


In a recent post, I compared the actual Usable Capacity between Nutanix ADSF vs VMware vSAN on the same hardware and we saw approx 30-40% more usable capacity delivered by Nutanix.
The next logical step is to compare data reduction/efficiency technologies that apply further storage capacity efficiencies to the usable capacity.
In the previous post, I declared “a wash” between the two products for the sake of simplifying the usable capacity comparison. However, the reality is it’s not a wash as the Nutanix platform has the ability to deliver more usable capacity from the same HW. Combine that with a superior storage layer in the form of the Acropolis Distributed Storage Fabric (ADSF) which compliments data reduction technologies, vSAN is bringing a spoon to a gunfight.
In this post, we’ll look at Deduplication and Compression.
Data reduction technologies such as Compression, Deduplication are proven technologies that provide varying levels of value to customers depending on their datasets.
During these comparisons, marketing material, in many cases “Tick-Box” style slides are being used by vendors sales reps and worse still they are commonly taken on face value which can lead to incorrect assumptions for critical architectural/sizing considerations such as capacity, resiliency and performance.
It reminds me of a post I wrote way back in 2014 titled: Not all VAAI-NAS storage solutions are created equal where I highlighted that while multiple vendors supported VAAI-NAS for vSphere, not all vendors supported all the primitives (features) of VAAI-NAS which provided valuable functional, capacity efficiency and performance improvements by avoiding unnecessary IO operations.
Now some 6 years later, not much has changed as these tick-box marketing comparisons still plague the industry.
Let me give you a simple example:
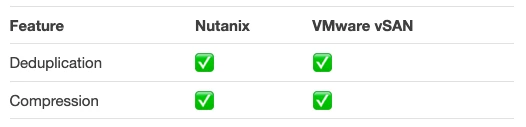
The above table shows the data reduction technologies and that both Deduplication and Compression are supported by Nutanix and VMware vSAN.
With this information, customer/parters/VARs can and do conclude the data reduction capabilities for both products are the same or at least the difference is insignificant for a purchasing or architectural decision.
When this happens, the same people are very mistaken for many critical reasons.
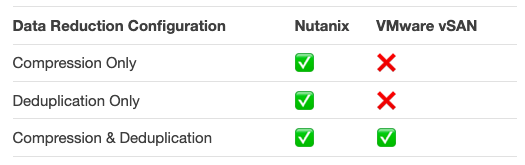
The following table shows what configurations data reduction configurations currently supported for both products:

Here we learn that vSAN does not support data reduction technologies on Hybrid configurations (Flash + HDD). This gives customers choosing hybrid platforms an advantage going with Nutanix as they will more than likely be able to store significantly more data on the same or even less hardware.
The messaging from VMware has consistently been that they do not support data reduction on hybrid intentionally because data reduction on hybrid (HDD) tiers should not be done for performance reasons.
I’ll address this claim later in the post.
Let’s continue to dive into this and see what other differences the products have.
General Deduplication & Compression concepts
Data reduction technologies have advantages and disadvantages, for example deduplication may provide >10:1 efficiency on VDI datasets but minimal or no savings for other datasets.
For data which is already compressed (e.g.: At the application layer), storage layer compression may also not provide much value.
Both technologies also require some CPU/RAM from a storage controller (Physical, virtual, In-kernel, Controller VM) to perform these functions, this “cost” on resources and potentially performances needs to be weighed up against the capacity savings and this can vary substantially between customers.
As such, to avoid unnecessary overheads on the hosts (vSAN Kernel / Nutanix CVM), it’s important to consider when/where to use these technologies.
A “brute force” application of Compression & Deduplication will rarely result in the outcome people are sold and/or typically expect. In contrast the outcome will likely significantly impact performance especially where the data reduction ratio is low (e.g.: <1.2:1), so flexibility is key.
The following table shows how data reduction technologies can be configured:
With vSAN, Compression and Deduplication must be enabled all together and for the entire vSAN cluster. This means customers lose the flexibility to enable the most suitable technology for their dataset AND the overheads of unnecessarily applying compression or deduplication.
The below shows the Deduplication and Compression configuration to enable on vSAN:
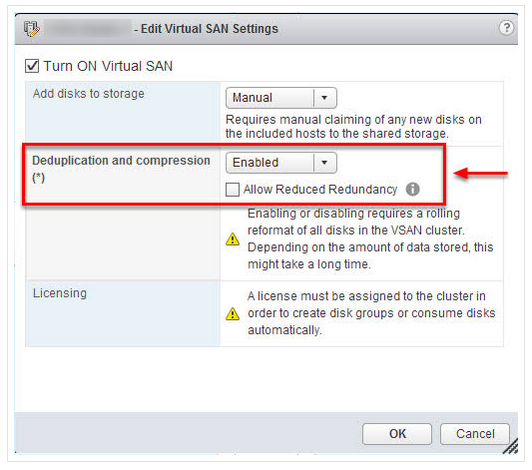
This is a major issue and will lead to inefficiency and may force customers into creating multiple silos, further reducing efficiency and increasing overheads for resiliency (e.g.: N+1 node per cluster).
e.g.: A customer has a 16 node cluster, half the workload gets 2:1 compression and deduplication and performs well, the other half are business-critical applications which are suffering performance issues. To resolve this problem, the vSAN customer needs to either disable Deduplication and compression for the entire cluster and lose the 2:1 capacity savings (which likely leads to additional node purchases) OR they have to split the cluster into two or more clusters to enable them to continue using deduplication and compression where it’s delivering value.
Question: How do you split a 16 node vSAN cluster into 2 without significant downtime and/or additional hardware? (Not to mention the effort involved in planning the process).
With Nutanix, you simply toggle OFF compression or deduplication or both for the workloads which are not performing to the required level. Thus eliminating the need for a complex, risky and time-consuming project splitting up a vSAN cluster due to data reduction technology constraints.
Deduplication boundary:
How and where deduplication is applied can have a significant impact in the efficiency it can deliver. Let’s compare the deduplication “boundary” for both products.
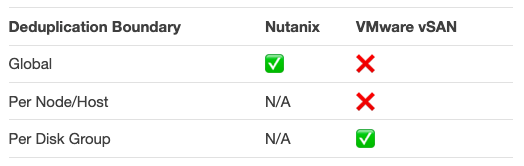
For Nutanix it’s simple, any data within the storage container can be deduplicated with any other data anywhere in the cluster. For a 16 node cluster with 16 copies of the same data, if you enable deduplication, Nutanix will reduce this to 1 copy (protected with RF2 or RF3) resulting in a 16:1 efficiency for that data.
For the same example, vSAN would not achieve any efficiency as it only deduplicates within a disk group. VMware recommends at least two disk groups per node for optimal performance, which means their implementation of deduplication will allow multiple copies of data even within the same host (where the duplicates are across disk groups).
In the same 16 node cluster example where Nutanix achieved 16:1 efficiency, vSAN would store 16x the data of Nutanix due to the constraint of deduplication is only performed on a per disk group basis.
If the vSAN environment used two disk groups per node, and duplicate data was on each disk group you would potentially have 32 copies (16 nodes * 2 disk groups) of the same data due to the boundary for deduplication being at a disk group layer (as opposed to global).
In the real world, the result could be 16-32x, but is more likely to be much lower, say 1.5 or 2:0 for mixed workloads. The point is, the potential efficiency of vSAN is artificially reduced by the underlying architecture and Nutanix does not suffer from this problem.
The counter argument from VMware is global deduplication requires global metadata which may have a higher resource requirement (CPU/RAM) than the much simpler, less efficient, vSAN implementation. Well, VMware are not wrong with this statement, but as Nutanix ADSF is a truly distributed architecture, it already uses global metadata for the storage fabric which is why deduplication was supported way back in 2013 when vSAN only “bolted on” deduplication and compression in 2016 with vSAN 6.2.
Another argument against Nutanix global dedupe could be the loss of some data locality, but I can’t recall ever hearing this argument because it would mean VMware conceding that Nutanix’ unique implementation of data locality is valuable which they smartly steer away from as one of vSAN’s major architectural flaws is it’s inability to intelligently service writes where the VM resides after the VM moves from the host it was created on.
As we’ve learned from my Usable Capacity Comparison, The Distributed storage fabric (using it’s global metadata) also provides significantly more usable capacity vs RAW when compared to vSAN, which would justify any perceived or real additional resource overhead. Global metadata also allows for features like Storage only nodes to add capacity, resiliency and performance without any user intervention, so global metadata comes at a cost but delivers value in spades.
In part 2 we’ll look deeper at how, when and where the data reduction takes place.
This article was originally published at http://www.joshodgers.com/2020/02/03/deduplication-compression-comparison-nutanix-adsf-vs-vmware-vsan/
 2020 Nutanix, Inc. All rights reserved. Nutanix, the Nutanix logo and all Nutanix product, feature and service names mentioned herein are registered trademarks or trademarks of Nutanix, Inc. in the United States and other countries. All other brand names mentioned herein are for identification purposes only and may be the trademarks of their respective holder(s). This post may contain links to external websites that are not part of Nutanix.com. Nutanix does not control these sites and disclaims all responsibility for the content or accuracy of any external site. Our decision to link to an external site should not be considered an endorsement of any content on such a site.
2020 Nutanix, Inc. All rights reserved. Nutanix, the Nutanix logo and all Nutanix product, feature and service names mentioned herein are registered trademarks or trademarks of Nutanix, Inc. in the United States and other countries. All other brand names mentioned herein are for identification purposes only and may be the trademarks of their respective holder(s). This post may contain links to external websites that are not part of Nutanix.com. Nutanix does not control these sites and disclaims all responsibility for the content or accuracy of any external site. Our decision to link to an external site should not be considered an endorsement of any content on such a site.