


In this series, we’ve learned Nutanix provides more usable Capacity along with greater capacity efficiency, flexibility, resiliency and performance when using Deduplication & Compression as well as Erasure Coding.
We’ve also learned Nutanix provides far easier and superior storage scalability and has greatly reduce impact from Drive failures.
In this part, we cover heterogeneous cluster support as this is critical to an HCI platform's ability to scale and ensure ever changing customer requirements are being met/exceeded.
Hardware capacity/performance continues to advance at a great pace if customers are forced to use uniform (homogeneous) clusters it will likely result in a higher TCO and slower ROI. That’s bad enough but it also means customers will not get to take advantage of the performance and density advantages of newer hardware without creating silos which lead to more inefficiency.
After all we don’t want to be in the same position where we need to “rip and replace” hardware like in the old SAN era.
Let’s start with a simple “tick-box comparison”.
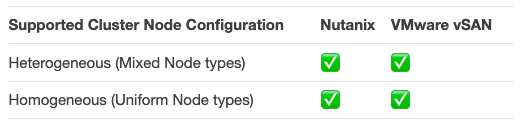
As I’ve highlighted in the previous articles, “Tick-Box” style slides commonly lead to incorrect assumptions about a products capabilities. This problem is extremely relevant in this case, Let me give you a simple example:
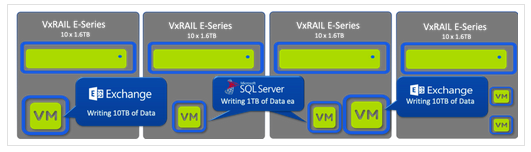
Let’s say we have a 4 node cluster again using DellEMC’s preferred hardware platform, the VxRail E-Series.
Here we see our cluster running a mix of CPU/RAM intensive business critical apps (Exchange and SQL) and we can assume some smaller less resource intensive VMs like Active Directory.
Next we want to expand the cluster with CPU/RAM but also storage to support natural growth which require large amounts of storage due to new compliance requirement for data retention of emails which has a flow on effect the SQL environment which also stores compliance data.
We review our hardware options (using the DellEMC VxRail catalog as a reference) and find the VxRail P-Series which appears to meet the requirements based on the description below:
Performance intensive 2U/1Node platform with an all NVMe option, configurable with 1,2 or 4 sockets optimized
Reference: https://www.dellemc.com/en-be/collaterals/unauth/data-sheets/products/converged-infrastructure/h16763-vxrail-14g-spec-sheet.pdf
for intensive workloads such as databases
We’ve already learned that Nutanix provides a significantly more usable capacity, Up to 41.25% more usable capacity in-fact, but we’re not going to focus on the usable capacity numbers, rather how both products behave when the new nodes are added.
We now add four new nodes which use the same CPU/RAM as the existing P-Series nodes but have 24 x 1.6TB SSDs as opposed to the 10 in the E-Series. We now have an 8 node heterogeneous cluster.
Let’s discuss how vSAN behaves in this scenario.
The read I/O continues in a round robin manner across the four nodes hosting the objects, the writes also continue to the same four nodes as if the new nodes are not present in the cluster.
This means the four new nodes are not being used for vSAN I/O even if the VMs are vMotion’d onto these nodes.
As a result, if no I/O is going to the four new nodes (because vSAN objects have not moved) – the new nodes are adding no value until manual rebalancing is initiated by an administrator, or the nodes reach 80% full and some automatic rebalancing takes place.
Below 80% utilisation & without administrator manual rebalancing – the new nodes are not utilised.
Outcome 1: No performance improvement for the environment.
What about the additional usable capacity?
While the vSAN datastore shows additional capacity, it’s not usable per se until one or more of the following happens:
- Manual Rebalancing where some objects are moved to the new nodes
- Automatic rebalancing (but only if the cluster utilisation is >80% by default)
- New VMs or virtual disks are created
Outcome 2: No usable capacity improvement for the environment without bulk movement of data AND/OR manual intervention from an administrator (to create new VMs/vDisks).
It’s possible in this scenario for VMs to get write errors (Out of Space) as a result of the cluster not being in a balanced state despite 4 new nodes of capacity being available.
At this point, let’s assume the vSAN administrator has initiated a manual rebalance of the environment and the cluster is back to a balanced state and acknowledges the bulk movement of data will have had some impact on the cluster and taken some time to complete.
New Write IO continues to be written in a static manner to the objects. This will likely end up in a state where future manual or automatic rebalancing is required, which as we’ve learned earlier is a bulk movement of objects of up to 255GB in size.
Outcome 3: The vSAN cluster balance is not proactively maintained and future rebalancing will ultimately be required as the environments capacity utilisation increases.
Further to this, the performance of VMs especially in the case of critical workloads MS SQL and MS Exchange is likely not getting the full performance potential of using all nodes in the cluster for write I/O as the writes only goto nodes hosting the VMs objects.
vSAN rebalancing moves entire objects up to 255GB at a time in order to balance the cluster.
With vSAN having significant challenges in heterogenous environments, it forces customers to make a difficult choice between creating additional silos OR creating higher levels of operational complexity & risk.
Let’s now cover how Nutanix ADSF functions in the same scenario.
Nutanix ADSF immediately starts sending new incoming write I/O intelligently across the entire cluster, including the four new nodes even if no new vDisks are created and no VMs are ever moved to the new nodes. Essentially the new nodes act as “Storage Only Nodes” until VMs are migrated to them via DRS or manually.
This intelligent replica placement (or in-line balancing) is done in real time, giving an immediate performance boost to the cluster and minimising the potential post process disk balancing that needs to occur.
Outcomes for Nutanix:
1. Immediate Improvement in Performance
2. Immediate and Inline (proactive) Cluster balancing
3. Immediate increase in available/usable capacity
The above outcomes are achieved with:
- Virtual Machines using standard VMDK vDisks
- The current generally available AOS release
- 100% default Nutanix configuration
- No advanced tuning or configuration of ADSF
- No advanced tuning/configuration of ESXi (100% hypervisor agnostic).
During the next “curator” scan (Curator manages background operations in the cluster), the process will detect the cluster is imbalanced and process an automated and granular disk balancing task.
Curator has a usage percentage spread threshold of 15% (“gflag” shown below) which allows some imbalance before initiating background balancing operations.
–curator_max_balanced_usage_spread=15
Default setting in AOS for usage usage spread.
Because ADSF is in real time balancing new writes based on both performance AND capacity utilisation, the higher the incoming writes (cluster workload), the quicker the cluster will get into a balanced state.
This is thanks to the intelligent and dynamic write replica placement which lowers the potential requirement for post process disk balancing which importantly is a fully automatic process.
The intelligence doesn’t stop there, curator has a dynamic threshold for disk balancing (data movement) where it moves a minimum of 20GB and a maximum of 100GB per curator scan which ensures the impact of disk balancing is minimised while ensuring the cluster is maintained in a healthy state.
–curator_disk_balancing_linear_scaling_min_max_mb=20480,102400
Dynamic disk balancing threshold in AOS
Outcome #4: Disk balancing is performed at a 4MB (Extent group) granularity (not 255GB objects) and is automatically managed regardless of the cluster capacity utilisation level to minimise the chance of capacity management issues
Nutanix ADSF with it’s intelligent (write) replica placement and fully automated disk balancing make heterogeneous clusters not just a “supported” option but a realistic and reliable option for customers.
Let’s summarise what we’ve learned so far:

* vSAN will automatically balance at >=80% utilisation of any storage device but it is done at a large object level (up to 255GB).
Ultimately VMware are aware of the issues I’ve highlighted and I believe it is for these reasons they make the following recommendations in the vSAN 6.7 planning and deployment guide:
vSAN works best on hosts with uniform configurations.
Reference: https://docs.vmware.com/en/VMware-vSphere/6.7/vsan-673-planning-deployment-guide.pdf
Using hosts with different configurations has the following disadvantages in a vSAN cluster:
* Reduced predictability of storage performance because vSAN does not store the same number of components on each host.
* Different maintenance procedures.
* Reduced performance on hosts in the cluster that have smaller or different types of cache devices.
Can anything be done to improve the situation for vSAN?
Some of the capacity management and performance challenges can be potentially mitigated by increasing the Number of Disk Stripes Per Object/Stripe Width from the default of 1 to a maximum of 12
Here is how VMware describe this option:
Number Of Disk Stripes Per Object , commonly referred to as stripe width, is the setting that defines the minimum number of capacity devices across which each replica of a storage object is distributed. vSAN may actually create more stripes than the number specified in the policy.
Reference: https://storagehub.vmware.com/t/vmware-r-vsan-tm-design-and-sizing-guide-2/policy-design-decisions-1/
With that said, the VMware documentation also states:
However, for the most part, VMware recommends leaving striping at the default value of 1 unless performance issues that might be alleviated by striping are observed.
Reference: https://storagehub.vmware.com/t/vmware-r-vsan-tm-design-and-sizing-guide-2/policy-design-decisions-1/
The documentation goes on further with Stripe Width – Sizing Consideration:
There are two main sizing considerations when it comes to stripe width. The first of these considerations is if there are enough physical devices in the various hosts and across the cluster to accommodate the requested stripe width, especially when there is also a NumberOfFailuresToTolerate value to accommodate.
Reference: https://storagehub.vmware.com/t/vmware-r-vsan-tm-design-and-sizing-guide-2/policy-design-decisions-1/
The second consideration is whether the value chosen for stripe width is going to require a significant number of components and consume the host component count. Both of these should be considered as part of any vSAN design, although considering the increase in the maximum component count in 6.0 with on-disk format v2, this is not a major concern anymore. Later, some working examples will be looked at which will show how to take these factors into consideration when designing a vSAN cluster.
Ultimately my take away from this is changing the Number Of Disk Stripes Per Object may help improve capacity management and potentially performance but it’s also adding significant additional complexity and risk which should be avoided unless absolutely required as with any advanced settings.
Summary
Nutanix ADSF not only supports heterogeneous clusters, thanks to it’s truly distributed storage fabric it:
- Avoids all of the downsides suffered by vSAN
- Optimally uses the all available hardware within the cluster regardless of the node type/size
- Immediately & intelligently balances incoming write I/O based on capacity utilisation and performance when new nodes are added
- Provides fully automated disk balancing
- Ensures new nodes resources (capacity) is immediately available without any intervention from the administrator/s.
- Avoids the need to create “silos” of hardware to maintain uniform clusters
- Allows customers to scale in a just in time fashion without having to deal with potentially challenging storage capacity management/performance challenges
- Allows customers to mix multiple generations of HW into a single cluster to maximise, performance, resiliency and return on investment (ROI).
- Achieves all these outcomes without any non default configuration.
This post was originally published at http://www.joshodgers.com/2020/02/26/heterogeneous-cluster-support-nutanix-vs-vmware-vsan/
 2020 Nutanix, Inc. All rights reserved. Nutanix, the Nutanix logo and all Nutanix product, feature and service names mentioned herein are registered trademarks or trademarks of Nutanix, Inc. in the United States and other countries. All other brand names mentioned herein are for identification purposes only and may be the trademarks of their respective holder(s). This post may contain links to external websites that are not part of Nutanix.com. Nutanix does not control these sites and disclaims all responsibility for the content or accuracy of any external site. Our decision to link to an external site should not be considered an endorsement of any content on such a site.
2020 Nutanix, Inc. All rights reserved. Nutanix, the Nutanix logo and all Nutanix product, feature and service names mentioned herein are registered trademarks or trademarks of Nutanix, Inc. in the United States and other countries. All other brand names mentioned herein are for identification purposes only and may be the trademarks of their respective holder(s). This post may contain links to external websites that are not part of Nutanix.com. Nutanix does not control these sites and disclaims all responsibility for the content or accuracy of any external site. Our decision to link to an external site should not be considered an endorsement of any content on such a site.