


This post was authored by Gabe Contreras, Enterprise Architect Nutanix
When discussing big data architectures, we are talking about how data is taken in, processed and consumed. This constitutes your big data pipeline. The architecture can vary greatly. For instance, take one of the most common architectures with Lambda, you have a speed processing and batch processing sides. Speed processing is more real time analytics and querying. Batch processing takes longer and is normally done at scheduled times for taking a deeper look over a longer period of time.
The components to build this vary greatly, it can be a choose your own adventure book with how you build your pipeline. Some of the components used are Kafka, Hadoop, Spark, Elasticsearch and Cassandra. All of these systems have one main thing in common, they are highly scalable. These components can grow in size as your needs grow to be able to handle large data flows. This scalable nature is what also makes Nutanix Enterprise Cloud a great platform to run your entire big data pipeline on.
Many companies have these systems deployed to date on bare metal servers as these software systems were designed to use commodity servers. Using bare metal was also optimal for fast data access of local data versus using SAN hardware for data storage. What many companies have realized though is that using bare metal can lead to long deployment and expansion lead times, high management overhead with multiple different silos and monitoring software.
Nutanix helps to simplify all of these pain points and lead to a single infrastructure with single pane of glass for monitoring, deployment and management. Our customers have found the following benefits when deploying these systems on Nutanix:
- Faster Provisioning
- Simplified Infrastructure
- Improved availability
- Greater flexibility
- Increased efficiency
Nutanix Overview
Nutanix delivers a web-scale, hyperconverged infrastructure solution purpose-built for virtualization and cloud environments. This solution brings the scale, resilience, and economic benefits of web-scale architecture to the enterprise through the Nutanix Enterprise Cloud Platform.
Attributes of this Enterprise Cloud OS include:
- Optimized for storage and compute resources.
- Machine learning to plan for and adapt to changing conditions automatically.
- Self-healing to tolerate and adjust to component failures.
- API-based automation and rich analytics.
- Simplified one-click upgrade.
- Native file services for user and application data.
- Powerful and feature-rich virtualization.
- Flexible software-defined networking for visualization, automation, and security.
- Cloud automation and life cycle management.
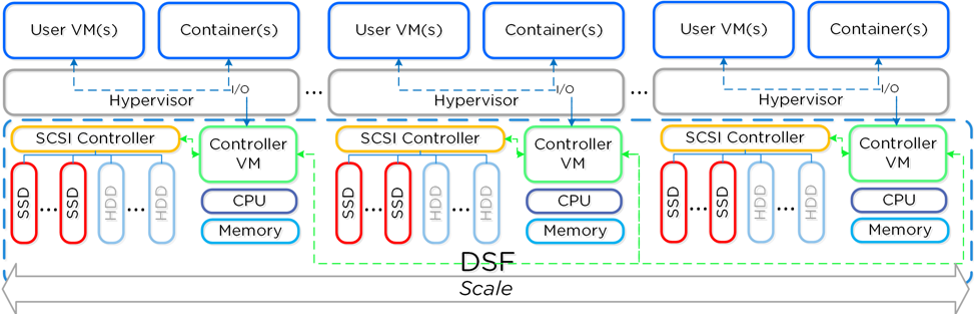
This highly scalable infrastructure with built in monitoring and management provides a holistic platform to be able to run all your software applications on a single platform, with a single monitoring and management pane.
Storage
When it comes to storage for big data pipelines each piece of software has its own unique profile. When it comes to Elasticsearch you need fast storage to be able to index and search large amounts of data in near real time, but that data is kept around possibly in the order of weeks or months. For Hadoop HDFS you may need to store large amounts of data for months to years but rarely access the older data. With Nutanix you have the choice of many different hardware types of All Flash, NVMe, Hybrid nodes with SSD and HDDs for deeper storage.
This means you can have all flash nodes for Elasticsearch, while using Hybrid nodes for Hadoop yet they are still all managed and monitored from a single interface without having to silo off pieces of infrastructure for each application.
Since we are an enterprise storage solution at our core, we also have space savings features such as compression and Erasure Coding (EC-X). While HDFS and Elasticsearch have their own compression algorithms we have still seen an extra 15-20% extra space savings on Nutanix due to looking at the entire dataset vs just a single node. With Hadoop and EC-X it is possible to achieve a 2:1 space savings for usable storage on Nutanix. With this space savings it shows you can achieve better uptime and data availability on the Nutanix platform without having to use more storage.
With the Nutanix platform you also get the best thing from deploying these apps on bare metal which is data locality. With our architecture one copy of data is written locally with the other copy distributed across the cluster. You still get fast local read times which becomes more important with even faster storage types becoming more common.
Performance for the storage can be something that can cause bottlenecks in an individual node that creates a cascading problem throughout a deployment on a bare metal application. With Kafka, if a Kafka partition replica starts falling behind this can be a problem because consistency is at risk in a failure. Troubleshooting why a replica is falling behind can take more work as is something wrong with a disk or possibly a hardware RAID card? With Nutanix not only is it easy to view statistics down to the latency and write characteristics on each individual disk but we also auto remediate problems.
If a single disk in a server is starting to go bad, it is having performance problems, we can mark the disk as bad, not use it anymore and alert for replacement. During this time all you lose is the amount of space of that disk but the data is still replicated without any admin intervention.This helps alleviate not only performance issues but management overhead for the time it would take for a person to manually troubleshoot and alleviate these types of issues.
Availability
Availability is of great concern when it comes to big data processing, especially when it is real time analysis. All of the big data software mentioned at the beginning have their own idea of a resiliency factor. How resiliency is achieved though is not equal.

With both Elasticsearch and Hadoop for instance you have to tune your rebuild throughput to make sure that during peak times you aren’t possibly causing problems and slowing down processing which can lead to greater instability. This means that even though you could have extra compute available during off peak times you are not rebuilding as fast as possible because of these hard limits.
This has to happen because each bare metal server is a separate resource, each disk or server is not monitored holistically. This is where Nutanix is different and helps lead to greater uptime and stability. Nutanix monitors all the servers as a whole and can look at the performance down to the individual disk level. When the cluster as a whole is busy, we can automatically throttle background tasks like data rebuilds as not to affect production systems. While during non-peak times we can up the resources used to complete rebuilds faster. Nutanix rebuilds are completely linearly scalable also.
As we break down the rebuilds into small extents and distribute across the entire cluster. The more nodes you have the faster rebuilds should be. With the Nutanix resiliency factor we can restart VMs quickly meaning Hadoop, Kafka or Elasticsearch nodes can be back up and running within only a couple minutes making sure to keep performance at its peak. For a more in depth explanation about this you can read my other blog post here.
Compute
When it comes to many of these scale out applications running them on bare metal leads to issues of underutilized compute and to compute silos for each of these applications. Aggregated overall and your data processing pipeline can be leaving massive amounts of compute underutilized leading to data center sprawl and lower ROI.
With Nutanix we can break down those individual silos combining the resources together to get better overall utilization and management. When you look at the architectures for Kafka and Elasticsearch they each have components that are storage heavy and storage light. With Kafka you have the brokers which can use large amounts of storage but consumers that are very storage light but need compute. While with Elasticsearch you have the Data nodes which are storage and compute heavy with Primary and Coordinating nodes which can be pretty light all around.
Mixing all of these applications together gets you better utilization and a better ROI. With automated management Nutanix also handles any possible compute bottlenecks by looking at all the hardware nodes and making sure that any individual node is not being overly utilized compared to the rest of the cluster. With being able to mix different types of nodes together in the same cluster you have the ability to choose compute heavy and storage light nodes in the same cluster as storage heavy compute light nodes. This gives you the flexibility to expand your cluster per your needs.
Management
When it comes to data processing pipelines and the applications that are used many customers don’t just have a single Hadoop or Elasticsearch or Kafka deployment. Many customers have multiple deployments of these elements for different use cases. This leads to management overhead as each of these deployments is managed and monitored separately. The management of all these nodes for firmware and other updates can become a major issue also.
With Nutanix and our 1 click upgrades you can upgrade server firmware and BIOS without any downtime for your applications with 1 click. With Prism Central you can monitor all of your big data applications from a single pane even grouping them together with tags so you can easily filter on a single Kafka deployment or a whole data processing pipeline deployment that could manage hundreds even thousands of servers.
One customer had 4 different Hadoop deployments spanning 420 hardware nodes with over 1,000 VMs. They were able to manage and monitor all of the deployments from a single point and filter down to the individual deployments by applying tags. The ability to monitor the entire data pipeline holistically from a single pane to instantly see how everything is acting together can greatly reduce troubleshooting efforts.
Prism Central helps not only centralize your management and performance monitoring but gives you the ability to plan for your future deployments with capacity planning. Being able to plug in resources needed for a new deployment and being able to see how much resources you currently have available and how much resources you might need to purchase helps cut down on planning time.
With Calm you can automate the deployment and scale out of your big data applications with Elasticsearch clusters deployed in minutes versus days or weeks.
The management simplicity does not just pertain to your big data applications either. Since you are able to have a true unified platform for all of your applications it greatly reduces management and planning overhead.
Elasticity
One of the most important things when talking about the data processing applications is elasticity. You must have an infrastructure that is easily scalable, fast to deploy and easy to manage. These are actually weaknesses of bare metal deployments. Many customers complain how long it takes to stand up new environments for applications like Hadoop and others.
The initial deployment and expansion can be time consuming and cumbersome. With Nutanix Enterprise Cloud those pain points are stripped away. With initial deployment time taking hours instead of days or weeks to get your compute and storage up and running. With automation run by Calm you can create blueprints to help you easily deploy and scale out new environments automatically. You can use spare capacity in your environment to immediately expand any of these applications since there are no individual silos that you have to plan for.
Elasticity isn’t just needed for these single applications though, you need a platform and architecture that can scale for all your business needs. With big data and other applications you might need a scalable NFS/SMB file server. Maybe you need a platform for Kubernetes plus an Object Store.
The Nutanix Enterprise cloud gives you not just a platform to deploy individual applications but a scale out architecture that helps your environment grow in a cloud like manner for all your application needs. You are able to use our Nutanix Objects for your scalable object store with Karbon to deploy your Kubernetes clusters. This gives you the ability to manage and scale out all of these platforms from a single pane and give back critical time to infrastructure and application teams.
We know that Nutanix is the best platform for big data pipelines as we use it ourselves for Nutanix Insights.
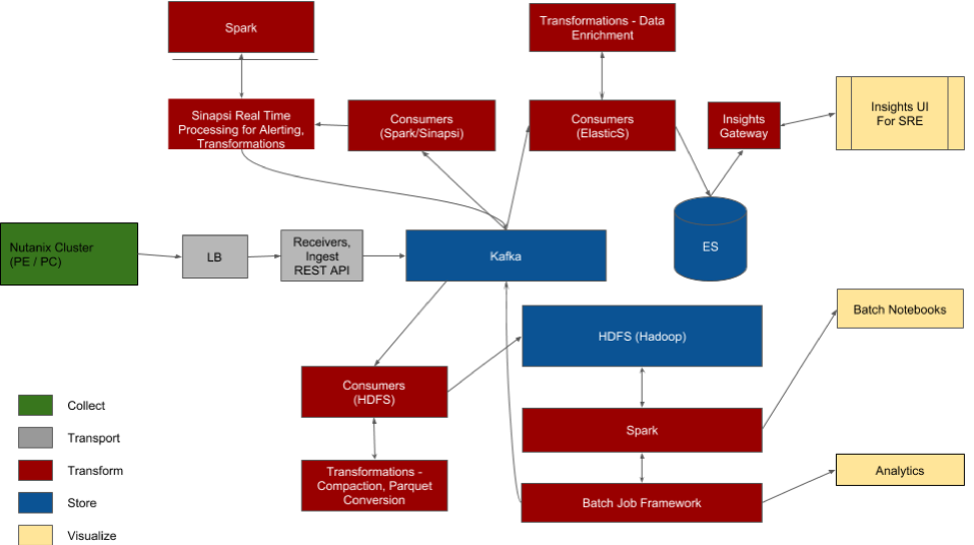
All components for Insights are virtualized on Nutanix. Built into our product as a core component is Cassandra also. We can scale out all the components as needed as the amount of clusters our customers deploy grows.
Conclusion
Nutanix Enterprise Cloud platform can help you easily deploy, manage and scale out your entire big data pipeline while simplifying your entire environment and giving you a better ROI. To see more in depth information on some of these components you can see how we use Nutanix Insights or deploying Hadoop and Elasticsearch on Nutanix.
© 2020 Nutanix, Inc. All rights reserved. Nutanix, the Nutanix logo and all Nutanix product, feature and service names mentioned herein are registered trademarks or trademarks of Nutanix, Inc. in the United States and other countries. All other brand names mentioned herein are for identification purposes only and may be the trademarks of their respective holder(s). This post may contain links to external websites that are not part of Nutanix.com. Nutanix does not control these sites and disclaims all responsibility for the content or accuracy of any external site. Our decision to link to an external site should not be considered an endorsement of any content on such a site.