

本記事はJosh Odgers氏が2020年8月14日に投稿した記事の翻訳版です。
パート2では、効率的なAOSのおかげで、3ノードのi3.metal環境でのNutanix Clusters on AWSソリューションでは、使用可能な容量がVMwareのVMCよりも24.5%多くなることを説明しました。
このことは小規模環境の顧客やコスト意識の高い顧客にとっては朗報ですが、Nutanixにおいて、環境が拡張されても容量やROIにおいて同様なメリットが得られるのか疑問に思う方もいらっしゃると思います。
今回の投稿では、次の3つのシナリオについて紹介します。
- 4ノードクラスターと5ノードクラスター
- 6ノードクラスター
- 16ノードクラスター
この3つのすべてのシナリオで、AWS i3.metalサービスを使用します。
この3つの例を取り上げるのは、VMCでは、3ノード環境、4~5ノード環境、および6ノード以上の環境に対して、それぞれ異なるストレージポリシーがデフォルトで適用されるためです。
16ノードの例では、VMCでサポートされている最大規模のクラスターを使用した場合について紹介します。
4ノードクラスターと5ノードクラスターの比較
4ノード環境の場合、VMwareのVMCは、論理容量に対して物理容量のオーバーヘッドが2倍になるFTT1(ミラーリング)から、3+1ストライプサイズを使用するイレージャーコーディング(RAID5)に切り替わります。切り替え後は、1.33倍のオーバーヘッドで容量が提供されます。
参照先:https://blogs.vmware.com/virtualblocks/2018/06/07/the-use-of-erasure-coding-in-vsan/
イレージャーコーディング(RAID5)に切り替わると、使用可能な容量が増えるため、切り替えはその点で意味がありますが、以下のような重大な影響が生じます。
- オールオアナッシング的なアプローチのため、I/O用の重要なパスに影響が生じる。VMwareもパフォーマンスへの影響を認識している
- 4ノードクラスターでは単一ノード障害を許容できず、単一ノード障害の場合は自己修復が不可能(3+1のストライプでは4つのノードが必要)なため、回復力が低下する
- I/O処理が少なくとも4つのノードに対して実行されるため(ストライプが4つのノードに渡るため)、ネットワークのオーバーヘッドが増加する
これらの問題については、パート1:ネットワークパフォーマンスで紹介しています。お読みいただいていない読者がいらっしゃいましたら、この投稿を読み進める前に目を通していただくことをおすすめいたします。
また、NutanixとvSAN(VMCのベースを構成する)でのイレージャーコーディングの比較に関する投稿において、どちらの製品もシングルパリティとデュアルパリティのイレージャーコーディングに対応しているものの、その実行や実行時の値は大きく異なることを紹介しています。
vSAN/VMCでは、I/Oプロファイル(書き込みホットデータなのか書き込みコールドデータなのか)に関係なく、すべてのデータにイレージャーコーディングが適用されます。それに対して、Nutanix Clusters(およびオンプレミス)では、フロントエンドの書き込みパフォーマンスに影響はまったく及ぼすことなく、かつ、適用に適した(書き込みコールド)データにのみEC-Xが適用されます。これらすべてがAOSによって動的に管理され、顧客は両方のデータを最大限に活用できます。
Nutanixのイレージャーコーディングのストライプサイズも、2+1(4ノード環境)から3+1(5ノード環境)や4+1(6ノード以上の環境)にまで動的に拡張可能です。
このように動的に拡張できるため、まずは小規模な環境(例えば、4ノード)で始めることで、イレージャーコーディングである程度効率を向上できます。クラスターの規模を拡張するにつれて、ストライプが動的に再作成(優先順位の低いバックグラウンドタスクとして)され、クラスターの規模が大きくなるほど節約される容量も多くなります。ノード障害が発生した場合にストライプを確実に再作成できるように、クラスターサイズに対するストライプの幅はN-1が常に維持されます。
vSAN/VMCでは、すべてのデータにイレージャーコーディングが強制的に適用されます。そのため、論理上では、イレージャーコーディングの効果で、場合によっては使用可能な容量がNutanixよりも多くなることが考えられます。ただし、データが書き込みホットの場合(つまり、データベースサーバーのように書き込みの頻度が極めて高い場合)は必要なパフォーマンスが得られないことが多く、vSAN/VMCのイレージャーコーディングは少々魅力に欠けます。
Nutanixを使用する場合、データベースサーバーの書き込みホットデータではRF2(ミラーリング)が無期限に使用され、7日以上経過したデータのみが自動的にイレージャーコーディングの対象と見なされます。そのため、パフォーマンスが最適化され、必要に応じて容量効率も最適化されます。
また、4ノードクラスターでのNutanixイレージャーコーディングは、自動的に2+1ストライプに限定されます。使用可能な容量の面ではメリットは小さくなりますが、この2+1ストライプへの限定は、回復力という重要な理由から意図的に行われています。
2+1ストライプの場合、4ノードのNutanixクラスターはノード障害を許容でき、完全に自己修復できます。ただし、VMCでは自己修復できません。
AWSでは、ハードウェアの追加は通常短時間で行えます。リビルドできないというリスクは、新規ノードを追加できるため多少軽減されます。ただし、常にハードウェアが利用可能であることを前提としており、対象となるAWSリージョンによっては、ハードウェアが常に利用可能であるとは限りません。
事実、私は上記のシナリオを何度も目にしました。
5ノード環境の場合、VMC(vSAN)では3+1ストライプが実行可能であり、ノード障害が発生した場合は5つ目のノードを使用して環境を確実にリビルドできます。VMCでは強制的なアプローチを取っており、すべてのI/Oにイレージャーコーディングが適用されるため、その影響が生じます。対照的に、Nutanixでは、最適なI/O及びデータにのみ動的にアプローチを行います。
私の見解では、回復力とパフォーマンスこそが重要です。回復力はデータ整合性のために重要(ITインフラストラクチャにおける最優先事項)であるため、低下させてはいけません。イレージャーコーディングのストライプをクラスターノード数と同じサイズにすると、環境を無用なリスクにさらすことになります。
i3.metalでVMCを使用する場合、VMwareでは2ディスクグループ構成が選択されています。つまり、2つのドライブがキャッシュ用に予約されるため、8つの1.9TB NVMeドライブのうち6つのみが使用可能な容量となります。
そのため、VMCで4ノードクラスターまたは5ノードクラスターをRAID 5(3+1ストライプ)で使用する場合は、次のようになります。
6 x 1.9TB(キャパシティドライブ) = 11.4TB / 1.33(RAID5の効率) = 8.57TB(使用可能な容量)
必要な25%のスラックスペースを差し引くと、VMCでのノード当たりの使用可能な容量は6.4TBになります。
NutanixでRF2を使用する場合、ノード当たり13.2TB(物理)となり、これを2で割って(RF2ミラーリングのため)6.63TBになります。N-1(4ノードクラスター)用に同様に25%を差し引くと、RF2を使用する場合はノード当たり4.97TBになります。
5ノードのNutanixクラスターでは、6.63 – 20%(N-1) = 5.3TBになります。
注:Nutanixでは、静的な「スラックスペース」は必要ありません。回復力を維持するために推奨されている容量予約は、クラスターの規模に基づいています。そのため、Nutanix環境では通常、空き領域が25%を大幅に下回っても、パフォーマンスと回復力を完全に維持しながら稼働し続けます。
VMC/vSANの強制的なアプローチに対して、Nutanixイレージャーコーディングは適したデータにのみ適用されるため、書き込みコールドとなるデータの割合を想定して、使用可能な容量を推定する必要があります。
データの25%のみが「書き込みコールド」であると想定し、Nutanix AOSによってこれらのデータにのみイレージャーコーディングを適用する場合、Nutanixでの使用可能な容量は6.63TBとなる上、フロントエンド(重要なI/Oパス)のパフォーマンスを高く保つことが出来ます。データはRF2として書き込まれ、書き込みコールド25%という控えめな想定をしたとしても、vSAN/VMCと同じ使用可能容量が得られます。
書き込みコールドデータを50%と想定した場合(私の経験上、これはごく一般的な値です)、Nutanixではノード当たり7.45TBが使用可能です。先に述べたように、パブリッククラウドではパフォーマンスやネットワーク負荷が大きくばらつきがちですが、パフォーマンスの低下やネットワーク負荷の増加は生じません。
「書き込みコールド」データの割合が大きいほど、Nutanixの顧客は使用可能容量が増えるというメリットが得られるのです。
使用可能容量:
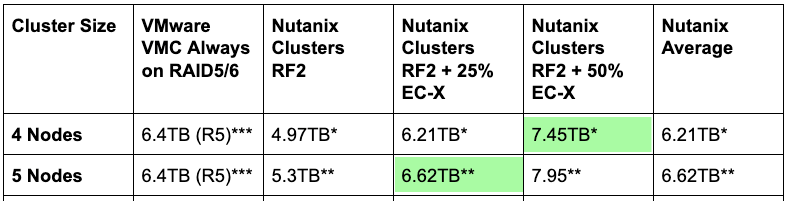
* N-1 = 25%を含む(4ノードクラスター)
** N-1 = 20%を含む(5ノードクラスター)
*** スラックスペース = 25%(静的、VMware推奨の最小値)
この表から分かるように、Nutanixの高度な分散ストレージファブリックとイレージャーコーディングアーキテクチャーのおかげで、Nutanix Clustersでは、「書き込みコールド」のデータをわずか25~50%に抑えながら、VMC/vSANと同様の使用可能な容量が得られます。
100%のデータがイレージャーコーディングに適している(この値がVMCアーキテクチャーでの想定であり制約でもあります)と想定した場合、NutanixはVMCよりも著しく高いフロントエンドのパフォーマンスを発揮しながら、使用可能な容量も大幅に多くなります。
「どのようなワークロードやデータがイレージャーコーディングに適しているのか」というのは、非常に難しい質問です。そのため、すべてのワークロードにイレージャーコーディングを適用する場合には、優れた結果が得られる可能性は低いでしょう。
Nutanixでは、すべてのワークロードに対してイレージャーコーディングを有効にできますし、また、そうあるべきです。AOSは適したデータにのみEC-Xをインテリジェントに適用するため、適用するワークロードを選択するという複雑な作業やリスクなしに、最適な容量効率を確保できます。
Nutanixアーキテクチャーでは、パフォーマンスとストレージ効率の両方を最適化できるため、イレージャーコーディングをインテリジェントに適用し、ROIの向上が可能になります。
このアプローチが極めて重要であることを示す簡単な例として、大半の顧客にとって特定のワークロード専用のサイロは不要であり、コスト的にも妥当でないことが挙げられます。Nutanix Clustersの顧客は、ミッションクリティカルなデータベースワークロードをテスト/開発環境やデータアーカイブと同じクラスターで最適に実行でき、かつ、データは固有のI/Oプロファイルに基づいてインテリジェントに管理されます。
これが重要なポイントです。その理由は、インフラストラクチャーにサイロがあると、フラグメンテーションの発生や使用率の低下が生じますが、このサイロのニーズが最小限になるかゼロになり、最適なパフォーマンスが確実に得られるためです。
サイロを最小化またはゼロにできるNutanixの利点として、回復力の向上も挙げられます。Nutanixクラスターはその規模が大きいほど、障害発生時にリビルドや回復にかかる時間が短くなり、回復力を維持するために予約するクラスターリソースの割合も小さくなります。例えば、N-1やN-2では、4ノードクラスターよりも8ノード、12ノード、および16ノードのクラスターのほうがオーバーヘッドが大幅に小さくなります。
これは私の経験則です:ノード数が多いほど、リビルドにかかる時間が短くなり、停止のリスクやデータ損失のリスク、および回復力を維持するためのオーバーヘッドが小さくなります。
6ノードクラスターの比較
6ノード環境の場合、VMwareのVMCは、3+1ストライプサイズ(1.33倍のオーバーヘッド)を使用するイレージャーコーディング(RAID5)から4+2ストライプ使用のRAID6に切り替わります。RAID6ではデュアルパリティの回復力が得られますが、オーバーヘッドは1.5倍になります。
参照先:https://blogs.vmware.com/virtualblocks/2018/06/07/the-use-of-erasure-coding-in-vsan/
イレージャーコーディング(RAID6)への切り替えは、ミラーリング(FTT1)の場合よりも使用可能な容量が多くなり、デュアルパリティによって回復力も向上するため、その点で意味があります。ただし、先に紹介した重大な影響が生じる上に、ネットワークへの依存が高くなり、全VMと全I/Oのパフォーマンスにも大きく影響します。
使用可能容量:

* N-1 = 17.5%を含む(6ノードクラスター)
*** スラックスペース = 25%(静的、VMware推奨の最小値)
3 wayミラーリング(FTT2 / RF3)を使用し、データの25~50%がイレージャーコーディング(パフォーマンスのオーバーヘッドなしに同等の使用可能な容量を提供)に適しているというように控えめに想定した場合でも、使用可能な容量の平均値はNutanixのほうがVMCよりも多くなっています。
イレージャーコーディングに控えめな想定を使用した場合も、使用可能な容量の平均値はVMCよりも多くなっています。
私の見解では、Nutanix RF2はvSAN/VMCのFTT1よりも回復力がはるかに高いため、デュアルパリティ(RF3)の使用が必要になるのは、クラスターの規模がかなり大きい場合です。そのため、実際には、3~24ノードのクラスターの場合が、Nutanix RF2でイレージャーコーディングを適用するのにもっとも適しています。
RF2およびEC-Xを適用して6ノードクラスターをデプロイする場合、6ノードクラスターでノード当たりの使用可能な容量は6.62~7.45TBになり、VMCで提供される5.7TB(RAID6)よりもはるかに多くなります。また、データがリスクにさらされる時間を最小限に抑える超高速のリビルド操作など、総合的なデータ整合性の効果で回復力もVMCより高くなります。
16ノードクラスターの比較
16ノード環境の場合、Nutanixの長所である効率性が極めて明確になり、重要性も増します。
以下の表は、4つの主要なストレージポリシーを適用した場合の使用可能な容量を示しています。
- vSAN Failures to tolerate 1(FTT1) / Nutanixリダンダンシーファクタ2(RF2)
- vSAN Failures to tolerate 2(FTT2) / Nutanixリダンダンシーファクタ3(RF3)
- vSANイレージャーコーディング/RAID5(FTT1/R5) / Nutanixリダンダンシーファクタ2(RF2)、25%と50%のコールドデータを想定
- vSANイレージャーコーディング/RAID5(FTT2/R6) / Nutanixリダンダンシーファクタ3(RF3)、25%と50%のコールドデータを想定
注:VMCが6ノード以上の環境に推奨しているデフォルトのストレージポリシーはRAID6であるため、以下の表内の一番下の行の値が直接比較にもっとも適しています。
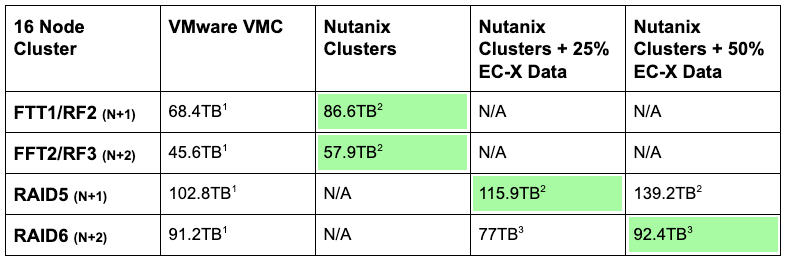
1) VMwareの推奨に従って25%のスラックスペースを差し引く
2) 12.5%の容量予約のためにN-2の容量を予約することで(必要なN-1に加えて)、回復力が向上
3) 12.5%のN-2容量予約
すべてのシナリオで、必要以上の容量予約をした場合(FTT1/RF2のシナリオやRAID5のシナリオでのN-2の容量予約)や、イレージャーコーディングでのデータ低減を25%と控えめに想定した場合(RAID5のシナリオとRAID6のシナリオ)においても、Nutanixのほうが使用可能な容量が多くなっています。
RAID6のシナリオで、EC-Xを50%と想定した場合、Nutanixの使用可能な容量はわずかに多くなっています。VMCでは、データのパフォーマンスプロファイルに関係なく、100%のデータにイレージャーコーディングが強制的に適用されることに注意してください。Nutanixでは、データとI/Oプロファイルに応じて、50%以上を適用して容量をさらに節約することが可能です。
Nutanixのインテリジェントで動的なイレージャーコーディングでは、重要なパス上のデータや適さないデータ(書き込みホット)にはイレージャーコーディングが適用されないため、最適なパフォーマンスを確保できます。
次は、パート4: データ効率化テクノロジーについての考慮事項をご覧ください。