That's the slick part of this - there wouldn't be a performance impact if setup correctly. Stargate and Curator will just not use the other disks as a target for the data or it's replicas. This does mean that one application will fill up before others. When they start to run out of space I would say they should spin out a new cluster rather then expanding this cluster (makes it easier to manage and just nicer over all)
If setup incorrectly (for example by not keeping the VMs on the hosts that have their SP's disks) we would lose data locality, but that's about it.
And yes, Zookeeper and Cassandra will continue on as normal. Assuming 3 2-node blocks, you should keep ZKs on separate blocks but beyond that it doesn't matter too much. There's a couple of choices you can have for actual deployment:
1) Ability to shutdown block without affecting any layer
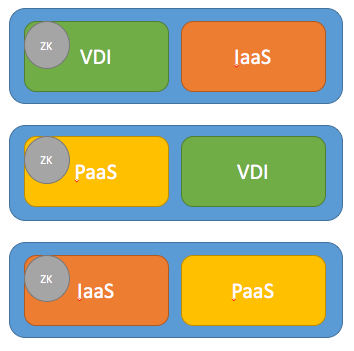
In this deployment any block can fail without taking down any of the layers, but if you need to shutdown one of the layers for maintenance you need to shutdown the whole cluster
2) Ability to shutdown application without affecting other applications:
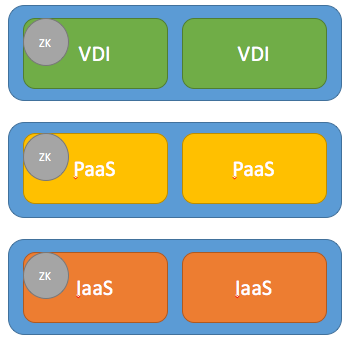
In this case any application can go down without affecting the other applciations, but if they want to shutdown a block for some reason {EDIT:} an application layer needs to go down {not the whole cluster}
Just to add another wrech to the deployment, you could do an RF3 cluster with RF2 containers. In that case you can lose 2 nodes without affecting the cluster as a whole, but if both nodes failures are from 1 application that application will go down without affecting the other applications. This plus the setup from the first scenario up there give you the ability to withstand both failure scenarios. There is a small performance hit here. They also wouldn't be able to spin out the nodes into a new cluster easily here (as RF3 requires 5 nodes) which makes this a less then ideal solution.




