

本記事は2020年10月05日にGary Little氏が投稿した記事の翻訳版です。
原文はこちら。

今回紹介するのは、ベンチマークVMの再利用、さらに重要なデータセットの再利用により、X-Rayベンチマークの実装サイクルを高速化する方法です。

課題:大規模なデータセットを利用する場合、ディスク上でのデータ作成に時間がかかることがある
ノードあたり2TBを書き込み、ノード間のバンド幅が10GbEであるクラスタを考えてみましょう。十分なストレージ帯域性能があると仮定すると、スループットはワイヤーバインドとなり、プリフィル(事前のデータ埋め)ステージは2,000秒(1GB/sec換算)、つまり30分以上かかることになります。モデル化されたワークロードが開始されるまでに30分も待つのは、なかなかのストレスです。
ワークセットサイズが比較的小さいシナリオであったとしても、X-Rayのベンチマーク用VMのプロビジョニングとX-Rayワークロードの実行を分割することで効率化が図れます。また、VMを再利用すれば、クローン、ブート、IPの確立などのコストを避けることができます。これは、シナリオを繰り返し実装する際に非常に有効です。
解決策:複数のテスト/シナリオ間でVMを再利用
典型的なアプローチは、シナリオを2つのパートに分けることです。
- パート1:X-Rayシナリオで、VMのクローンを作成、ブートして、ディスク、データ投入を行う「デプロイシナリオ」
- この「デプロイシナリオ」(=ベンチマーク用VMの準備)は一度だけ実行します。
- パート 2:X-Rayメインワークロードを含む「X-Ray実測シナリオ」。パート1で配置されたVMを再利用します。
- この2つの別々パートでデプロイ、実行されるVMを関連付けるために、Curie VM ID※の概念を使用します。
※X-Ray(X線)にちなんで、キュリー夫妻に掛けて、X-RayでデプロイされるVM名のプリフィクスにcurieが利用されていることに由来している模様
重要な注意事項
- 「デプロイシナリオ」から"teardown"(ベンチマーク後処理)ステップを削除する
- 「X-Ray実測シナリオ」から" CleanUp"ステップを削除する
- "teardown"や" CleanUp"のステップを含む「標準の」シナリオは、たとえ「id」を使用していてもVMをクリーンアップしてしまう
- 「デプロイシナリオ」と「X-Ray実測シナリオ」の間で、「Curie VM id」が同じであることを確認する。
- 「X-Ray実測シナリオ」が実行されるたびに一意のRunIDが生成され、ワークロード識別子がそのRunIDを使用することを確認する。
※補足:通常X-Rayで定義される「標準の」シナリオでは「デプロイシナリオ」と「X-Ray実測シナリオ」がまとめて定義される、本記事ではそれを再利用可能なよう分離してX-Rayを実行することを趣旨としている
使用例:
ある X-Ray テストで作成された一連のVMを、それに続くX-Rayテストに紐付けるための IDを定義します。今回は255という数字を使用します。これらのVMを再利用は、毎回同じ「タグ」id:255を指定することで可能になります。次に、同じVMで同じシナリオを再実行するたびに、「runid」を生成し一意になるよう※にします。このステップを踏まないと、VMを再利用しようとしたときに、シナリオがすぐに終了してしまったり、何らか動作不良を起こしてしまいます。最後に、runidがワークロード名の一部として使用され、実行ステップ(run:)でそのワークロードが呼び出されることを確認します。
※ここでのid:255は、「デプロイシナリオ」と「X-Ray実測シナリオ」を紐付けるために利用されるIDで、runidは、X-Rayがベンチマーク実行時の管理番号であり、同一のシナリオを実行した場合でも、ベンチマーク実施ごとに実行結果を別々に管理するのに利用するためのID
name: server_virt_simulator_setup_step
display_name: "Server Virtualization simulator setup"
summary: Server virtualization 75 Per node.
id: 255
estimated_runtime: {{ _estimated_runtime }}
{% set runid = range(1,9999999999)|random %}
presets:
small:
vars:
_estimated_runtime: 3600
_node_selector: ":n"
_iops_expected_value: 40
...<中略>
workloads:
SRV_VIRT_WLOAD {{ runid }}:
vm_group: SERVA
config_file: {{ workload_file }}
...<中略>
run:
- workload.Start:
workload_name: SRV_VIRT_WLOAD {{ runid }}
これで、最初のワークロードを実行することができ、VMのセットアップとプリフィルを行うことができるようになりました。そして、VMのクローン、プリフィル、パワーオンを待つことなく、同じVMセットでベンチマークのためのワークロードを実行できます。
なぜデフォルトシナリオでやらないのか......?
通常、X-Rayでは、(各シナリオに基づいて)VMは毎回ゼロから作成されます。このため、ディスクの数やサイズ、CPUの割り当て数などをいちいち覚えておく必要はありません。これは、(シナリオに)これらの変数がベンチマーキングの一部として埋め込まれているためです。言い換えると、テストのすべての要素が、(a)毎回作成され、(b)テストは明文化されるため、Worker VMについて何も記憶する必要がないのです。Worker VMはエフェメラル(一時的で短命)で、ベンチマーキング期間中にのみ存在します。まるでマイクロサービスパターンのように、です。この種のべき等性は、コードとしてのベンチマーク(benchmarking as code)を実現するための鍵です。
...そして、(デフォルトではないが故に)デメリットがあってもやりたいと思う理由...
ただし、特に調査フェーズでは、ベンチマーク開発者はテストの健全性よりも反復速度を最適化したいと思うかもしれません。そのため、この手法はX-RayベンチマークVMを再利用する機能はデフォルトの動作ではありませんが、それが可能です。
Prism上での見え方
Prism UI からVM名の変更を確認できます。X-RayのWorker VMのデフォルトの命名方式は…
__curie_test_<random_number>_vm_group_name>_<index>
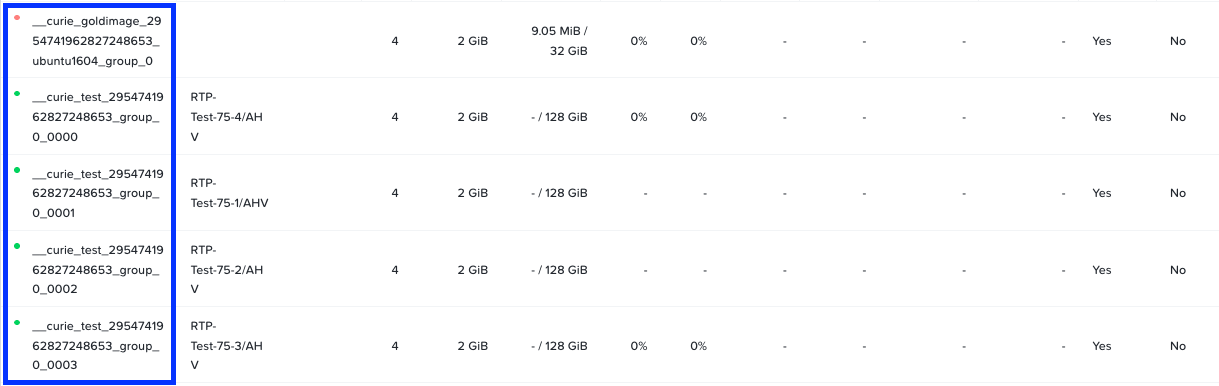
あるテストで生成された VM を後続のテストで再利用したい場合、どの VM を使うかを X-Ray に指示する必要があります(システム上には数百の VM があり、__curie_test_<something> という名前の VM がいくつか存在する可能性があります)。
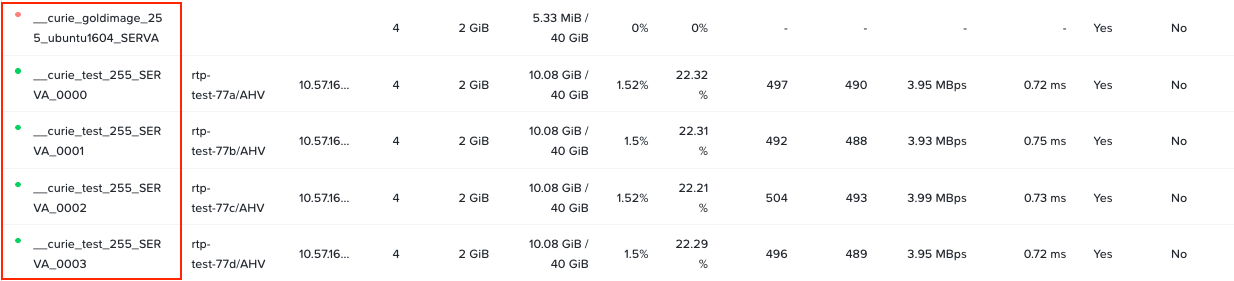
これは、この再利用の仕組みを使った場合のVM名の様子です。ランダムな名前のVMを新たに生成するのではなく、自分自身のID(今回の場合は前述で例示した)255を指定して再利用します。
再利用の仕組みを使うと、Prismは以下のような名前のX-RayワーカーVMを表示します:
__curie_test_<my_id>_vm_group_name>_<index>
謝辞:
このテクニックに至る道筋を示してくれたBob AllegretiとBill Eubanksに感謝します。