

本記事は2020年3月2日にJosh Odgers氏が投稿した記事の翻訳版です。
本シリーズではこれまでにNutanixでは重複排除や圧縮はもちろんのこと、イレイジャーコーディングを利用した場合であったとしても、より高い容量効率、柔軟性、回復力、そして性能をより多くの利用可能な容量とともに、ご提供できることを学んできました。
更に、Nutanixは遥かに簡単に優れたストレージの拡張性を提供でき、ドライブ障害の影響を劇的に低減できることも学んできました。
そこから我々はギアを変え、混在クラスタのサポートについて取り上げ、これがなぜHCIプラットフォームの拡張能力、そして完全な置き換えや新たなサイロを作ることなくより強力なROIを実現に重要であるかを学びました。
前回は、書き込みI/Oパスの比較について学習し、クラスタ内のVMの現在の場所とパフォーマンス/容量の使用率に基づいた、データをインテリジェントに配置するNutanix独自のデータローカリティの多くの長所を取り上げました。
今回は、vSANとNutanix ADSFの読み込みI/Oパスの比較について詳しく説明します。
vSAN読み取りI/O パス:
書き込みI/Oパスの比較で学んだように、vSAN I/O パスの最良のシナリオは、VMが作成されたホストから移動していないか、偶然にもオブジェクトが存在するホストにVMが存在する場合です。その場合、ローカルのデータオブジェクトと、回復力のために別のホストにリモートなデータオブジェクトを持つことになり、IOパスは最適になります。
シナリオ1: vSAN
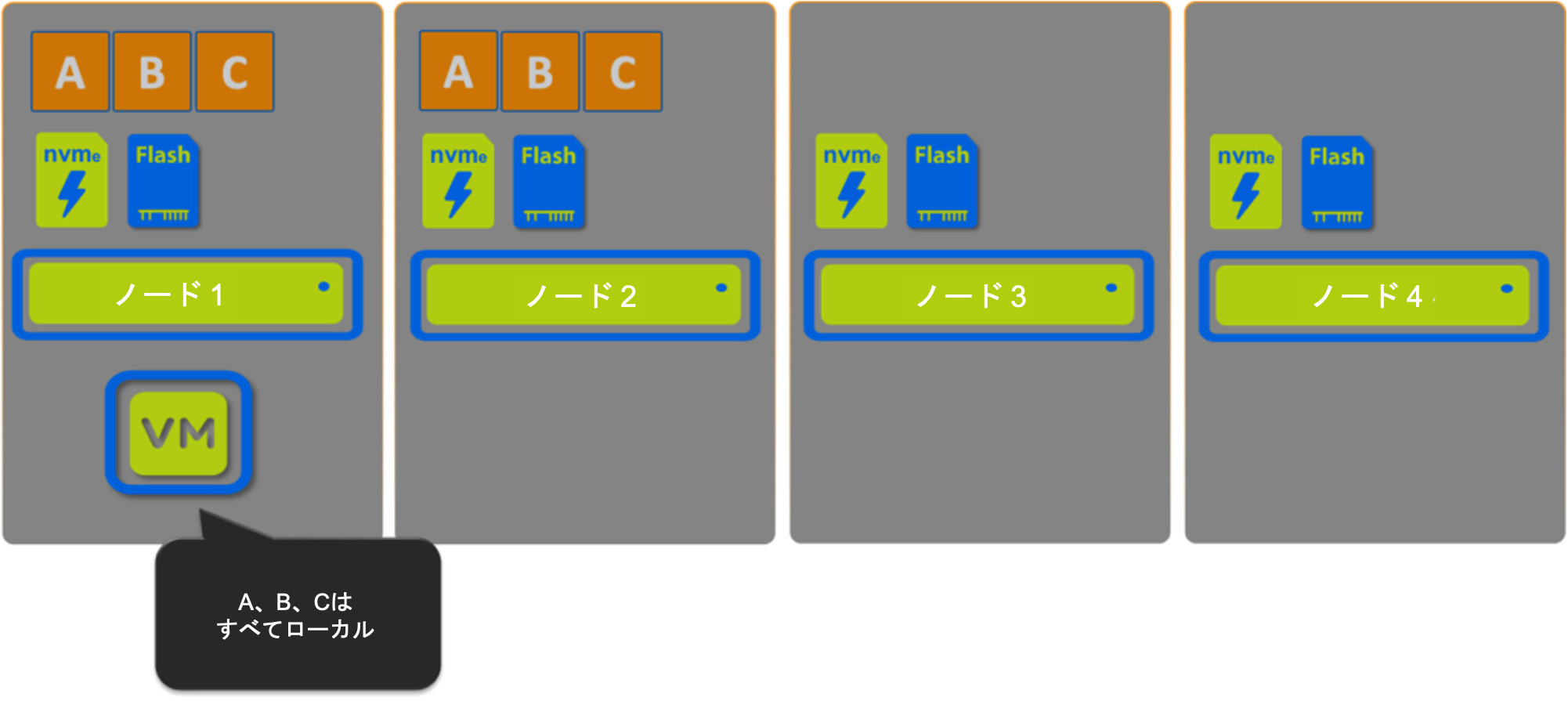
ここでは、すべてのデータがローカルでホストされているため、100%の読み取りをローカルで提供できるように見えます。
しかし、vSANはこのような動作はしません。vSANの読み取りは、すべてのオブジェクトに対する「ラウンドロビン」方式で実行されます。つまり、オブジェクトがVMにローカルであるという最良のシナリオでも、FTT1の場合で読み取りの50%、FTT2の場合は読み取りの66%がリモートから提供されるのです。
シナリオ2: vSAN
シナリオ1でVMをノード2にvMotionしてみましょう。
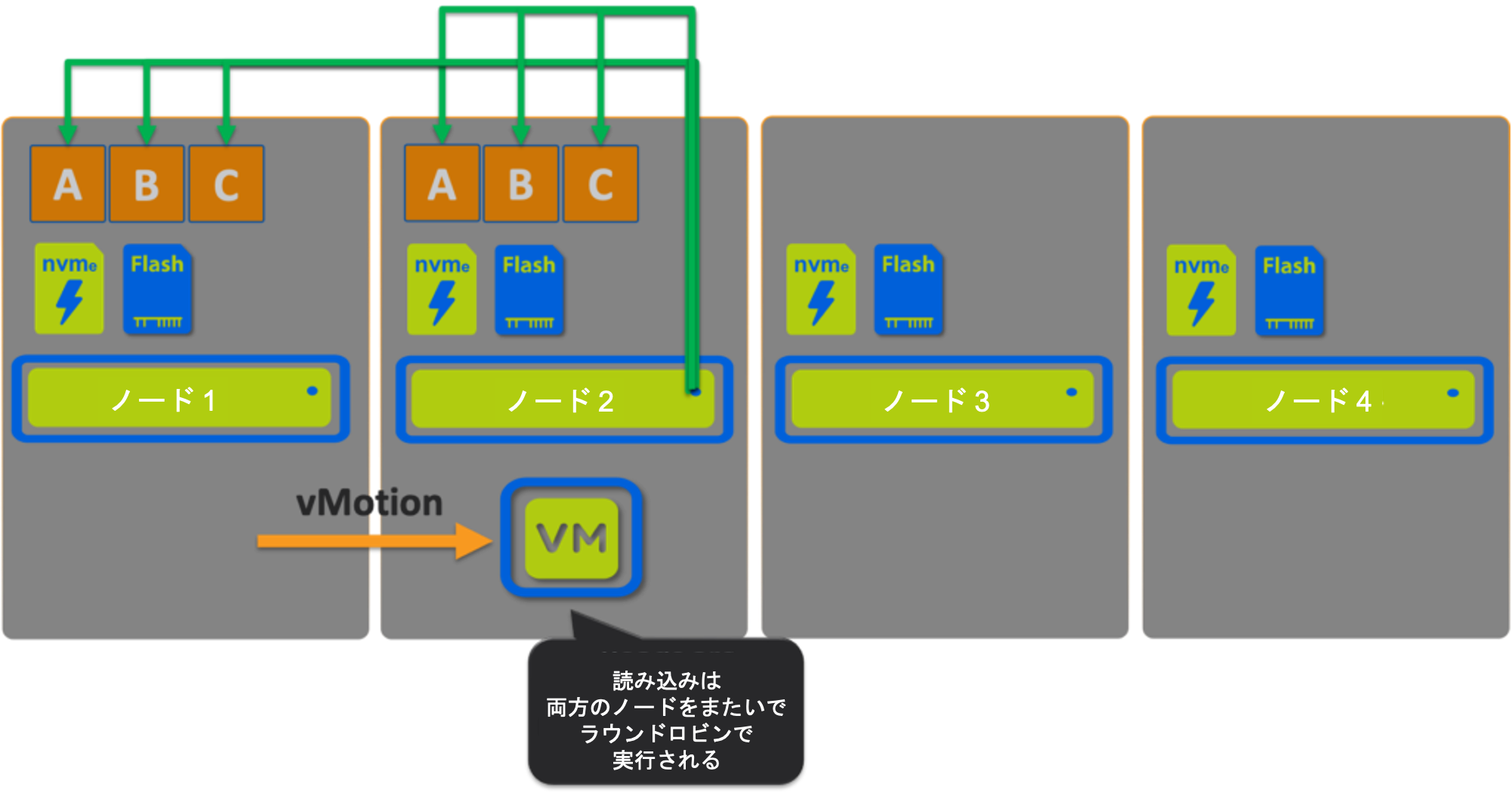
ここでは、すべてのデータがローカルでホストされているので、100%の読み取りをローカルで提供することができるのですが、この場合もFTT1の場合の読み取りは50%、FTT2を使用しているときの読み取りは66%がリモートから提供されます!
シナリオ 3: vSAN
次にVMをノード3にvMotionします。
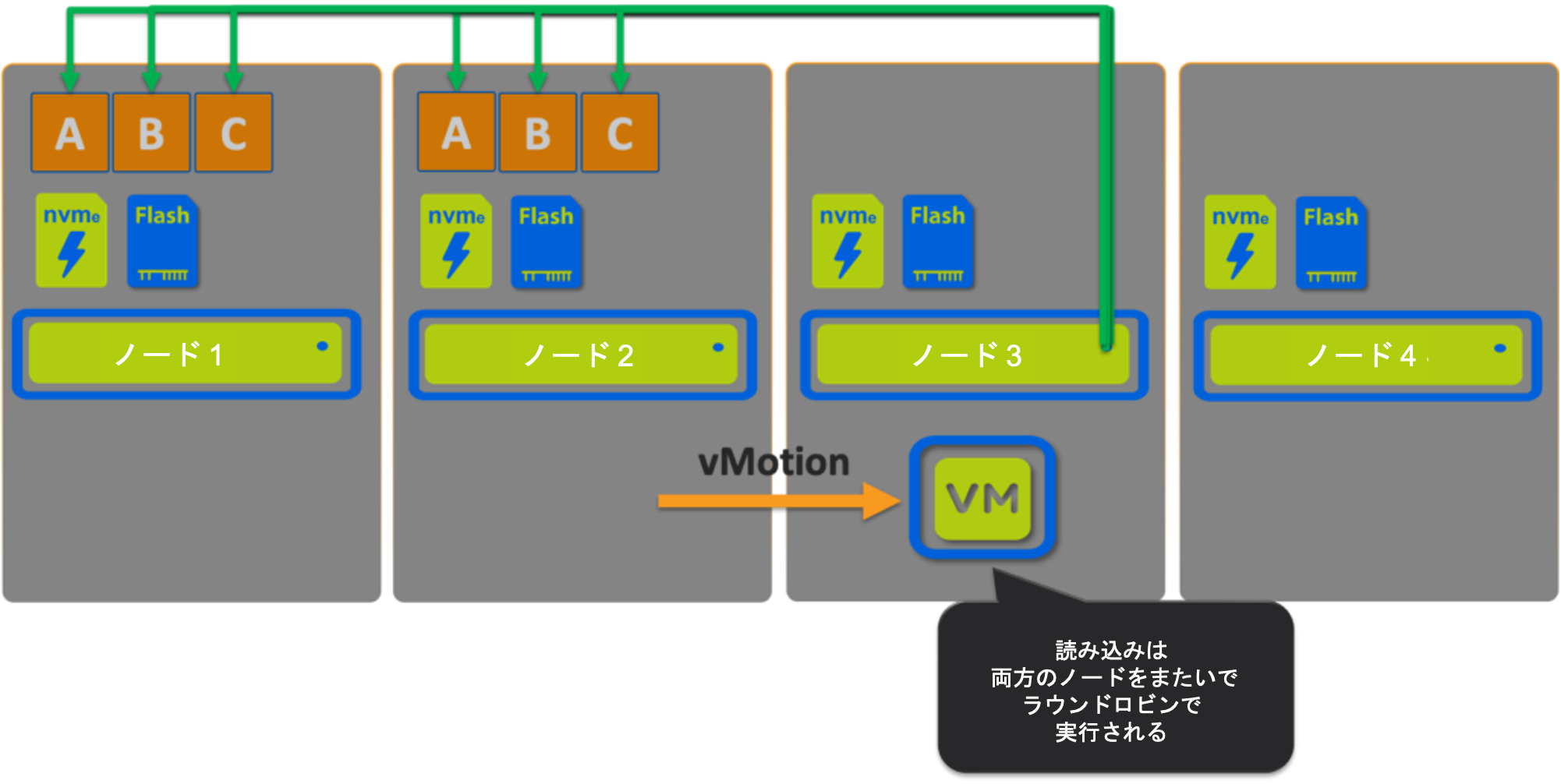
このシナリオは、ローカルでホストされているデータがないため、読み取りの100%をリモートから提供する必要があります。
シナリオ4 vSAN:
このシナリオでは、オブジェクトをVMのローカルにホストしていない2つのVMがあります。
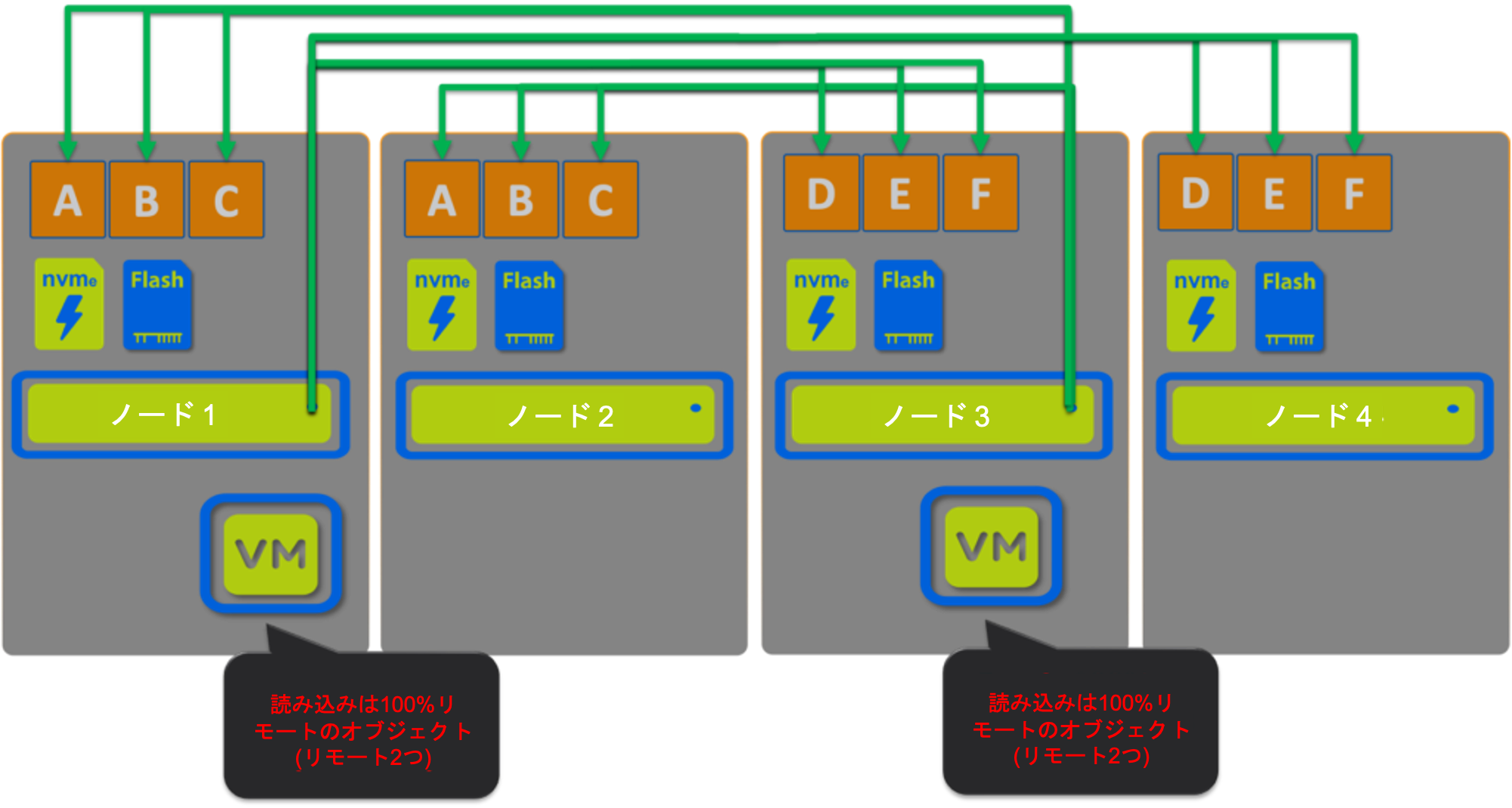
ここでもローカルでホストされているデータがないため、読み取りの100%をリモートから提供する必要があります。
2つのVMを使用したこの単純な例でも、両方のVMに対して100%の読み取りがリモートから提供されているだけでなく、ノード1と3を横断するネットワークトラフィックがノード2と4よりも高く、帯域幅が飽和していなくても競合の原因になる可能性が高いことがわかります。
シナリオ5 vSAN のメンテナンス:
次に、vSANのデフォルト設定であるアクセシビリティの確保の場合、メンテナンス中に何が起こるかを確認してみます。
参照 : https://docs.vmware.com/en/VMware-vSphere/6.7/com.vmware.vsphere.virtualsan.doc/GUID-521EA4BC-E411-47D4-899A-5E0264469866.html
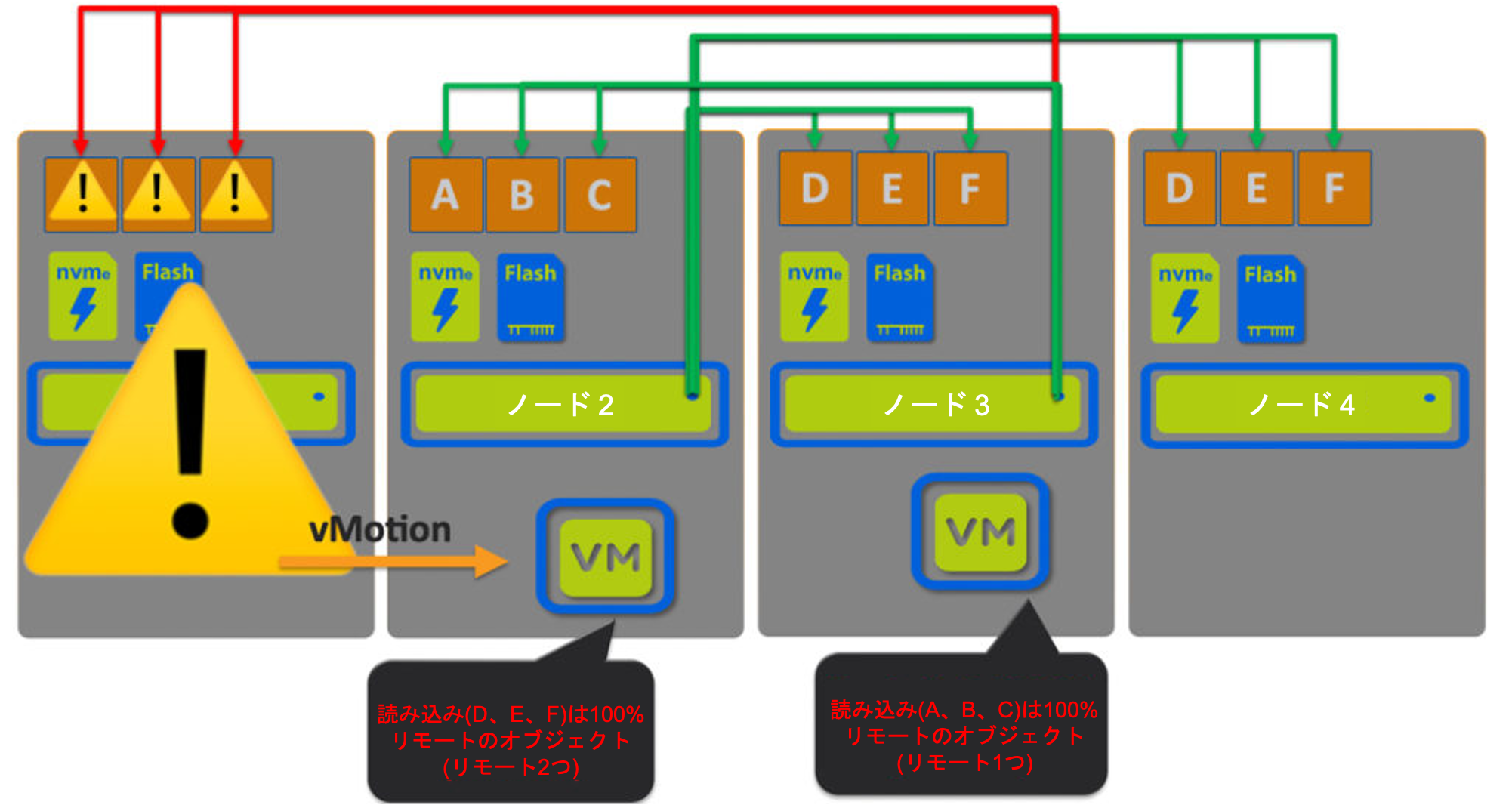
ここでは、ノード1がメンテナンスのためにダウンしており、その結果、オブジェクトA、B、Cは(ノード2上の)1つのコピーしか利用できないことがわかります。オブジェクトD、E、Fは引き続きノード3と4で利用可能です。
ここでは、オブジェクト A,B,C にアクセスしている VM は 100% リモートで、IO を提供しているノードは 1 つしかありません。オブジェクトD、E、FにアクセスしているVMは、2つのリモートノード間で読み取りI/Oのラウンドロビンを行うという最適ではない状態のままです。
また、利用可能な3つのノード間でワークロードのバランスが崩れていることがわかります。
メンテナンス時には、VMの読み取りI/Oパスは大きく変化します。VMは典型的なラウンドロビン方式で、両方がリモートになっている場合もあれば、VMが偶然にも1つ以上のオブジェクトがローカルにあるノードに存在している場合には、50%のローカル読み取りの恩恵を受けることもあります。
vSAN 読み取りI/Oパスのサマリ:
以下の表は、通常の状況下でのvSANの読み取りI/Oが50%だけローカルで、分散して実行されていないことを示しています*。
*高度な/非デフォルト構成を使用していない場合。
多くの場合、読み取りI/Oは100%リモートであることがわかり、これによりvSAN環境はクライアントトラフィックを考慮しなくても競合が発生する可能性がある状況に置かれていることがわかります。
| vSAN シナリオ | 100%ローカル読み取り | ローカル読み取り(新規IO)、分散読取り(既存I/O) | 1つはローカル、1つはリモート | 2つともリモート |
| 1. オリジナルのノード(ノード 1) |
|
| ⚠️ |
|
| 2. オブジェクトのあるノード(ノード 2) |
|
| ⚠️ |
|
| 3. オブジェクトのないノード(ノード3) |
|
|
| ⚠️ |
| 4. 2つ仮想マシンがオブジェクトのないノード上にある(ノード 3 & 4) |
| ️ |
| ⚠️ |
| 5. メンテナンス | ✅* |
| ❓ | ❓ |
シナリオ5「メンテナンス」では、なぜ100%のローカル読み取りを示す緑のチェックが表示されているのか、混乱するかもしれません。
仮想マシンのデータがローカルにホストされており、他のレプリカをホストしているノード(FTT1を想定)がメンテナンスのためにオフラインになっているような状況だけが、仮想マシンが100%読み取りをローカルからサービスされるシナリオです。
vSANのインメモリ「クライアントキャッシュ」とは?
VMwareがこの機能をどのように説明しているかというと、次のようになります。
vSAN 6.2で登場したクライアントキャッシュはハイブリッドとオールフラッシュいずれの構成でも利用され、仮想マシンに対してローカルなDRAMメモリを利用して、読み取りのパフォーマンスを加速させます。割り当てられるメモリの総量はホストあたり0.4%最大で1GBまでです。
キャッシュは仮想マシンにとってローカルですから、データのためにネットワークを介してアクセスすることを回避し、適切にメモリのレイテンシを活用することができます。読み取りキャッシュの効果の高いワークロードで行ったテストでは読み取りのレイテンシを劇的に削減することができました。
参照 : HTTPS://STORAGEHUB.VMWARE.COM/T/VMWARE-R-VSAN-TM-DESIGN-AND-SIZING-GUIDE-2/FLASH-DEVICES-IN-VSAN/
この中で、VMware は、「データを得るためにネットワーク介してアクセスする必要がない」という価値を正しく強調しています。
VMwareは、「読み取りキャッシュの効果の高いワークロードで行ったテストにおいて、読み取りのレイテンシを劇的に削減することができました」と述べています。
私はこれらの記述の両方に強く同意します。不必要なネットワークトラフィックを回避することは、最適なパフォーマンスを実現するためだけでなく、最小限のオーバーヘッドで高いパフォーマンスを実現するためにも非常に重要です。
しかし、私たちが学んだように、vSAN アーキテクチャは、後からの読み取り I/O のためにこれらのレイテンシの多くを回避できるような方法で書き込みを処理しません。クライアントキャッシュには1GBの制限があるので、非常に小さなデータセットや、その長所を強調するように設計された非現実的なテストには有効かもしれませんが、最適なパフォーマンスが一般的に要求されるところでは、はるかに大きなアクティブなワーキングセットが存在することが多く、1GB程度では大きな違いは出ないと考えます。
Nutanix ADSF I/Oパスを見てみましょう。ここでは、ほとんどのケースでネットワーク通信が回避されており、リモート読み取りが必要な場合には、システムは将来のネットワークのノード間通信を最小限に抑えるために、データの配置を細やかなレベルでインテリジェントに管理している傾向がすぐに見て取れます。
Nutanix ADSF IO パス:
書き込みパスの比較から学んだように、Nutanix ADSF上のVMは、VMがクラスタ内のどこに移動するかに関係なく、最適な書き込みI/Oパスを実現します。
ここでは、読み取りI/Oパスがどのようなものかを議論してみましょう。
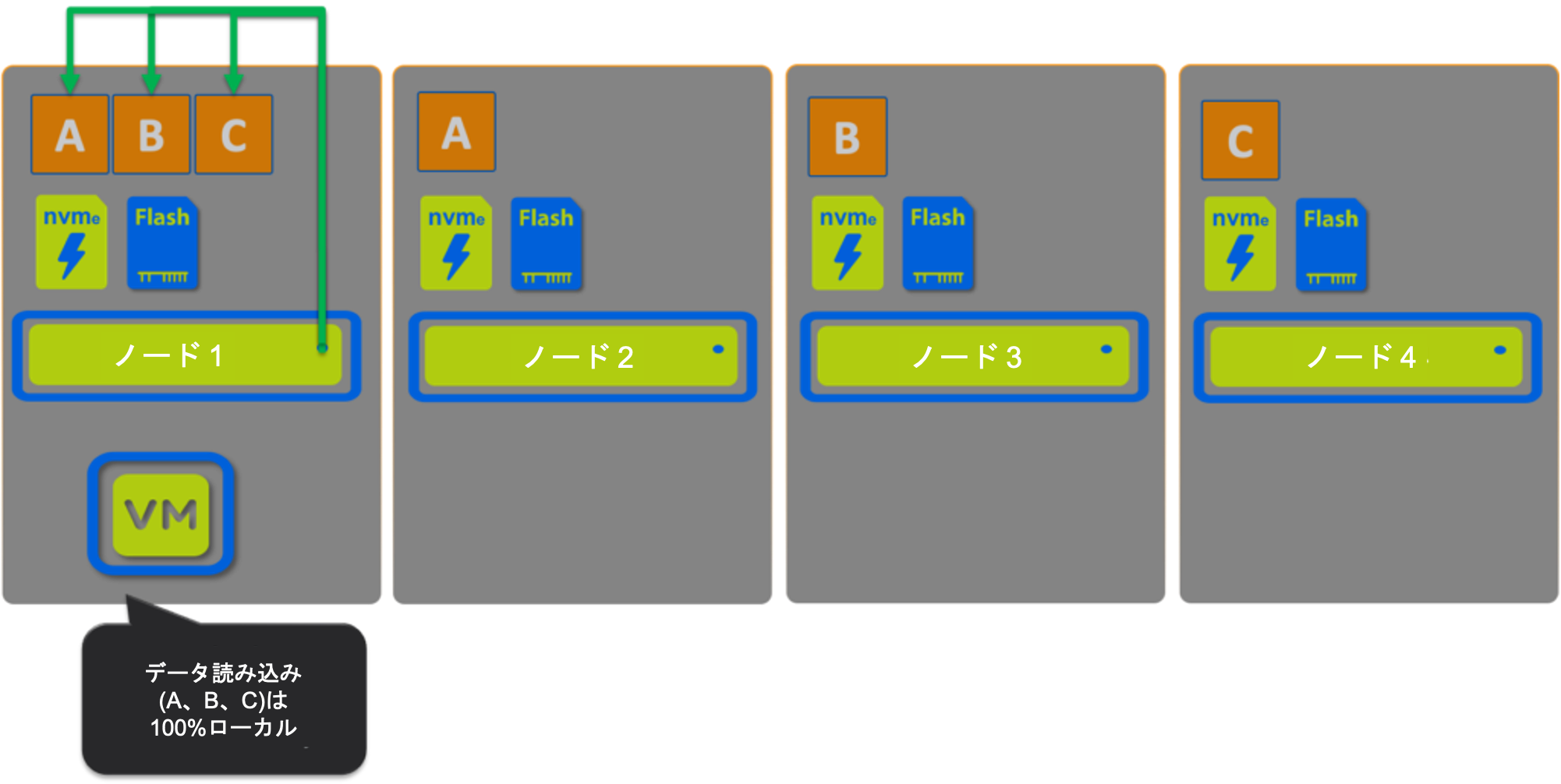
シナリオ1: Nutanix
ここでは、すべてのデータがローカルでホストされていることがわかりますので、100%の読み取りが可能で、ローカルで提供されています。
シナリオ2: Nutanix
ここでは、書き込みI/Oパスの比較で学んだように、VMがノード1からノード2に移動されたことがわかります。
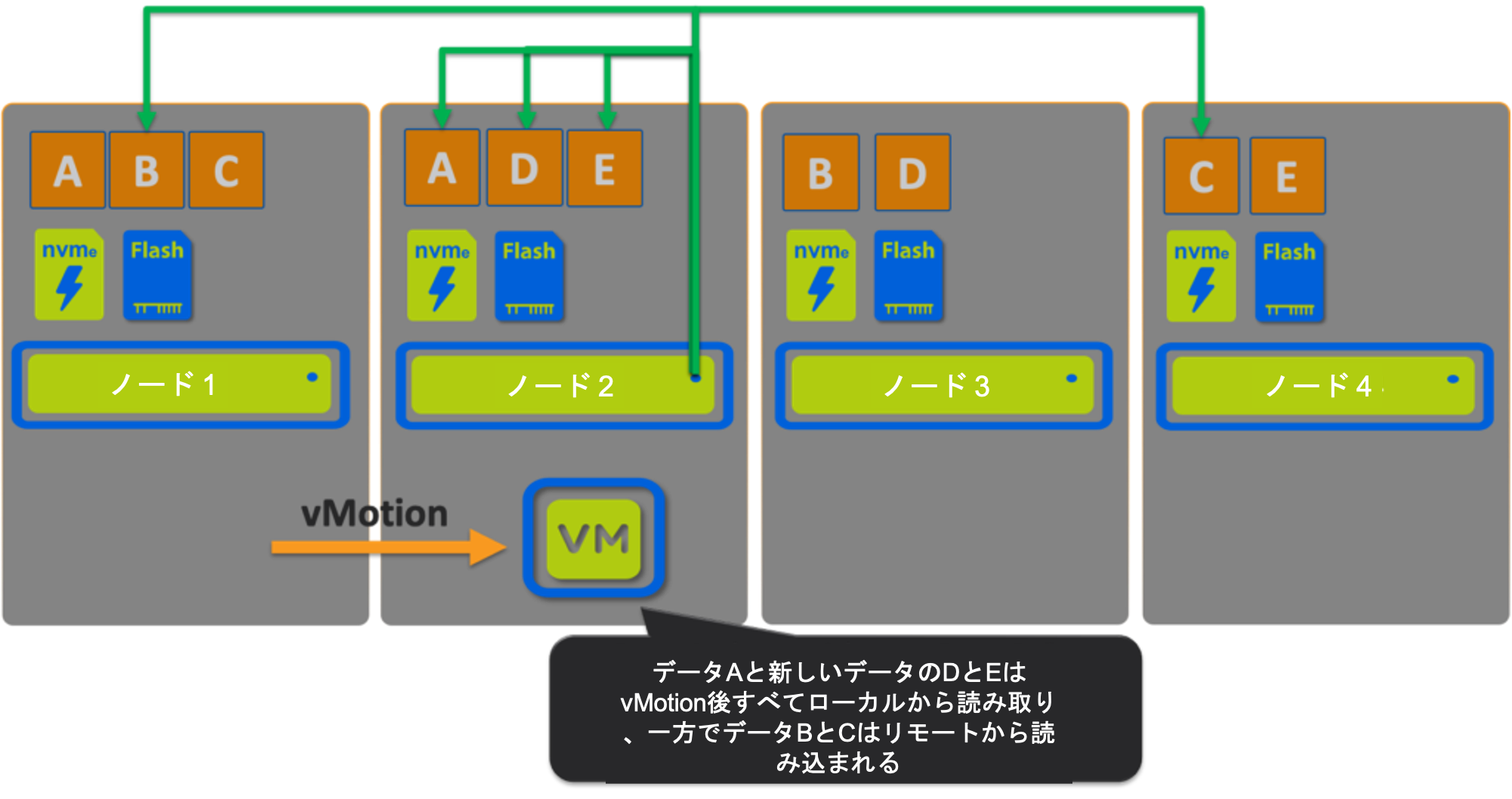
すべてのデータがアクティブ(読み取りホット)であったと仮定すると、これはデータのローカリティのための「最悪のケースシナリオ」と考える人もいるかもしれませんが、vMotionの直後に、読み取りの60%がローカルで、40%がリモートであるという結果になります。
この最悪のケースのシナリオでは、vSANのようにオブジェクトがどこにあるかには関係なく、Nutanix ADSFによってローカルから提供されるデータは、vSANと比較して10%増加します。
読み取りホットデータは、その後に続くリモート読み取りのペナルティを回避するためにローカライズされ、ローカルで提供されるリモート読み取りの割合が増加します。
重要なポイント:データのローカライズは、アクセスされているデータに対してのみ実行され、4MB(エクステント・グループ)レベルの細やかさで行われ、過剰なデータ移動を回避します。
シナリオ3: Nutanix
次にVMをノード3にvMotionします。
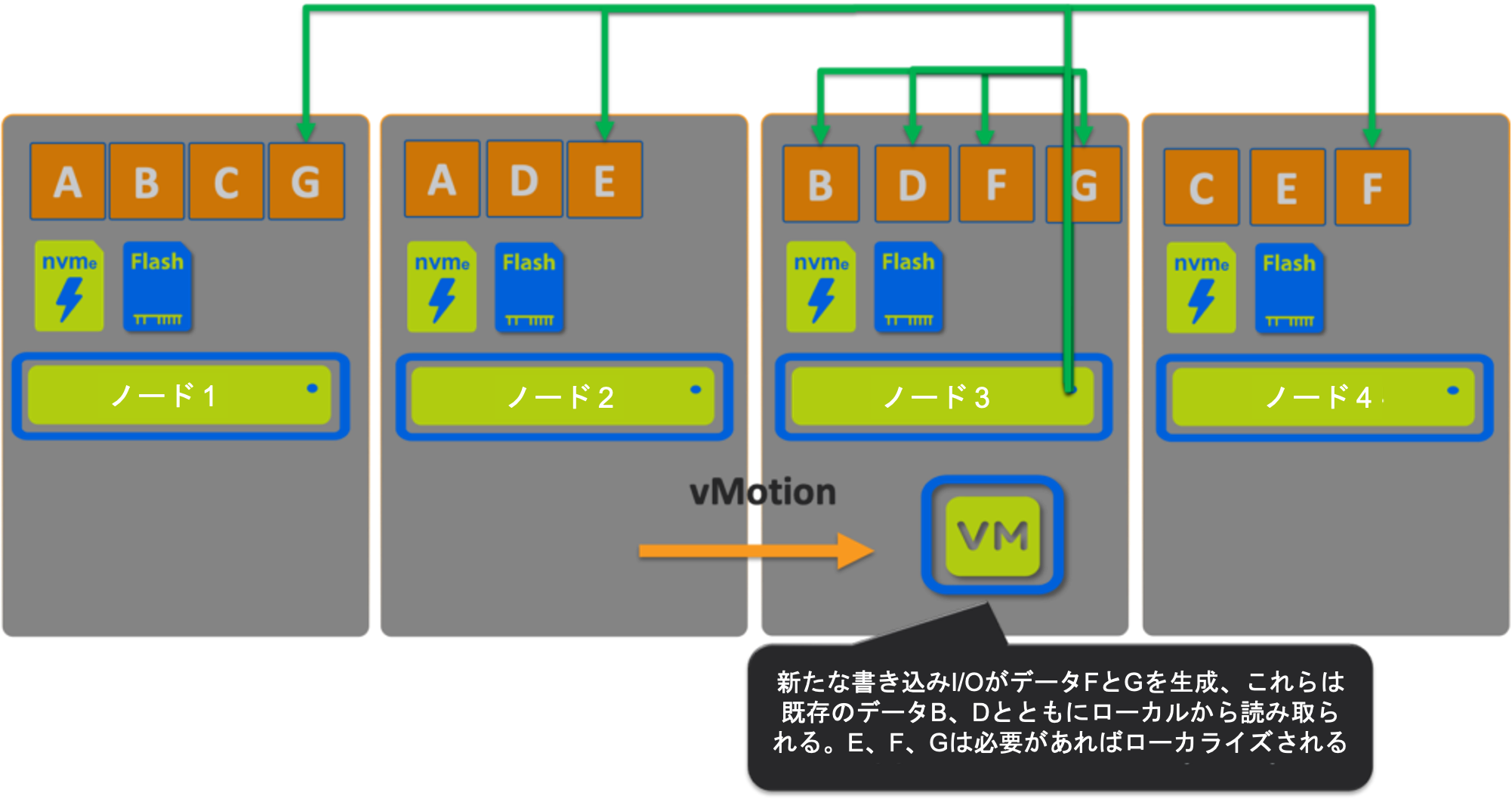
ここでは、7つのデータのうち4つ(~57%)がvMotion後もローカルから提供されていますが、ここでも新しい書き込みはすべてローカルノードに書き込まれ、新しいデータの読み取り I/Oパスを最大化します。
シナリオ2と同様に、リモート読み取りのホットデータは、後続のリモート読み取りのペナルティを避けるためにローカライズされ、新しいIOは常にローカルに書き込まれます。
シナリオ 4: Nutanix
このシナリオは、Nutanixのインテリジェントなレプリカ配置により、IOパスの一部として容量とパフォーマンスの均等なバランスが保証されているため、実際にはvSANと直接比較することはほぼ不可能です。
しかし、Nutanix ADSFの強さを強調することができるので、試してみます。
vSANのシナリオでは、オブジェクトA,B,Cがノード1と2でホストされていました。ADSFでは、このようなシナリオは発生しません。レプリカは、容量の利用率とパフォーマンスに基づいてクラスタ全体に均等に分散されます。
これは、シナリオ1で示したのと同じ状況になります。
2番目のVMがクラスタに追加され、新しいデータを書き込んだ場合、それもローカルに書き込まれ、クラスタ全体に分散され、このような結果になります。
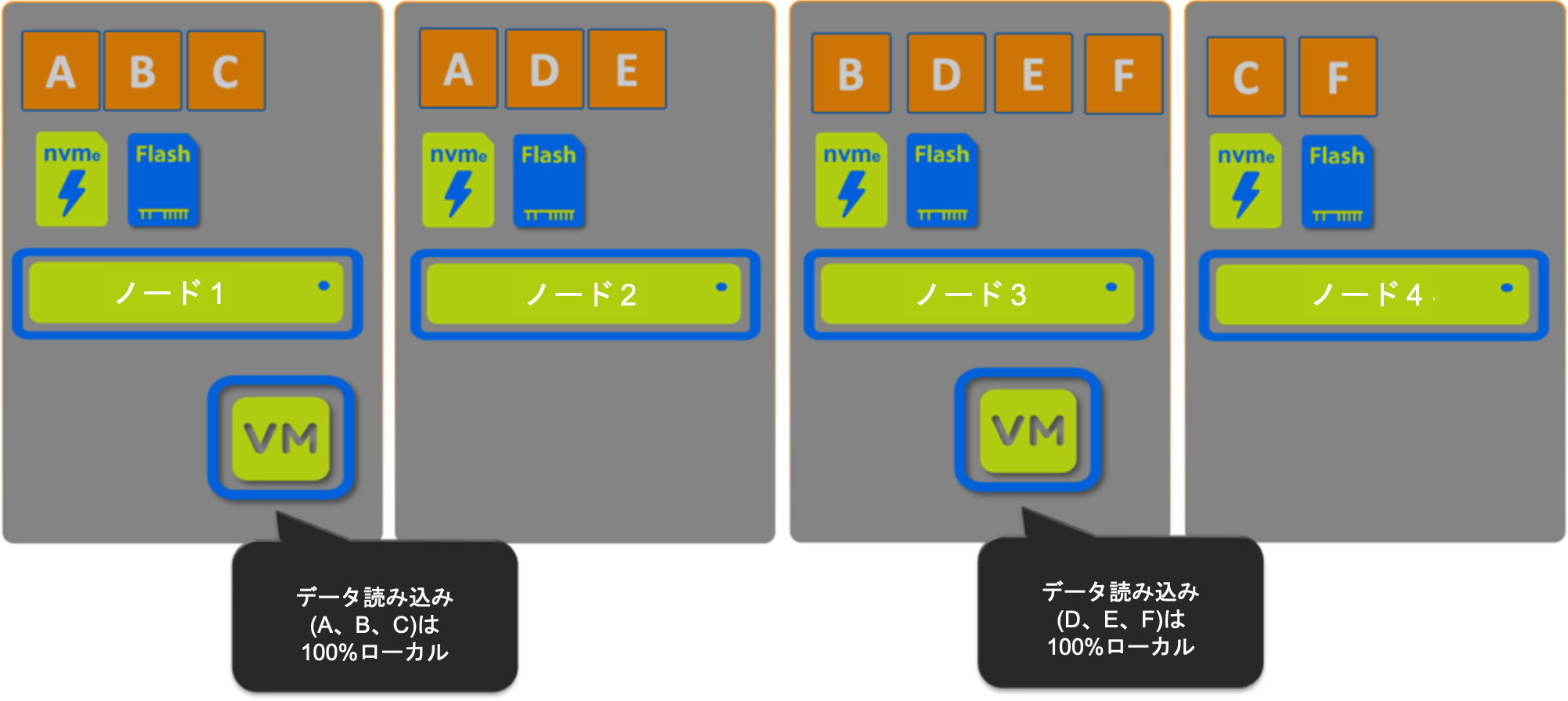
読み取りI/Oの100%がローカルで提供されていることがわかります。
しかし、最悪の場合を想定して、VMは両方ともデータの少ないホストに移動して、それぞれが新しいデータを書き込んだとしたら?
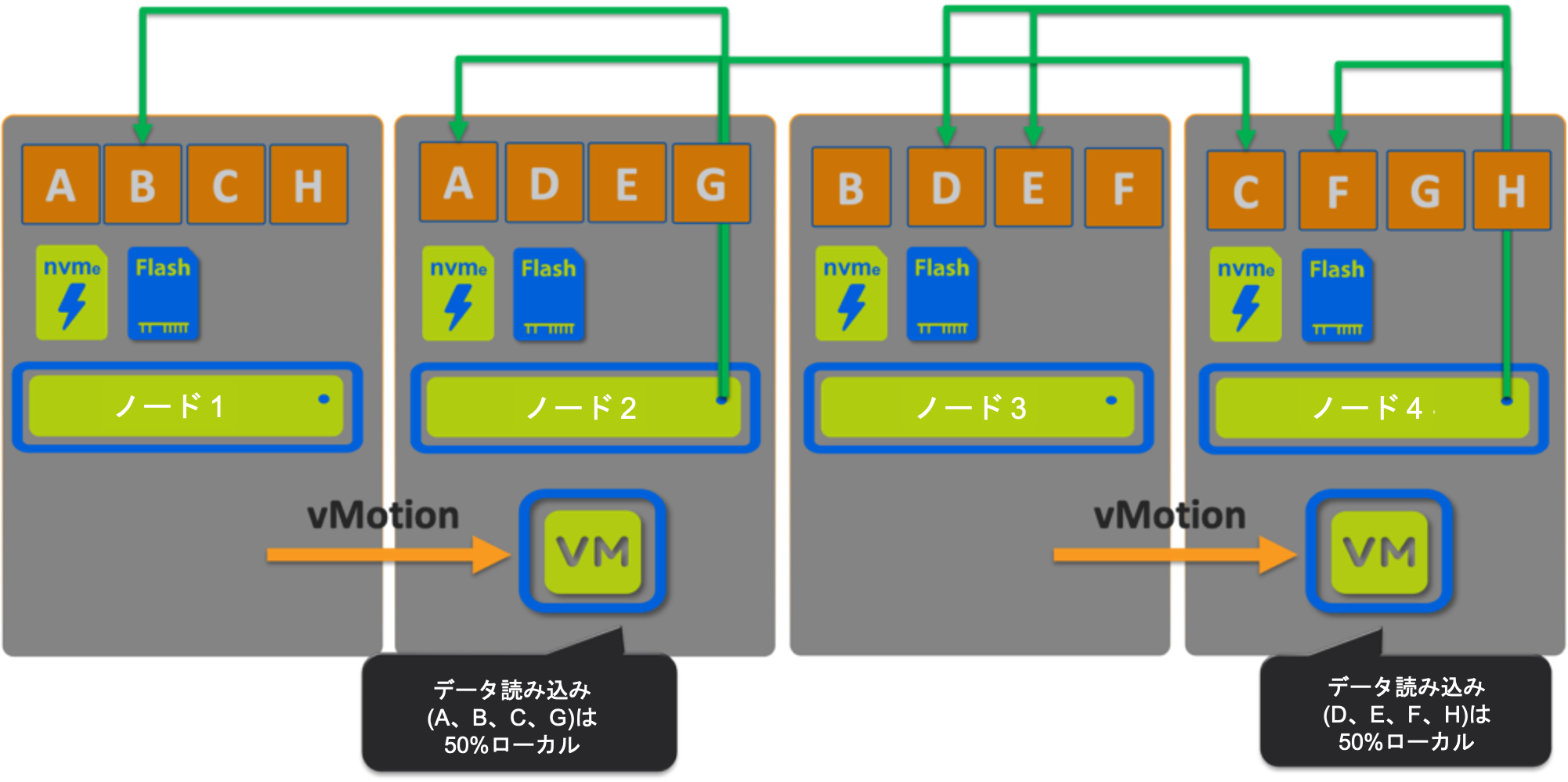
データロカリティの観点で考えられるかぎり最悪の場所
ここでは、VM1 (データ A,B,C,G) と VM2 (データ D,E,F,H) は、最悪の場合のシナリオではまだ 50%をローカルで読み込んでおり、50%は(必要に応じて)リモートから読み込んだ後にローカライズされます。
vMotion後の書き込みはすべてローカルになり、新しい(ホットな)データは自動的にローカルになります。この50%のローカル・読み取り・シナリオは可能性が低いだけでなく、ADSFはインテリジェントに新しいデータを配置して、将来の読み取りがローカルであることを最大化することが明らかになりました。さらに、リモート読み取りは要求に応じてのみローカライズされるため、最適な読み取りパフォーマンスを実現しながらデータの大規模な移動を回避することもできます。
Nutanix ADSF読み取りIOパスのサマリ
次の表は、Nutanix ADSFが読み取りI/O操作の大部分をローカルノードから実行し、最悪の場合(データロカリティの観点から)でさえ、読み取りI/Oは標準でクラスタ内のすべてのノードを利用した効率的な分散型の手法で実行されることを示しています。
| vSAN シナリオ | 100%ローカル読み取り | ローカル読み取り(新規IO)、分散読取り(既存I/O) | 1つはローカル、1つはリモート | 2つともリモート |
| 1. オリジナルのノード(ノード 1) | ✅ |
|
|
|
| 2. オブジェクトのあるノード(ノード 2) | ✅ |
|
|
|
| 3. オブジェクトのないノード(ノード3) |
| ✅ |
|
|
| 4. 2つ仮想マシンがオブジェクトのないノード上にある(ノード 3 & 4) |
| ️✅*
|
|
|
| 5. メンテナンス |
| ✅ |
|
|
* 直接比較できるシナリオは、書き込みI/Oの分散された性質のため、Nutanix ADSFとの比較では利用できませんが、すべての非障害シナリオでは、すべての新規書き込みはローカルでサービスされ、ローカルで読み取ることができます。
この段階までにNutanix ADSFのI/Oパスの方が効率的だと納得していない方には、ボーナスをご用意しました。
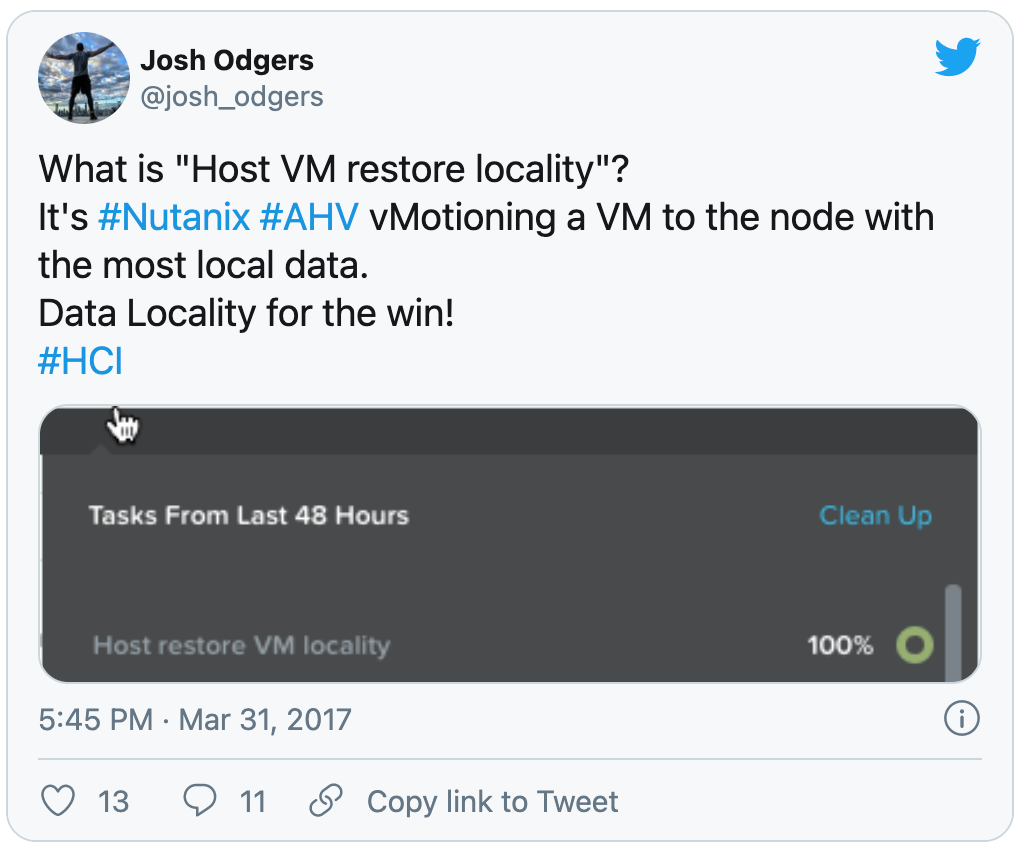
次世代ハイパーバイザー(AHV)と組み合わせたNutanix ADSFは、データを移動するというはるかに影響の大きいプロセスとは反対に、VMが最もローカルなデータを持つホストに戻すことを保証します。
上記のツイートの日付、2017年3月31日に注意してください.... この効率性はNutanixにとって何も新しいことではありません。
サマリ
- vSAN の読み込みパスは、VM がクラスタ内のどこに存在するかによって大きく異なります。
- vSANの静的なオブジェクトベースの書き込みパスでは、特にvMotionの後の最適な読み取り操作が可能になりません。
- Nutanix ADSFは常にローカルノードへの書き込みI/Oを維持しているため、後続の読み取り操作がローカルノードからサービスされることを可能にします。
- Nutanix ADSFは、VMがクラスタ内のどこに存在するか、または移動したかに関わらず、一貫した書き込みパスを提供し、新しいデータやホットなデータがローカルから読み込まれることを保証します。
- VMが頻繁に移動するというNutanix ADSFの最悪のシナリオでは、データがローカルに提供される割合が高くなり、リモート読み取り(必要な場合)は一部のノードに限定されることなく、クラスタ全体に分散した方法でサービスされます。
- Nutanixのデータローカリティはプロアクティブであり、vSANのクライアントキャッシュのように1GBに限定されていません。
Nutanix ADSFは、偶然ではなく設計によってデータロカリティを享受しています。