


This post was authored by Gabe Contreras, Enterprise Architect Nutanix
With many big data applications like Elasticsearch, one question that invariably comes up is “Why have RF2 at the Elasticsearch layer and still have to do RF2 at the Nutanix layer?”.
There are many reasons operationally why you would want Elasticsearch on Nutanix, especially with AHV, rather than on bare metal. Those operational reasons such as not having application silos, leveraging spare compute and storage, having a single pane for all your workloads and supporting a single platform all lead to operational efficiencies, especially at scale. These help you turn your big data deployments into a private cloud for all applications and lets you use spare capacity for workloads such as extra compute to run kafka consumers and producers.
There are also space saving features such as compression and EC-X on Nutanix. While Elasticsearch does have compression since it is contained per data node, Nutanix gets even more compression savings. For this post we will focus on the single technical question about RF levels when you have an application that has the capability of doing its own RF, with focus on Elasticsearch. These nuances play directly into resiliency and especially on how each platform handles rebuilds during failures.
First let’s go over two main deployment patterns I see with customers doing bare metal deployments with their production mission critical Elasticsearch workloads. These workloads are almost always on all flash. The first is relying only on Elasticsearch for resiliency. This means bare metal nodes in a RAID 0 configuration to get maximum performance from each individual node, but with Elasticsearch set to RF3. This means one original with two copies. The other is creating more node resiliency. This means RAID 10 on the node and RF2 on Elasticsearch. With RAID10 configuration you will not need to rebuild entire nodes of data for a single disk failure.
The other reason for multiple copies on Elasticsearch is for search parallelization. Unless you are doing a very heavy amount of searches, for many customers one primary and one copy is normally enough for fast searches. This points to the fact that the copy structure of Elasticsearch is more about resiliency. With Elasticsearch, you can apply what is called node or rack awareness for RF resiliency, which would correspond to how we recommend our customers build Elasticsearch on Nutanix for large deployments. You would use the id setting to split evenly the Elasticsearch nodes between two separate Nutanix clusters to build resiliency across racks or availability zones.
We will go over the main failure scenarios to show how each platform handles those failures and how Nutanix does it better.
Prolonged Node Failures
The first scenario is a complete server hardware failure where the node could be down for days until a part is replaced. Elasticsearch has the setting index.unassigned.node_left.delayed_timeout which the default for this setting is one minute. In a bare metal world many customers leave this at the default because if a node fails, they want the rebuild to start as quickly as possible. But some put this as a delay of 5 minutes or so to give a little extra time. Elasticsearch will wait for this threshold to be met and then start reassigning the shards for rebuild.
The rebuild is accomplished at the per shard level. For large deployments you may have designed for your shards to be a max of 50GB. So, if you have 100s of shards that need to be rebuilt each one is a one to one copy, one node has the primary and it will copy that data to the newly assigned secondary. So, depending on how busy your nodes are it can be slower due to this behavior. If you happen to have one node that is the primary for 3 shards that will need to be rebuilt, then it will be a 1 to 3 copy for this rebuild.
This can lead to hotspots in your environment, this can slow down indexing, and can slow down searches as more resources are taken by the rebuild process and there are less copies to be searched. If this occurs during your peak times, it can lead to poor user experience or possibly other failures. When we looked at customers production workloads, rebuild times with all flash bare metal clusters were 8 hours or more until the cluster was healthy. During peak times the rebuild could increase to more than 16 hours.
The rebuild process and rate is controlled by Elasticsearch. While the rebuild is happening in the background, the data durability is compromised. It is possible to tune how fast Elasticsearch can rebuild data but you have to also plan for your peak workload. So, if you plan for peak then during off hours with spare capacity to rebuild, the rebuild speed is artificially limited.
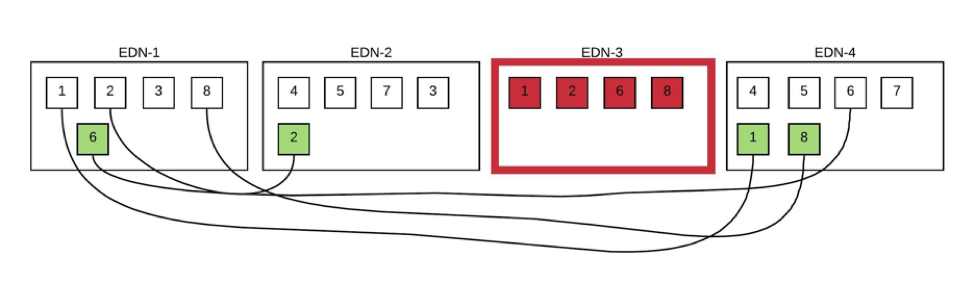
In the above data node failure scenario, there is a hot spot on data node 1 during rebuild, because it has 3 of the 4 shards that are required to have new copies rebuilt. Plus the cluster needs to keep itself as balanced as possible so it will copy one shard to node 1.
Let’s look at that same scenario with Nutanix as the underlying platform instead of bare metal. For the index.unassigned.node_left.delayed_timeout , we want it set to 15 minutes because on Nutanix we expect the VM to recover and come back up instead of expecting it to stay down and don’t want Elasticsearch prematurely rebuilding. We also use one other setting “index.translog.retention.size”. The default for this setting is 512mb, and we set it to 10gb. This helps during failures to perform an operation based sync which is much quicker than doing a file based sync. In the Nutanix cluster we get a physical hardware failure where an Elasticsearch data node was.
Within only a few minutes the VM will restart on another node and as long as you have the Elasticsearch service set to auto start then the node will be recognized as back up by the master node. Since the data nodes has only been down a couple minutes, any non active ingesting indexes will turn green almost immediately and will be healthy. Actively ingesting indexes will be evaluated, but should use the settings that we have changed and mark all the shards as green within 10-15 minutes. Elasticsearch will show that you have a completely healthy cluster at the application level in under 20 minutes This means you will have both copies available to search.
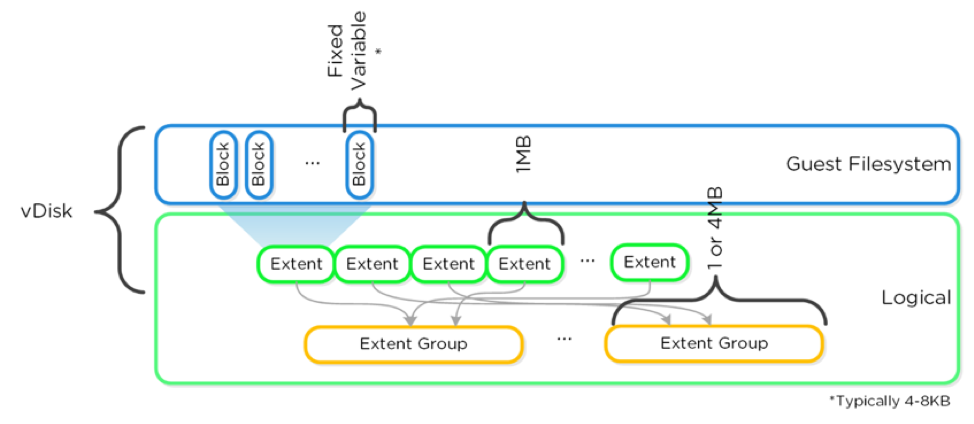
Now, what happens on the Nutanix side to rebuild that data? At our storage layer we store data in what is called extents. Our extents can be either 1MB or 4 MB. The storage has no idea that your shard is 50GB and doesn’t care, it has broken that down into 1MB extents. Because of data locality, we keep one copy local and the other extents are distributed across the rest of the Nutanix cluster. Let’s say we have a 32 node cluster where this hardware node failed, you are now left with 31 nodes.
All 31 nodes will participate in this rebuild, and that same 50GB shard split into all those 1MB extents has the capability to use not just all 31 nodes for the rebuild, but every drive in the cluster. Since this rebuild is completely distributed there is less likelihood for any hot spots and will be less likely to interfere with your production workload. This truly distributed rebuild also meant we rebuilt the missing data faster. With the same amount of data as the customers bare metal node, we rebuilt the data in 3 hours or less. During this rebuild your application was completely healthy and did not have to be aware of rebuilds while having the same performance as before the failure.
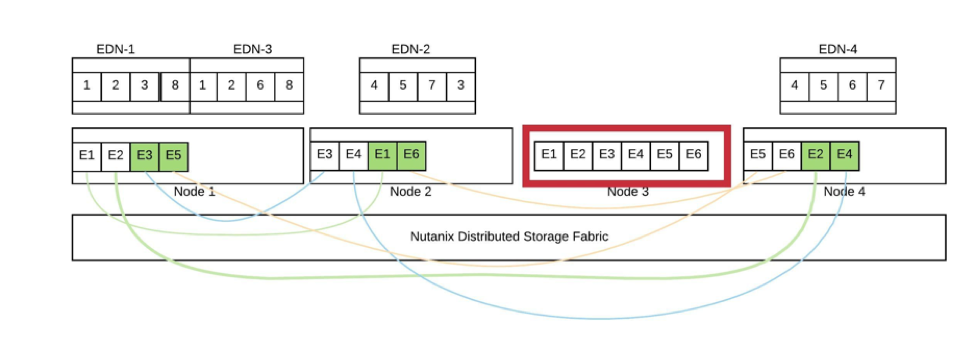
In the above diagram, Elasticsearch virtualized on Nutanix, we are breaking a shard down into extents annotated by E#. In this failure, the Elasticsearch data nodes are all healthy and the cluster would be displayed as green. While at the Nutanix layer the extents that had a primary copy on Node 3 are rebuilt. The copies of those extents were evenly distributed across the cluster and the rebuild is evenly distributed. Since we break the shards down into smaller storage extents it is much easier to balance during rebuild then with 50GB shards.
Let’s look at the other type of failure, a transient failure. For this failure we will say the hardware had a failure and was down for 20 minutes. What happens on the bare metal? Again, the node_left threshold is hit and Elasticsearch starts the rebuild process and starts assigning shards for rebuild. After 20 minutes that node comes back online, but rebuild has already started so the master node marks all the shards on that node as outdated and deletes them. Now that node is completely healthy, but online and added back in the cluster. In the bare metal environment you will have to go through the entire rebuild process, but you will now be adding on another task.
When the rebuild is complete and the cluster is healthy it will be unbalanced because there is a node that has no shards on it. Now the cluster has to rebalance and start copying shards to that node. For a single transient failure there is possibly many hours of extra IO being spent rebuilding then rebalancing, which again can lead to hot spots. You can tune rebuild and rebalance to throttle it, but it is a manual process. You have to take time to look at statistics and plan for peak times instead of it being dynamic and being able to complete rebuilds and rebalancing based on load.
Transient Node Failures
Let’s look at how Nutanix handles this same transient failure. Again, everything is the same as the long term failure in the Nutanix scenario above. The data nodes will restart and should be green very quickly. However, the backend Nutanix storage is different compared to how Elasticsearch would handle this. Nutanix will start the rebuild of data immediately, but the difference is when the node comes back online during the rebuild. Since the node was down just 20 minutes, only a portion of the data has been rebuilt. We will scan the Nutanix node and see if the extents are still relevant.
If they are relevant, then we will stop the rebuild and admit those extents back into the cluster and list the node as healthy. What about the extents that were already rebuilt? Well, we know that there are now some extents with three copies and we will go ahead and mark that third copy for deletion on the next curator scan. Because of how we handle this transient failure, we have stopped the need for rebuilding terabytes of data and the need for rebalancing. This has saved hours of extra IO and possible application performance degradation.
There are of course other failure scenarios that are helped by the Nutanix file system, such as the difference between our software and RAID. Drive failures on Nutanix do not need an immediate replacement to be able to rebuild data, unlike RAID 10. Also, the problem of RAID rebuilds being slow and normally severely impacting server performance do not affect Nutanix as our rebuilds are distributed across all nodes and disks.
This shows that along with the operational efficiencies, Nutanix can provide a more consistent performance experience for Elasticsearch, even during failures.
 2019 Nutanix, Inc. All rights reserved. Nutanix, the Nutanix logo and the other Nutanix products and features mentioned herein are registered trademarks or trademarks of Nutanix, Inc. in the United States and other countries. All other brand names mentioned herein are for identification purposes only and may be the trademarks of their respective holder(s).
2019 Nutanix, Inc. All rights reserved. Nutanix, the Nutanix logo and the other Nutanix products and features mentioned herein are registered trademarks or trademarks of Nutanix, Inc. in the United States and other countries. All other brand names mentioned herein are for identification purposes only and may be the trademarks of their respective holder(s).