

本記事はNutanixのTechnical Marketing EngineerのMike Umpherysが2022年9月8日に投稿した記事の翻訳版です。
原文はこちら。

一つ前の記事では、Nutanixがネイティブに提供するきめ細やかで効率性の高いスナップショットのテクノロジーと、Nutanixのスナップショットの実装の違い、それがなぜ差別化要素になるのか、ということについて取り上げました。今回の記事では、Nutanixプラットフォームにビルトインされたネイティブのエンタープライズグレードのレプリケーションとディザスタリカバリ(DR/災害復旧)オーケストレーションのメリットについて取り上げたいと思います。
レプリケーション
はじめから、Nutanixはプラットフォーム内にきめ細やかなレベルでのレプリケーションを含めていました。我々はこれをエクステントベースのレプリケーション(EBR – Extent-based Replication)と呼んでおり、ストレージのエクステントの範囲で動作しています。エクステントの1つは1 MBの論理的な連続したデータのブロックです。しかし、64 KBの変更データのみを転送したいという場合にはどうなるでしょうか? AOS 6.5 Long Term Support(LTS)以前ではプラットフォームは変更データを含む1 MBのエクステント全体をリモートへとレプリケーションし、リモートシステムは必要ではない部分を切り捨てていました。例えば、100の異なるエクステントでそれぞれ 16 KBの変更データが有った場合、ターゲットクラスタに対して 100 MBのデータを転送する必要がありました。
AOS 6.5 LTSには、完全に新しいレンジベースレプリケーション(RBR – Range Based Replication) が含まれており、Nutanixプラットフォームはこれ以降、新規、もしくは更新されたデータの範囲のみをレプリケーションすることが可能になりました。上の例でRBRを利用したとすると、100MBではなく、スナップショットは1.6MBになります。我々の検証によると最大9のスナップショットを利用して、4つの異なるデータの変更率を利用した場合、レプリケーションされるデータを最大で63%削減できるという結果になりました。さらに、すでにターゲットクラスタ内に存在するデータについてはネットワークを利用することがなく、バンド幅の削減効果もあります。これによって、お客様は必要とするRPOを維持し、DR計画からリスクを取り除くことに役立ちます。RBRについて更に詳しく知りたい場合、私のレンジベースレプリケーションの記事を確認してください。
Nutanixのレプリケーションはポリシーベースでお客様が失っても構わないデータの最大値である復元目標点(RPO)ごとに定義されます。RPOはもしも障害が発生した際に、最も古い受け入れ可能な時点を定義します。これは管理者がスナップショットの間隔とレプリケーションの間隔、そしてレプリケーションのターゲット(複数可)を指定する保護ポリシーを通して行われます。例えば、ACME Incではシステムに対して、2時間以上のデータロスは許されません。管理者はスナップショットとレプリケーションのスケジュールを2時間に設定します。これはつまり、最新のスナップショットからのデータの復元が発生した場合、データロスは最大で2時間になるということです。
サポートされているRPOについてそれぞれ見ていきましょう:
- 非同期レプリケーション(Async) – 60分かそれ以上のポリシーのRPOについては非同期ということになります。これはつまり、スナップショットは最低60分ごとに取得されるということです。これらのスナップショットはローカルに保持され、1つまたは複数のクラスタへとレプリケーションされます。
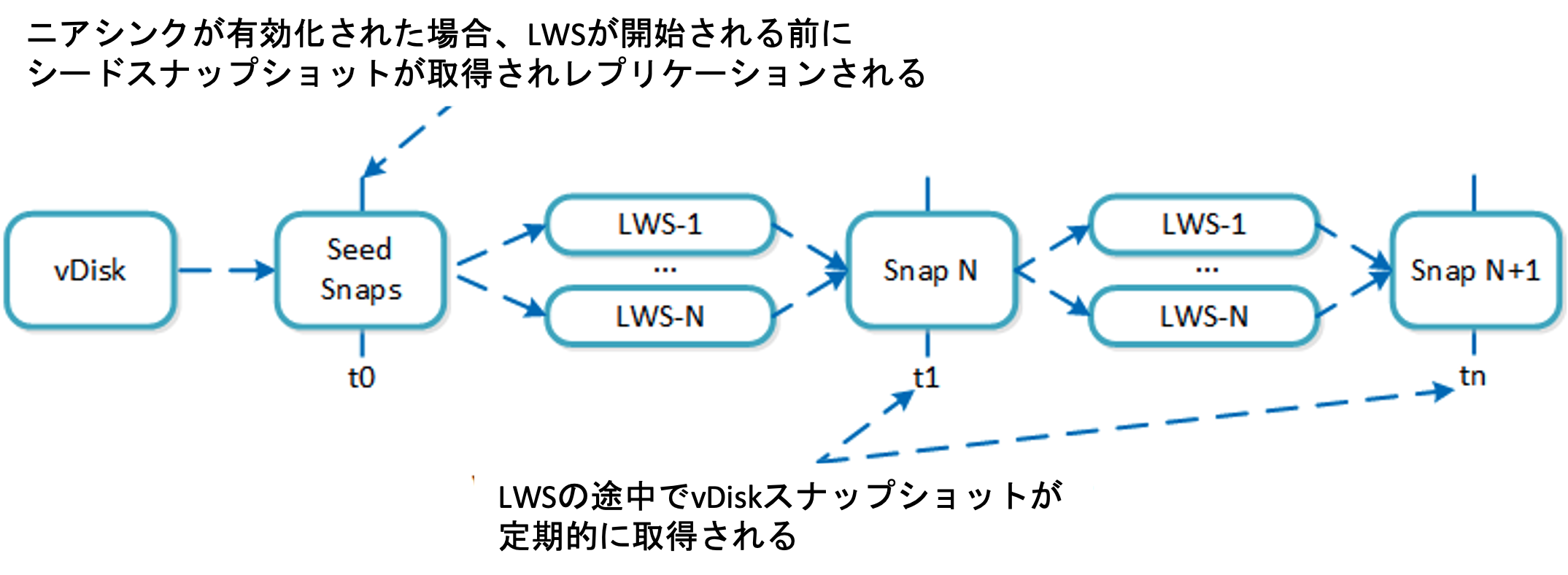
- ニアシンクレプリケーション(Near-Sync) – 1分から15分の間で構成されたポリシーのRPOはニアシンクということになります。ESXiではvStoreベースの20秒のRPOのレプリケーションも提供しています。ニアシンクではlight-weightスナップショット(LWS)と呼ばれる新しいスナップショットテクノロジーを利用しています。従来からの非同期のvDiskベースのスナップショットとは異なり、LWSはエクステントストア内で行われるvDiskのスナップショットではなく、マーカーを利用して完全にOpLogベースで行われます。このアーキテクチャによってLWSは高度な拡張性と性能を実現できます。LWSは継続的にリモートサイトへとレプリケーションされます。直近の毎時間のスナップショットを作成し、それを6時間保持してRTOを手助けするチェックポイントとして提供します。
- 同期レプリケーション(メトロ可用性/同期) – RPOを0分で定義するポリシーは同期レプリケーションとして取り扱われます。同期レプリケーションでは、仮想マシンの細やかさでゼロRPOを実現します。同期レプリケーションではサイト間のネットワークのラウンドトリップタイムは5ミリ秒未満でなければなりません。アプリケーションの継続的な可用性とゼロデータロスを実現するため、仮想マシンのデータ、仮想マシンのメタデータ、そして仮想マシンに適用された保護ポリシーのコピーは2つのクラスタ間で複製が行われます。これでデータロスがサイト障害においても発生しないことが確実になります。同期レプリケーションは仮想マシンのライブマイグレーションも実現し、サイト間で容易に行うことができます。
ディザスタリカバリ(DR)オーケストレーション
ディザスタリカバリは障害が発生した際に、顧客が最大で失うことを許容するデータの復元目標点(RPO – Recovery Point Objective)と復元の操作を行うための時間である復元目標時間(RTO – Recovery Time Objective)で評価されます。ディザスタリカバリソリューションはデータレプリケーションとリカバリオーケストレーションを組み合わせたものになります。
Nutanixのディザスタリカバリとオーケーストレーションはポリシー駆動型アプローチをベースとしており、スナップショットのスケジュールの構成、レプリケーション、フェイルオーバーオーケストレーションからなっています。これによって、災害が発生した際に再現可能な運用を保証します。
Nutanix Disaster Recoveryの内部のいくつかの構成について見ていきましょう:
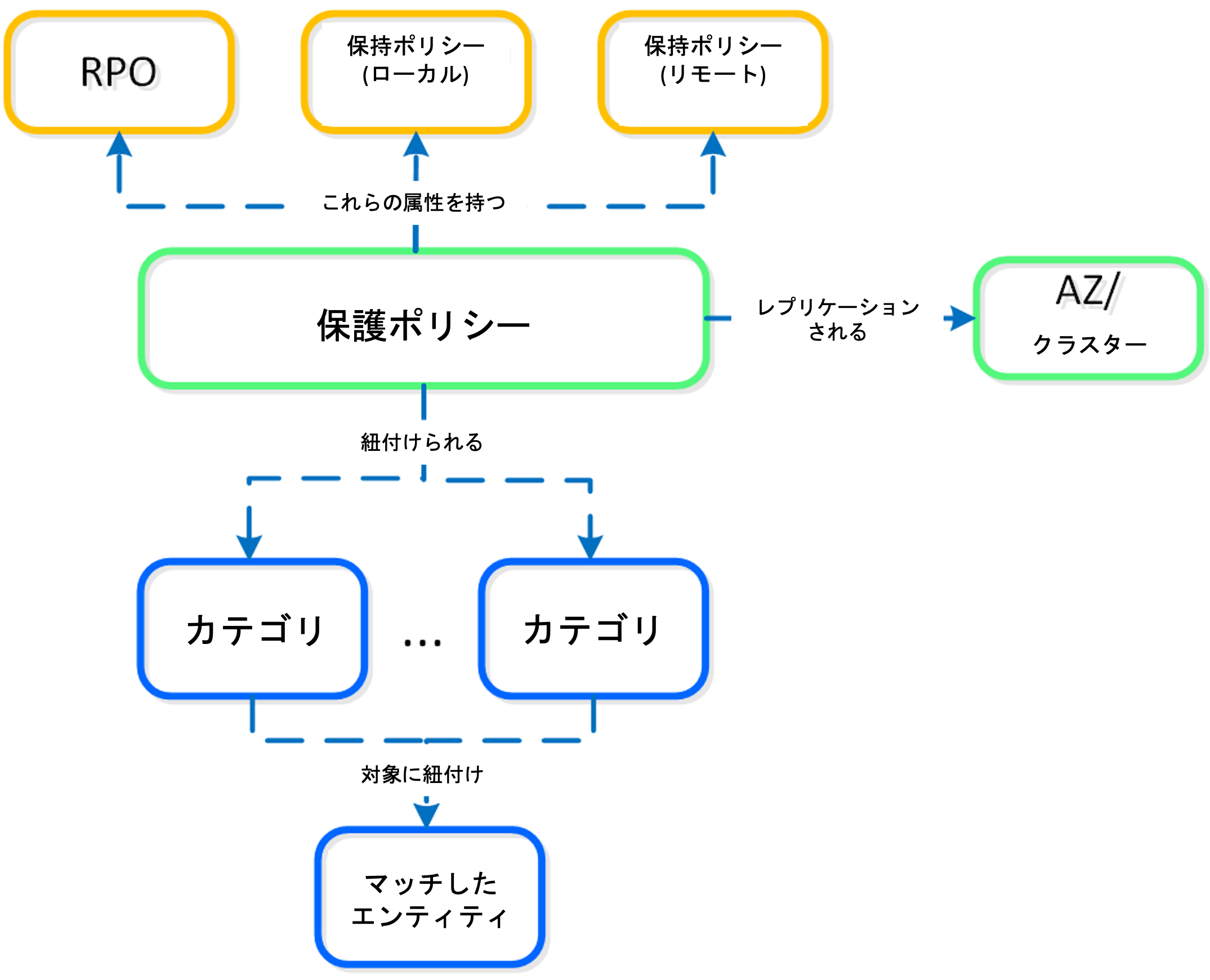
- アベイラビリティーゾーン– (AZ) は災害イベント時にフェイルオーバーを行うための物理的に分離されたインフラストラクチャーの論理的なグループです。2つのPrism Centralを接続することで、複数のAZをペアリングしておくことによって、カテゴリ、DRポリシー、そして他に仮想マシンのメタデータを共有しておくことで実現されます。ペアリングされたAZ同士は片方のAZまたはPrism Centralから他のAZへのフェイルオーバーが実現されます。
- カテゴリ ― シンプルなテキストベースのタグを利用した仮想マシンの論理的なグループです。例を上げると、アプリケーションのグループ、RPO、または他の仮想マシンの特徴に共通する属性などをラベルとしてカテゴライズすることができます。
- 保護ポリシー – RPO(スナップショットの頻度)、リカバリの場所(リモートクラスタ)、スナップショットの保持期間(ローカル 及び リモートクラスタ)、そしてそれに紐付けられるカテゴリを定義します。Nutanixはニーズに合わせたきめ細やかなスナップショットの保持をリニアもしくはロールアップポリシーとして実現しています。リニアの保持ポリシーでは保持しておく復元ポイントの数を指定します。例えば、RPOが1時間で保持数が6にセットされている場合、システムは直近の6時間の復元点を維持します。ロールアップ保持ポリシーはRPOと保持期間に応じてスナップショットを「ロールアップ」します。例えば、RPOが1時間で保持期間が5日に設定されていた場合、1時間毎の復元点を1日分、日時の復元点を4日分保持します。保持ポリシーについてのさらに詳細はNutanixバイブルをご参照ください。
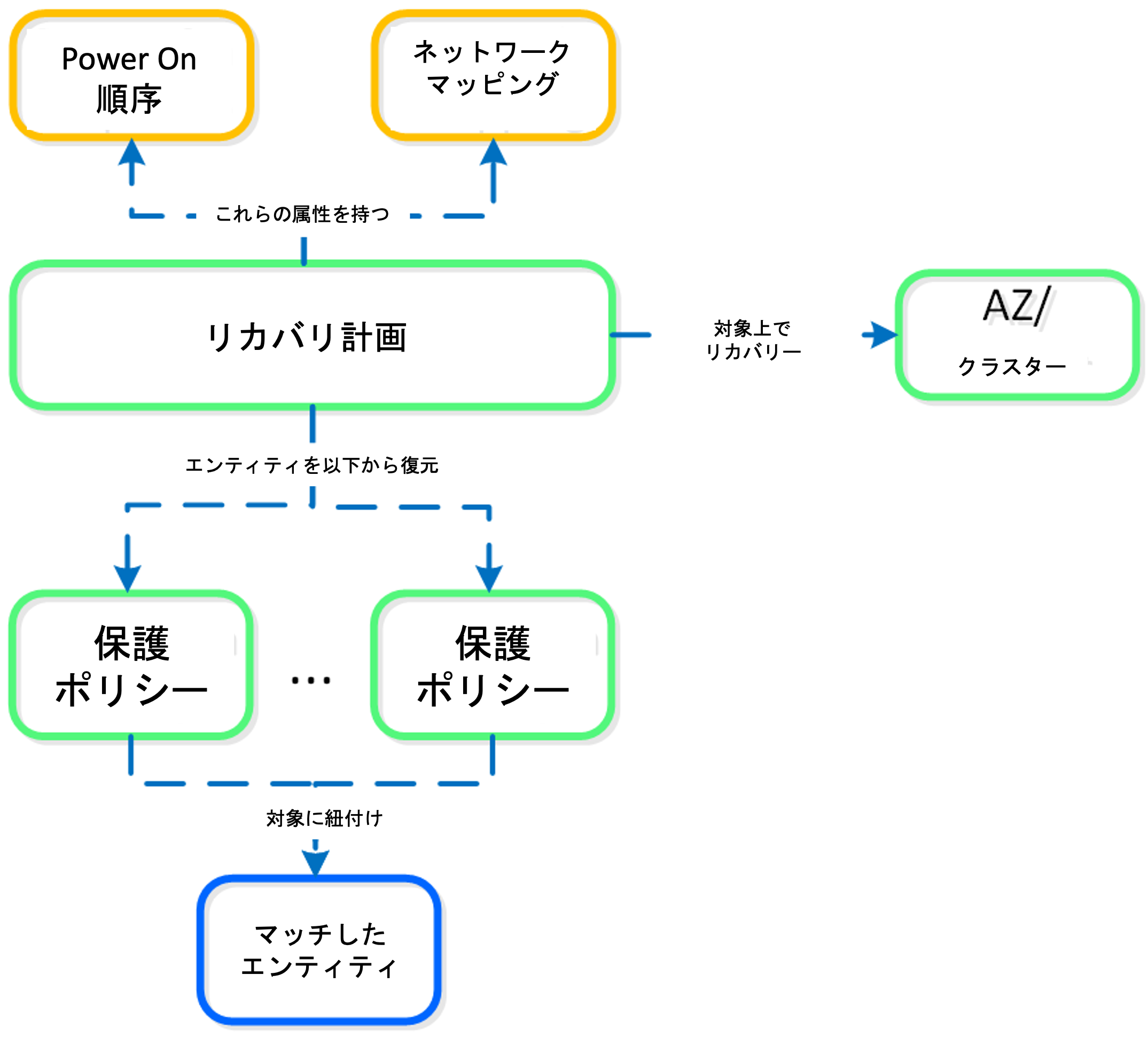
リカバリ計画– どのようにリカバリが行われるかを定義します。ここにはネットワークとIPアドレスのマッピング、仮想マシンの電源On順序を定義できるランブックオートメーション、そしてフェイルオーバーやテストフェイルオーバー後に呼び出されるポストブートスクリプトを定義します。
管理者はフェイルオーバーやテストフェイルオーバーをターゲットのAZのPrism Centralから1つもしくは複数のリカバリ計画を走らせることで実行できます。フェイルオーバーやテストフェイルオーバーが実行されている最中には詳細な監査証跡が作成され、列挙されたそれぞれのステップに対してのタイムスタンプが付与されるため、リカバリ計画がどのように行われたのかを明確に把握することができます。
可観測性
Nutanixのディザスタリカバリ(DR)ソリューションはオンプレミスからハイブリッド-マルチクラウドへと広がっていますが、そのDNAは変わらぬまま維持されています。ハイブリッドクラウドNutanix Cloud Clusters(NC2)によるDRaaSなどのトポロジの拡張が行われても、Nutanixとのハイブリッドクラウドジャーニーにおいて可観測性がお客様で高い優先順位を持つようになってきました。AOS 6.0リリースにおいて、我々はPrism Central内に可観測性ダッシュボードを追加し、RPOのSLA、DRの準備状況、アラート、その他のDRに関連する主なパフォーマンス指標についての洞察を提供するようにしました。
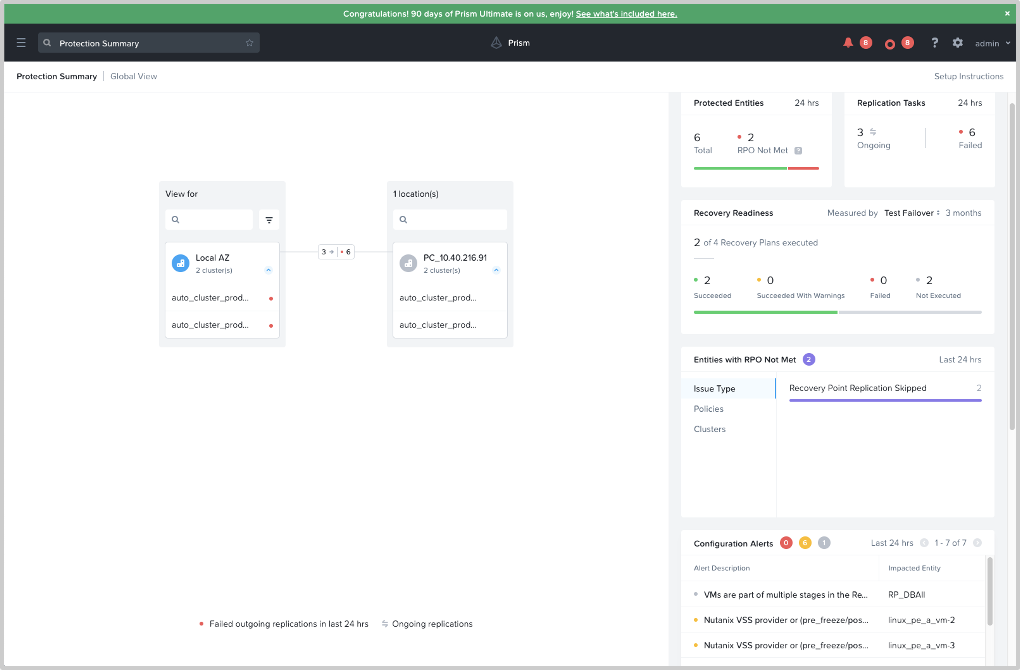
DRの可観測性については更に詳しくはディザスタリカバリダッシュボードについての記事をご参照ください。
なぜこれが重要なのか?
現在CIOとITリーダーはDR環境がスマートで、効率的、自動的に新しい仮想マシンを保護、仮想マシン単位でのレプリケーションの実施、そしてアプリケーションのRPOとRTOの改善にとって意味のある実用的な推奨を提供してくれることを期待しています。つまるところ、お客様はDR運用を予算内でシンプル化しながら、同時にRPOとRTOのSLAを法令コンプライアンスと共に満たすということです。
Nutanixはこれらの課題を理解し、お客様のDRをその機能をプラットフォームに組み込み、インストールや別途のソフトウェアや仮想マシンを必要としないよう、シンプル化してきました:
- 効率的なレプリケーション – RBRを活用してデータのレプリケーションにかかる時間を最大63%削減しビジネスのRPO SLAが満たされることを保証。
- ディザスタリカバリのオーケストレーション ― ポリシー駆動のDR計画によって、仮想マシンやアプリケーションのポリシーを迅速に作成および追加することが可能です。フェイルオーバー後の仮想マシンのブート順序をアサインし、ネットワークのIPアドレス管理もマッピングします。これらすべてが同じユーザーインターフェイス(UI)で面倒なプラグインやアダプター、追加の仮想マシンの管理なく実現できます。
- 可観測性 ― お客様はDRインフラストラクチャー全体を一つのわかりやすいダッシュボードから確認することができます。保護されている仮想マシン(リカバリ計画内でレプリケーションされている)の確認から、何回のレプリケーションが行われているか、それらのレプリケーションが失敗していないか、お客さまのビジネスが復元できる準備ができているかのアラートの設定(リカバリ計画の検証が成功したか)までを確認することができます。
Nutanixはプライベートクラウド、ハイブリッドクラウド、DRaaS、ハイブリッドマルチクラウドのどれかに関わらずDRニーズを抱えるお客様をサポートして来ました。
次のブログでは、Brian Suhr氏がNutanixがどのようにハイパーバイザーの選択肢を実現し、ビジネスそしてアプリケーションのニーズに合わせた環境を実現しているのかについてお伝えします。