


In the first post in this series I compared the actual Usable Capacity between Nutanix ADSF vs VMware vSAN on the same hardware.
We saw approximately 30-40% more usable capacity delivered by Nutanix.
Next we compared Deduplication & Compression technologies where we learned Nutanix has outright capacity efficiency, flexibility, resiliency and performance advantages over vSAN.
Then we looked at Erasure Coding where we learned the Nutanix implementation (called EC-X) is both dynamic & flexible by balancing performance and capacity efficiencies in real time.
Next we switched it up and discussed how both solutions can scale capacity & we learned while vSAN has numerous constraints which make scaling less attractive, Nutanix allows customers to scale storage capacity by adding individual drives, HCI node/s or storage only nodes without manual intervention.
But all these advantages Nutanix has over vSAN don’t mean a thing unless the platform is also highly resilient to failures.
In this part, we will discuss how both platforms handle and recover from various drive failure/s scenarios on a typical all flash hardware configuration.
Recently a DellEMC employee complained I didn’t use their most popular hardware in my prior example, so in this case we’ll use what Aaron has mentioned as the overwhelming choice being the VxRail E Series. The E series supports 10 x 2.5″ drives which we’ll populate with the commonly recommended all flash configuration with the maximum 10 x 1.92TB drives.
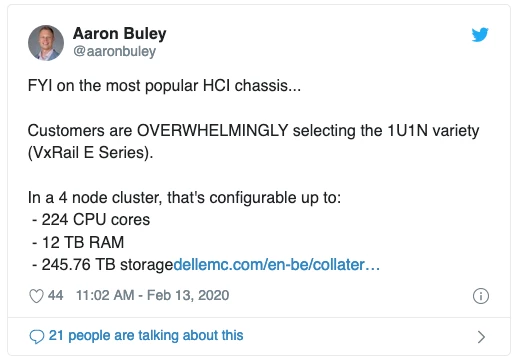
We’ll also use two disk groups for the vSAN configuration as this is the most resilient configuration possible for vSAN on the VxRail E Series. Interestingly you actually have no choice but to use two disk groups as one disk group can only support up to 7 capacity drives… we’ll cover this constraint in a future post.
For those who are not familiar with Nutanix, there is no concept/complexity similar to a disk group, all drives are part of a cluster wide or “global” storage pool.
Nutanix also does not have the concept of a “cache” drive, all drives are part of the storage pool and in the case of flash devices, all contribute to the persistent write buffer (oplog) for better drive wear, resiliency and performance.
As I’ve highlighted in the previous articles, “Tick-Box” style slides commonly lead to incorrect assumptions for critical architectural/sizing considerations.
This problem is also applicable to resiliency and in this discussion, drive failures. Let me give you a simple example:
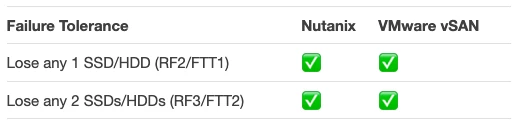
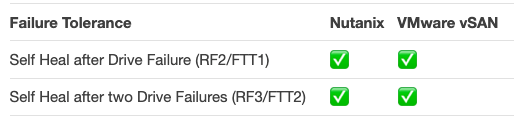
As we can see from the tick-box comparison, both platform can tolerate the failure of any SSD/HDD failure by configuring either Nutanix Resiliency Factor RF2 / vSAN Failures to Tolerate FTT1, and two concurrent SSD/HDD failures by using Nutanix RF3 or vSAN FTT2.
In the event of these failures both products can also perform a self heal.
So Far so good!
Well… not really as the impact of the failures varies significantly depending on how vSAN/VxRail is configured whereas failures on the Nutanix platform are handled consistently regardless of the configuration.
Example 1: A vSAN “cache” drive failure
With vSAN, in the two disk group configuration which is recommended for better resiliency and performance by VMware, a single “cache” drive failure takes an entire disk group offline!
In the most common DellEMC VxRail platform, with two disk groups (1 cache drive and 4 capacity drives per disk group), the single cache drive failure results in 5 drives going offline and needing to be rebuilt. That’s 5 x 1.92TB drives of capacity lost AND needing to be rebuilt by vSAN.
With Nutanix, any single drive failure is just as you would expect, a single drive failure and only that single 1.92TB drive needs to be rebuilt.
In this example Nutanix has a 5x lower impact than vSAN.
At this point you’ve likely already decided vSAN isn’t minimally viable, but read on as you’ll have the spare time because you’re deploying Nutanix.
Example 2: vSAN Drive Failures when using Deduplication & Compression
When using Deduplication & Compression, If the cache drive fails the disk group still goes offline as discussed in Example 1, but if a vSAN capacity drive fails, you also lose the entire disk group!
With Nutanix, the situation remains consistent and as you would expect, a single drive failure only results in a single 1.92TB drive needs to be rebuilt.
In example 2, Nutanix again has a 5x lower impact than vSAN!
Still reading or are you enjoying Nutanix PRISM GUI yet?
Example 3: vSAN’s lack of distributed granular rebuild
vSAN is constrained by it’s underlying “Object store” design which stores objects up to 255GB and rebuilds at the same level.
This means vSAN is limited on where it can rebuild objects too, as it needs sufficient capacity to store each object. Not only is this less performant due to the Object to Object rebuild essentially being from one drive to another drive (i.e.: 2 flash devices and 2 nodes), fragmentation can occur which is why VMware recommend 25-30% slack space as discussed previously.
This means vSAN has less usable capacity & is slower to rebuild than Nutanix.
How does Nutanix outperform vSAN for rebuilds you ask?
Nutanix performs rebuilds at a 4MB granularity and does not have the constraint of large objects. A vDisk is simply made up of as many 4MB extent groups as it needs and these are distributed based on performance and capacity throughout the cluster. This means for Nutanix rebuilds, all nodes and all drives in the cluster contribute to the rebuild of a single drive, making it faster, lower impact and results in a more balanced cluster capacity wise.
For an example of how fast Nutanix can rebuild, checkout my article from 2018 on node rebuild performance which shows Nutanix ADSF is so efficient it can perform rebuilds at close to the maximum performance of the physical SSDs.
If you’re still considering vSAN, Example 4 will change your mind.
Example 4: vSAN I/O integrity during maintenance & failures
A major resiliency advantage Nutanix has over vSAN is the fact ADSF always remains in compliance with the configured Resiliency Factor including during all failure and maintenance scenarios.
vSAN however, does not maintain it’s configured FTT level during all host maintenance and failure scenarios. For VMs on vSAN configured with FTT=1, in the event the host hosting one vSAN disk “object” is offline for maintenance, new overwrites are not protected so a single drive failure can result in data loss. If a node is offline for maintenance and the customer does not select to Evacuate all data from the node, then writes are also not kept in compliance with the Failure to Tolerate (FTT) policy.
This article was originally published at http://www.joshodgers.com/2020/02/19/drive-failure-comparison-nutanix-adsf-vs-vmware-vsan/
 2020 Nutanix, Inc. All rights reserved. Nutanix, the Nutanix logo and all Nutanix product, feature and service names mentioned herein are registered trademarks or trademarks of Nutanix, Inc. in the United States and other countries. All other brand names mentioned herein are for identification purposes only and may be the trademarks of their respective holder(s). This post may contain links to external websites that are not part of Nutanix.com. Nutanix does not control these sites and disclaims all responsibility for the content or accuracy of any external site. Our decision to link to an external site should not be considered an endorsement of any content on such a site.
2020 Nutanix, Inc. All rights reserved. Nutanix, the Nutanix logo and all Nutanix product, feature and service names mentioned herein are registered trademarks or trademarks of Nutanix, Inc. in the United States and other countries. All other brand names mentioned herein are for identification purposes only and may be the trademarks of their respective holder(s). This post may contain links to external websites that are not part of Nutanix.com. Nutanix does not control these sites and disclaims all responsibility for the content or accuracy of any external site. Our decision to link to an external site should not be considered an endorsement of any content on such a site.
