


With the introduction of Elasticsearch® 7.13, the Elasticsearch®’s feature of searchable snapshots is fully GA. If you are running Elasticsearch® with Nutanix Objects, you now have the option of having cold nodes that have a single copy of a shard backed up by snapshots stored in an S3 bucket or frozen indexes where no data is stored on the actual data nodes, and they only access the snapshots when needed.
This can greatly decrease the number of data nodes required as a single frozen node can handle 100TB of data. This is great news for organizations that keep data around long term, but still have occasional searches against this data. I also had an inquiry recently where a customer had to ingest 3TB a day but there were rarely any searches, and the data had to be kept for a year. This is another great use case as you can lifecycle the indexes from hot to frozen rather quickly and use very few data nodes.
The new searchable snapshots feature gives you even more reasons to run Elasticsearch on Nutanix® HCI. Nutanix can give you a single platform and management pane for your Elasticsearch clusters from deployment, to hot, to frozen. I have written about running Elasticsearch on Nutanix here and how Nutanix can increase your uptime and performance during failures here. Now I am going to show how Nutanix can help you store your snapshots and make the management of your Elasticsearch clusters easier.
Nutanix Objects is a feature that you can deploy either in a shared cluster or with an Objects dedicated cluster. Objects can span multiple Nutanix clusters and easily grow and handle multi-petabyte scale. Deploying Objects takes about 5 clicks, and it deploys in around 15 minutes, then you can start creating buckets.
Nutanix Objects is fully replicated and uses all the Enterprise storage features that Nutanix offers including compression and EC-X which will reduce the amount of space needed to store your data. With Objects you can also enable WORM to make sure data is never changed, and versioning to save data from being overwritten or changed.
We will start with deployment. I deployed a small Elasticsearch cluster in my lab with a Nutanix Calm™ blueprint. Calm is Nutanix’s automation platform for deploying VMs and applications.
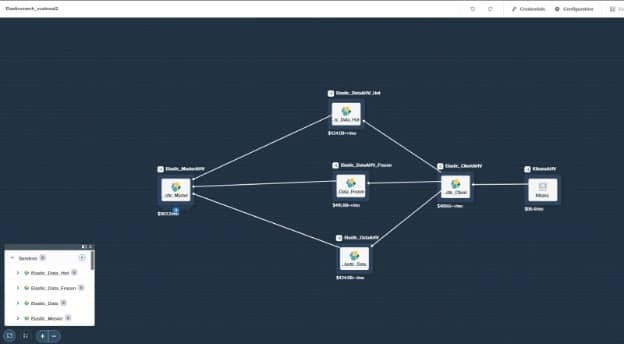
In Figure 1, you can see I have my Elasticsearch deployment built out in a single blueprint. This will deploy on our AHV™ hypervisor. I am deploying multiple hot, frozen and management nodes as well as my Kibana® instance. Everything is configured to automatically start and be ready to start indexing data. The S3 plugin is enabled on all the Elasticsearch nodes in the deployment. To deploy my Elasticsearch cluster and have it up and running took about 8 minutes.
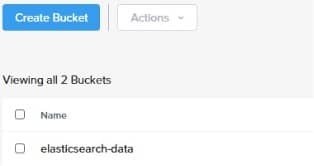
For this test I have created a bucket called “elasticsearch-data”. To create a bucket is very easy. I click “Create Bucket”
I fill in the name for my bucket and can enable versioning or lifecycle policies for objects then click Create.
With Objects IAM, I can add users that have access to the buckets I create to generate and download the access and secret keys that I will need to add to Elasticsearch for access.
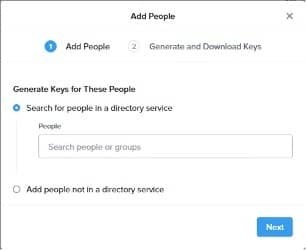
For my bucket I have added myself as a user with read/write access and downloaded my keys. To add the keys to Elasticsearch keystore you will have to use the following commands:
sudo /usr/share/elasticsearch/bin/elasticsearch-keystore add s3.client.default.access_key
sudo /usr/share/elasticsearch/bin/elasticsearch-keystore add s3.client.default.secret_key
After that is completed on all nodes you can use the following commands to make sure the settings are reloaded
POST _nodes/reload_secure_settings
Once that is done you can add the object store to Elasticsearch with the PUT _snapshot command.
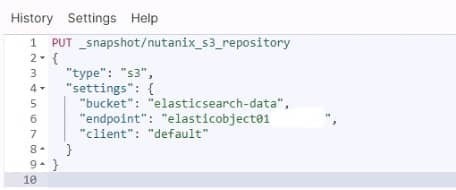
As you can see in Figure 5, I named my repository “nutanix_s3_repository”, I put in the bucket name I created earlier and the endpoint of “elasticobject01” is the Nutanix Objects deployment in my cluster.
Once this is done you can go into your stack management and look at “Snapshot and Restore” then Repositories and see the bucket listed.
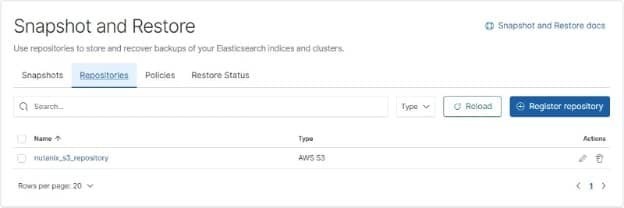
Now we will need to set up our ILM policy to automatically rollover our indexes. I am rolling these over very fast just to get the indexes into the frozen tier but obviously how fast will be up to your individual needs.
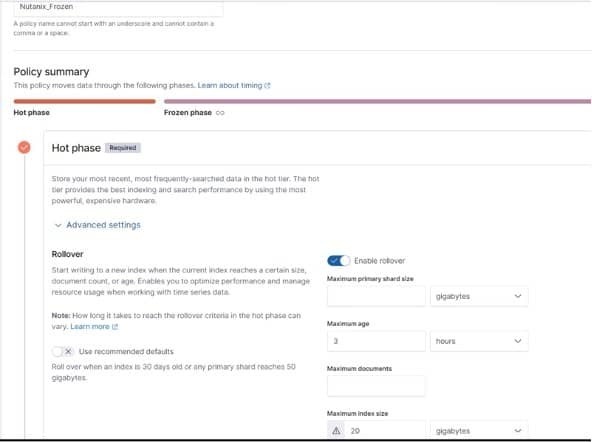
I am naming the policy Nutanix_Frozen I have it rolling over the Hot Index at either 3 hours or 20 gigabytes.
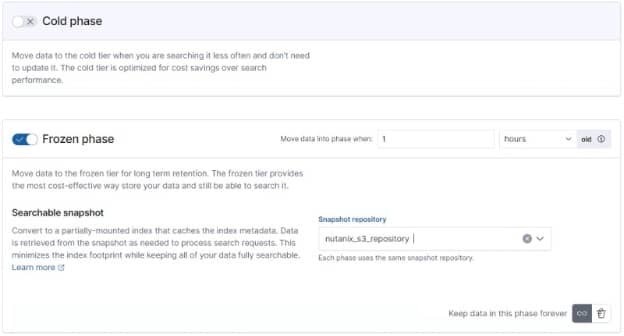
I then have it setup to Frozen after 1 hour and have configured which repository the snapshots will be stored in.
Now I am going to use Rally to create the data for my indexes, specifically the continuous and query challenge of the eventdata track. Now I have changed the index template for this, so it has the lifecycle policy that I need.
{
"index": {
"lifecycle": {
"name": "Nutanix_Frozen",
"rollover_alias": "elasticlogs_q_write"
}
After running the test and waiting for some of the indexes to rollover to frozen you can see the difference in how they look on the cluster.
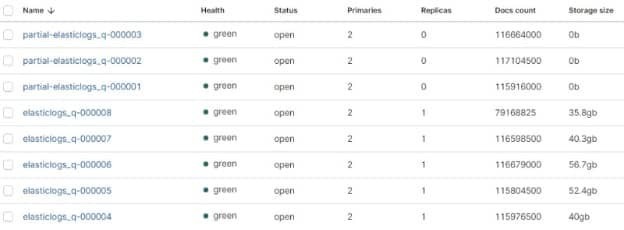
The “partial” indexes are the snapshot based frozen indexes. They say 0b because none of the storage is based on the data nodes themselves but completely on the Object storage. If you had months of indexes you had to store you would not need as many elastic data nodes to store the data.
How do I see what is going on with the Object storage? It’s visible from the NutanixPrism Central™ management console just like when you create an Object store, so you can monitor and manage it also.

You can see the basic information about the bucket in Figure 10, above with how much space it is taking and the number of objects as well as configuration information.
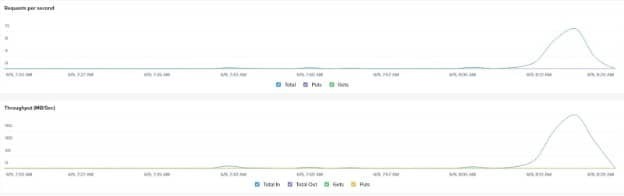
In Figure 11, I executed multiple searches against the frozen indexes so it would access the objects store. In Prism you can see the throughput and request metrics for the object store as requests are coming in. Since your object store is very close to your Elasticsearch cluster it makes it so there is very little latency between your data nodes and object store.
With the Nutanix platform, you can manage your entire Elasticsearch cluster lifecycle from Prism Central. The Nutanix platform lets you manage automation, VM’s, data, and Objects all from a single pane. One final thing though, with Nutanix Objects, you can use Nutanix builtin replication to replicate your object store to another site for Disaster Recovery and use the same deployment method shown here to get a new cluster up and running and restore the indexes from snapshots with Nutanix Objects.
Nutanix can greatly ease your overall management and lifecycle of your Elasticsearch clusters. To learn more about Nutanix Objects and to take a Test Drive head over to the Nutanix Objects Page.
This post was authored By Gabe Contreras, Nutanix
© 2021 Nutanix, Inc. All rights reserved. Nutanix, the Nutanix logo and all Nutanix product, feature and service names mentioned herein are registered trademarks or trademarks of Nutanix, Inc. in the United States and other countries. Other brand names mentioned herein are for identification purposes only and may be the trademarks of their respective holder(s). This post may contain links to external websites that are not part of Nutanix.com. Nutanix does not control these sites and disclaims all responsibility for the content or accuracy of any external site. Our decision to link to an external site should not be considered an endorsement of any content on such a site. Certain information contained in this post may relate to or be based on studies, publications, surveys and other data obtained from third-party sources and our own internal estimates and research. While we believe these third-party studies, publications, surveys and other data are reliable as of the date of this post, they have not independently verified, and we make no representation as to the adequacy, fairness, accuracy, or completeness of any information obtained from third-party sources.
This post may contain express and implied forward-looking statements, which are not historical facts and are instead based on our current expectations, estimates and beliefs. The accuracy of such statements involves risks and uncertainties and depends upon future events, including those that may be beyond our control, and actual results may differ materially and adversely from those anticipated or implied by such statements. Any forward-looking statements included herein speak only as of the date hereof and, except as required by law, we assume no obligation to update or otherwise revise any of such forward-looking statements to reflect subsequent events or circumstances.