅はまったく使用されません。2番目のレプリカのみがネットワーク経由で書き込まれるため、論理上の最大書き込みスループットは使用可能な帯域幅と同じになります。
データローカリティなしの場合、両方のレプリカをネットワーク経由で送信する必要があるため、論理上の最大書き込みスループットは使用可能な帯域幅の半分にまで低下します。
VMware Cloud on AWS(VMConAWS)を使用し、仮想マシンをホスト(仮想マシンのストレージオブジェクトをホスト)から移行する場合、すべてのネットワーク帯域幅がストレージ専用であると想定しても(当然ながら、専用ではありません)、VMCの最大書き込みスループットはNutanixの半分になります。
ネットワーク競合が発生した場合は
Nutanixでは、データローカリティが適用されるため、ネットワークへの依存が最小限に抑えられます。そのため、仮想マシンやレプリケーション、vMotionに最大限の帯域幅が使用可能です。また、デバイスやノードに障害が発生しても、クラスターは再構築がタイムリーに行います。
VMwareが提供しているVMConAWSなどの製品はデータローカリティ機能を備えていないため、使用可能なネットワークに大きなばらつきがあり、このようなネットワークを介して機能、回復力、およびパフォーマンスを確保するのはほぼ不可能です。
このことに加え、vSAN(VMware Cloud on AWSの基盤となるストレージ)では回復力とスケーラビリティに問題があるため、VMwareでは、6つ以上のホストで構成されたクラスターにはFailures to Tolerate of 2(FFT2:許容される障害数2)を推奨しています。つまり、3つのデータコピーとなり、使用可能な容量は33%未満になります。
これに対して、「Nutanix vs vSAN/VxRAIL」シリーズのドライブ障害やノード障害に関する投稿で紹介しているように、NutanixにはvSAN(VMC)のような回復力の問題はありません。また、Nutanixでは、サポートされる障害シナリオやアップグレード時を含め、書き込みI/Oの整合性が常に維持されますが、vSAN/VMCでは、デフォルトではこれに対応していません。
vSANおよびVMCでアップグレード時の書き込み整合性を取るためには、全データの退避モードを使用する必要があります。このモードを使用すると、環境の容量要件がN+1以上に増加するため、この容量を使用している間は、パフォーマンスが大幅に低下し、アップグレードにも大幅な影響が生じます。
ただし、このモードは、ドライブやノードに障害が発生した場合に書き込みデータの整合性が維持されないという、vSAN/VMCの重大なリスクに対応していません。
まとめ:
Nutanix Clusters(AWSでAOS)とVMware Cloud(AWSでVMC)を比較すると、この2つの製品はネットワーク要件やネットワークへの依存の点でまったく異なる製品であるのが明らかです。
Nutanix AOSアーキテクチャーでは、パブリッククラウド環境で生じると想定されるリスクの軽減のため、ネットワークへの依存を最小限に抑えています。それに対して、vSAN/VMCでは、いずれもネットワークに(特に大規模ネットワークに)大きく依存する不完全なアーキテクチャーであり、ネットワーク帯域幅はほぼ制御不能かつ大きくばらつく環境として実装されてしまいます。
Nutanix Clustersは標準でラック障害に対応していますが、データローカリティのおかげでネットワークの影響をそれほど受けない実装になっています。それに対して、VMwareのVMCでは、ラック間の帯域幅が5Gbpsに制限されるため、特に保守時、障害発生時、およびワークロードのピーク時に影響が生じます。
Nutanix ClustersとVMCで、8ノード環境を使用するとします。Nutanixでは2つのレプリカを使用し、常にデータ整合性が維持されるのに対して、vSAN/VMCでは3つのレプリカを使用し(VMwareがそのように推奨しています)、単純なドライブ障害やノード障害の場合でさえ、書き込みの整合性は維持されません。アップグレード時にデータ整合性を維持するためには、全データの退避モードを使用する必要があるため、容量要件も増加します。
これに加えて、vSAN/VMCでは、オブジェクトを1つのノードから別のノードにリストアするという概念的な欠陥があり、リビルドに長い時間を要します(対照的に、Nutanixのソリューションは完全分散型です)。vSANは、本番ワークロードでの利用時は特に、パブリッククラウドで使用するアーキテクチャーとしてはいまひとつ魅力に欠ける商品と言えるでしょう。
次は、パブリッククラウドの課題 – パート2:TCO/ROIとストレージ容量 をご覧ください。