

本記事はJosh Odgers氏が2020年8月17日に投稿した記事の翻訳版です。
パート1では、AWSでVMwareのVMC製品を使用する場合、VMwareやその顧客はネットワーク帯域幅を制御できないという、VMCのコアアーキテクチャーが及ぼす重大な影響について紹介しました。また、(オンプレミスの顧客が使用しているのと)同じAOSエンタープライズクラウドソフトウェアをベースとするNutanix Clusters製品で、Nutanix固有のデータローカリティ機能のメリットが得られることを紹介しました。この機能によって、ネットワークへの依存を最小限に抑えてネットワークリソースを解放できるため、ストレージや仮想マシンのパフォーマンスが向上し、クラスターの回復力や機能も強化されます。
パート2とパート3では、AOSの機能によって、VMCよりも高いフロントエンドパフォーマンスを発揮しながら、使用可能な容量も多くなることを説明し、その結果としてNutanixで得られるTCO/ROIのメリットについて紹介しました。
このようなメリットが得られる要因として、Nutanix AOSの卓越したイレージャーコーディングが挙げられます。また、Nutanixの高度な分散ストレージファブリックによって、レガシーな「キャッシュ+キャパシティ」アーキテクチャーを使用するVMC(vSANベース)のディスクグループよりも使用可能な物理容量が多くなることも挙げられます。
このパート4では、VMwareのVMC製品とNutanix Clusters製品がそれぞれ備えているデータ効率機能について紹介し、AWSを使用した本番環境でのこれらのメリットと影響について明らかにします。
Nutanix ADSFとVMware vSANの重複排除と圧縮の比較に関する投稿で、両方の製品が3つの主要なデータ効率テクノロジー(圧縮、重複排除、イレージャーコーディング)を備えていることを紹介しました。これらのテクノロジーは、表面上は同じように思えますが(以下の表を参照)、詳細は大きく異なります。

また、これらのテクノロジーを有効にする場合、vSAN(VMCのベース)ではクラスターレベルの設定が「オールオアナッシング」であり、柔軟性が非常に低いことも紹介しました。
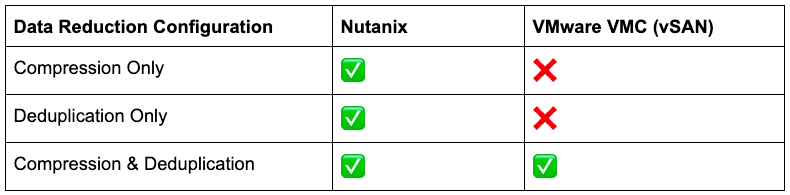
VMCの顧客は、圧縮と重複排除を有効にするか、または両方を無効にするしか選択できません。
今では広く認識されていますが、圧縮と重複排除(およびイレージャーコーディング)にはそれぞれ長所と短所があるため、すべてのワークロードにすべてを適用するのが最適という場合は極めてまれです。
Nutanix AOSではデータ効率テクノロジーをすべてのデータに適用できますが、VMC(vSAN)では「キャパシティ」層にしか適用できないため、全体的なデータ削減率が小さくなります(その結果、GB当たりのコストが高くなります)。

VMCでは、標準仕様の場合は使用可能な物理容量がNutanix Clustersよりも少なくなることを考慮すると、データ効率テクノロジーが適用されるデータも少なくなります(キャッシュ層には適用されません)。また、すべてのデータに強制的に適用されるため、Nutanixと比較すると魅力的とは言えません。
また、VMwareのVMCには落とし穴があり、圧縮と重複排除を有効にすると、環境の回復力が低下します。
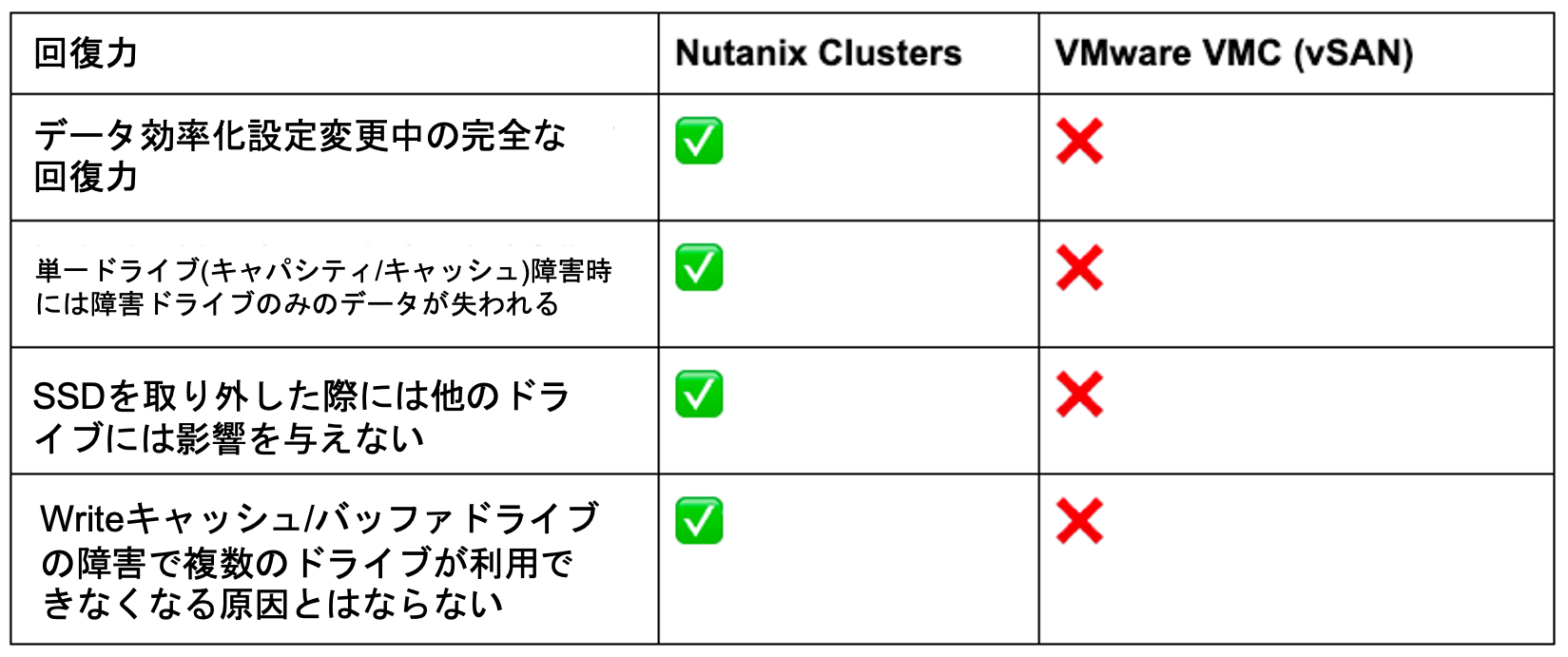
Nutanix Clustersでは、データ削減テクノロジーを任意の組み合わせで柔軟に有効/無効の切り替えができ、かつ、環境の回復力も低下しません。
VMC(vSAN)を使用する場合は、単純なドライブ障害でもリスクや影響が大きくなる(はるかに多くのデータがリスクにさらされ、リビルドが必要になる)ため、回復力が大幅に低下し、障害発生時に受ける影響が大幅に大きくなる、ということを顧客は受け入れる必要があります。
次に、VMCで単一ドライブ障害が発生した場合の影響について紹介します。1.9TB NVMeデバイス4つで構成されるディスクグループ全体がオフラインになるため、VMCの場合はネットワーク経由で最大7.6TBのデータをリビルドすることが必要になります。
Nutanix Clustersで同じ単一障害が発生しても、リビルドが必要になるデータは最大でも1.9TBです。つまり、影響は4分の1であり、VMC(vSAN)よりもリスクが大幅に小さいです。また、Nutanixの高速なリビルド機能によって、VMC(vSAN)よりも短時間でリスクが軽減されます。このため、そもそも、リビルドが必要になるデータが大幅に少なくなります。
また、このシナリオではそれほど目立ちませんが、リビルド時にフロンドエンドに及ぶ影響が小さくなり、短時間で通常のパフォーマンスレベルに戻るのもNutanix Clustersの利点です。
パート1で問題として取り上げましたが、AWS EC2で利用できるネットワークは限られている中で、VMware VMC(vSAN)はネットワークへの依存がNutanixよりも大幅に大きいため、本番ワークロード、ストレージ層、vMotion、およびクラスター操作(データ保護を目的としたリビルド、リバランス、レプリケーションなど)の間で競合が生じるリスクが高くなります。
まとめ:
AWSでVMware VMCを使用して圧縮と重複排除を有効にする場合、柔軟性に欠ける強制的なアプローチや、環境における回復力の低下について受け入れる必要があります。
つまり、発生した障害が比較的小規模であっても、障害の影響ははるかに大きくなって重大レベルの障害になり得ます。
同一の小規模な障害(ドライブの障害など)が発生した場合、リビルドが完了するまで、書き込みI/Oの整合性は維持されません。
Nutanix Clustersでは、回復力を低下させずに、圧縮と重複排除を柔軟に使用できます。小規模なドライブ障害が発生しても、データローカリティのおかげで、クラスターやネットワークへの影響を可能な限り最小限に抑えながら、障害を短時間で解決できます。Nutanixでは、ドライブ障害やノード障害の直後でも、I/Oの整合性が常に維持されます。
事実、Nutanix Clustersでは書き込みI/Oの整合性が常に維持されますが、VMCでは維持されません。この事実だけで、VMC(およびオンプレミスのvSAN)は実用的でないと判断する理由として十分でしょう。
パート5では、引き続き回復力という重要な側面について、およびVMCとNutanix Clustersの両方でドライブ障害がどのように許容されるかについて紹介します。