


When it comes to running Elasticsearch on any platform getting the right settings can take time to get right based on your use case. Small throughput deployments may have been deployed in the cloud, but what about deployments processing millions of documents a minute? It’s no surprise that many companies run these larger deployments on bare-metal. Numerous Nutanix customers have made the leap to running Elasticsearch on our Enterprise Cloud. Our customers have found the following benefits:
- Faster provisioning
- Simplified Infrastructure
- Improved availability
- Greater flexibility
- Increased efficiency
- For Nutanix customers the ability to better manage and run big data applications and general server virtualization is a major factor.
- Eliminating the need to support multiple silos and deploy virtualization for these workloads allows them to get much better efficiency.
- The move to Nutanix helps application teams with availability including how Elasticsearch would recover from possible outages. We have been able to repeatably demonstrate the ability to optimize both Nutanix and Elasticsearch settings to make this optimal.
- The time for provisioning has been greatly decreased as there is no longer a wait time between procuring bare-metal and going through the provisioning steps.
The solution has been set up to keep at least 1 week of indexes, meaning at least 200TB of data total is stored. This also had to account for the millions of searches on this data a day. In this scenario, the data is streaming in to Elasticsearch from Kafka.
Elasticsearch is an IO intensive application and we designed for merging that is done which can create a substantial increase in IO and throughput.
Virtualizing Elasticsearch on Nutanix
Here is a summary of the environment that this Elasticsearch (ES)
2x 24 nodes clusters in separate racks (each rack--Nutanix and ES failure domain). Each cluster could run ES with other workloads
- Each cluster provides 230TB of useable storage with RF2
- 32 cores and 512GB RAM per Nutanix compute node
- RF2 on Nutanix

Elasticsearch VM Configurations
- 3 Manager Nodes
- 6 Ingest Nodes
- 90 Data Nodes
VM disk layout: 8 vdisks added into an LVM with a 1MB stripe totaling 3.4TB
We applied some settings to the Linux OS to optimize it to keep IO flowing to our storage subsystem.
- Max_sectors_kb = 1024
- nr_requests = 128
- vm.dirty_background_ratio = 1
- vm.dirty_ratio = 40
Elasticsearch Testing
Testing was completed with the same production Kafka data just redirected to the Nutanix setup. If you have deployed Elasticsearch (ES), you realize that your settings are tuned based on your workload but there are other settings that can be used to optimize search. Here are other settings we chose to change from defaults to take advantage of how Nutanix operates. The main settings we tuned are below.Indexing
- Index.refresh_interval = 600s
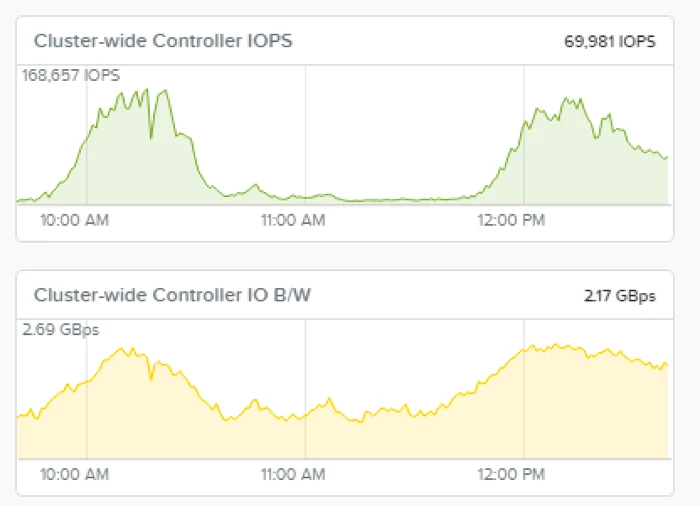
This graph shows when the merging begins. IOPS during normal ingest could be 10,000 IOPS for writes but when merging happens you can see the peaks of over 160,000 IOPS and throughput can double during the operation.
- Index.translog.flush_threshold_size =1024mb
by around 20%. Changing this setting has increased the time it might take to replay a single translog but the performance gain is worth it.
- Index.translog.durability = async
Overall Indexing as mentioned would average seven million documents per minute and could handle peaks up to 11 million documents at peak. With the average document level and 2Kb document size straight write throughput is around 12GBpm for primary data and 24GBpm for all indexing data. The Nutanix clusters had plenty of throughput to be able to handle the searches as well as the merge traffic shown above.
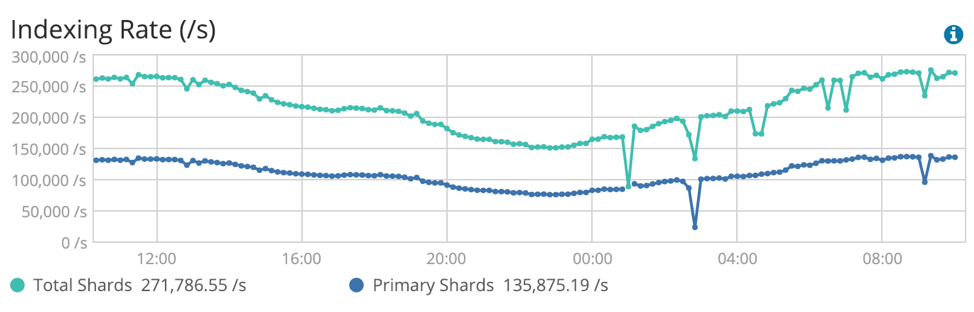
This image from Kibana shows the flow of traffic during the day. You can see how many documents the cluster is handling per second.
Search
There are no real recommendations aside from the normal search optimizations to do for your workload. Nutanix is a distributed scalable storage platform that gives you low latency reads like bare-metal due to data locality. Elasticsearch recommends local storage due to the latency requirements. With Nutanix’s data locality you get the low latency local reads that are needed when doing millions of searches a day.Failure Scenarios
- Index.translog.retention.size = 10gb
- Index.unassigned.node_left.delayed_timeout = 15m
These settings help take full advantage of Nutanix HA for this mission critical workload. The difference was when one of the bare-metal nodes would go down hard it would take hours for the Elasticsearch cluster to go green and have both copies of shards available again. While with Nutanix HA the inactive indexes are green within a couple minutes of the node going down and active index under 30 minutes.
This means for the bare-metal there was only one copy to search of the shards slowing down search times. This also adds IO and network activity as Elasticsearch only does a one to one copy to recover shards, meaning a node that has the primary copies to the new node which can take hours. Meanwhile with Nutanix recovering its second copy in the background, it takes significantly less time as the whole cluster contributes to the rebuild.
A common scenario for this customer was a bad drive causing issues in the cluster. To get the best performance RAID 0 was chosen for bare-metal nodes, one to get the best throughput but also because during RAID rebuild there would be IO degradation affecting the entire cluster.
In this scenario of a single bad drive bringing down nodes, Nutanix handles this much more gracefully. We have multiple checks in the Nutanix system so when we see degraded performance of a drive or we get SMART error messages predicting the drive might fail we will proactively stop using that drive or eject it from the system all together. This, unlike the bare-metal server, keeps the data nodes from failing or from a single node becoming a performance bottleneck.
Data Rebuild
As I mentioned before, the setup is single copy (RF2) at the Elasticsearch layer and RF2 on Nutanix with the Elasticsearch copies split between two separate clusters.The way Elasticsearch works when there is a failure and it has to create a new copy when one goes offline it is a straight one to one copy. If you have 10s of shards to rebuild these are one to one copies from the primary data node to the new secondary. Rebuilds of data are bottlenecked in this way as if the cluster as a whole is busy or the individual node it has chosen is busy then the recovery can be slow. During this time searches will be slower, and indexing could be hitting a bottleneck or at risk of data loss.
If a hardware node fails within the Nutanix cluster it realizes what data blocks need to be replicated to get back to green. With this scenario the entire Nutanix cluster participates in the rebuilding of data so no single node is being overtaxed on the rebuild and you have the distributed computing and IO power of the cluster. This means rebuilds are much faster even during heavier load. In this instance Elasticsearch also sees both copies of data to help keep search from being degraded.
Conclusion
When looking at the overall solution Nutanix makes great sense for combining your big data applications onto a single platform for better management and scalability. You can see from this example that you can also get the performance you need for even the most demanding workloads.For further information on running Elasticsearch, read the Solution Note on the Elastic Stack on Nutanix AHV -- https://www.nutanix.com/go/virtualizing-elastic-stack-on-ahv.php. You can also setup a briefing with our solution experts and services by sending us an email at info@nutanix.com.
Resources:
- Nutanix NEXT community thread on Elasticsearch: https://next.nutanix.com/server-virtualization-27/elasticsearch-on-nutanix-31873
- Getting Started with Elasticsearch -- https://www.elastic.co/webinars/getting-started-elasticsearch
- Nutanix Epoch documentation for Elasticsearch -- https://docs.epoch.nutanix.com/integrations/elastic/
© 2019 Nutanix, Inc. All rights reserved. Nutanix, the Nutanix logo and the other Nutanix products and features mentioned herein are registered trademarks or trademarks of Nutanix, Inc. in the United States and other countries. All other brand names mentioned herein are for identification purposes only and may be the trademarks of their respective holder(s).