

本記事は2018年5月31日にJosh Odgers氏が投稿した記事の日本語版です。
パート1では、Nutanix AOSがAcropolis分散ストレージファブリック (ADSF)のおかげで、ノード障害からのリビルドを高速かつ効率的に行う能力について説明しました。パート2では、ストレージコンテナがどのようにしてRF2からRF3に変換されるのか、また、その操作が完了するまでのスピードについて、紹介したいと思います。
今回のテストでは、クラスター内に12台のノードしか存在しません。
まず、ストレージプール容量の使用状況から見てみましょう。
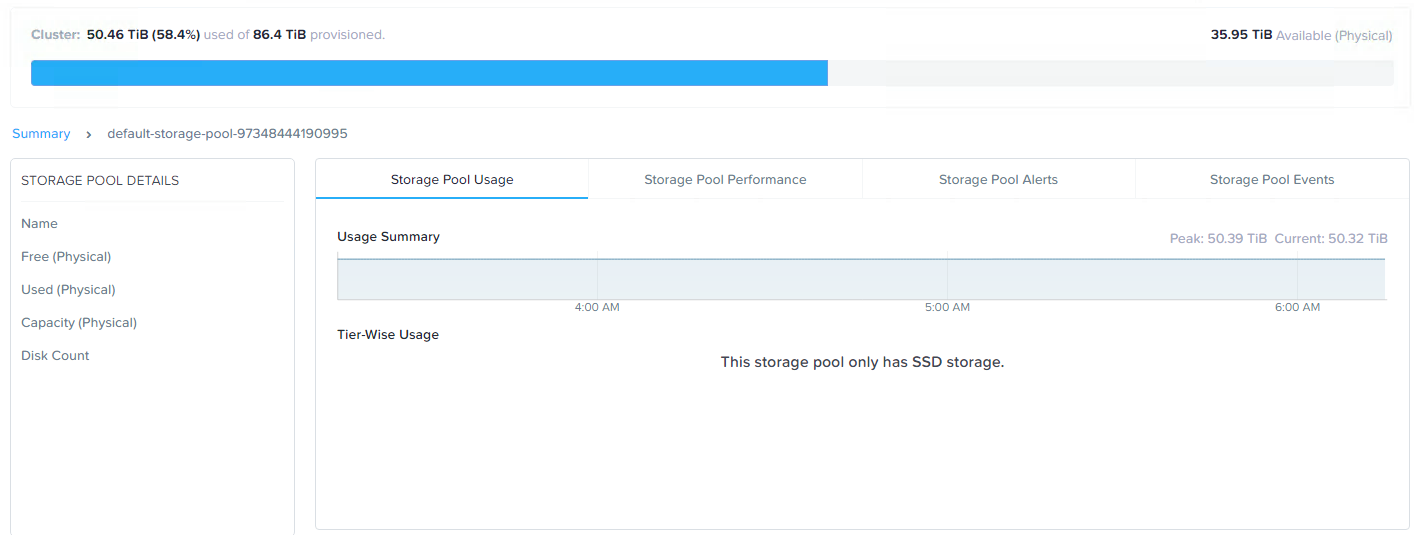
現在、クラスター全体で50TB超のストレージ使用量であることが確認できます。
RF3への変換、つまり簡単に言えば全データの3つ目のレプリカを追加する際には、十分な空き容量を確保する必要があり、さもないとRF3のコンプライアンス上、問題があります。
次に、クラスタ(およびメタデータ)のRedundancy Factor(冗長化係数)をRF3に増やします。これにより、クラスタはRF3コンテナをサポートし、メタデータの観点からは少なくとも2つのノード障害に耐えることができます。
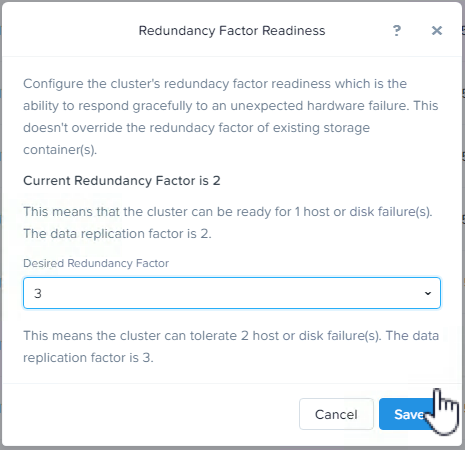
次に、対象のストレージコンテナをRF3に増やします。
コンテナがRF3に設定されると、Curatorはクラスターが設定されたRedundancy Factorに準拠していないことを検出し、追加のレプリカを作成するためのバックグラウンドタスクを開始します。
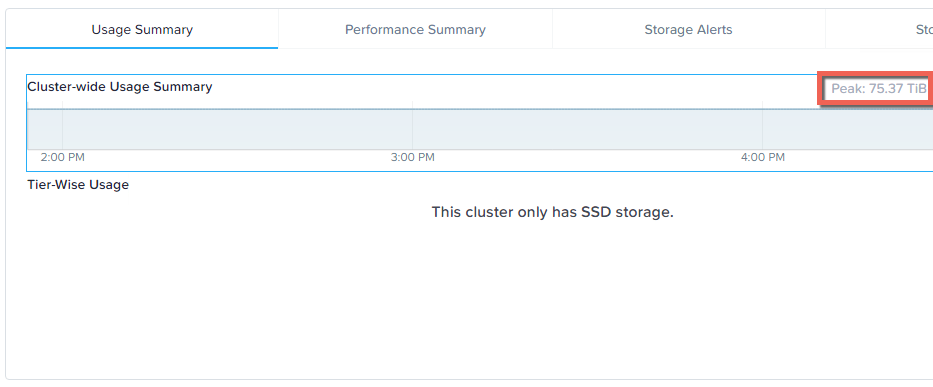
今回のケースでは、ストレージプールに約50TBのデータがある状態でスタートしたので、このタスクでは50%のレプリカを作成する必要があり、最終的には約75TBのデータを格納することになります。
新しいRedundancy Factorに準拠するために、クラスターが25TBのデータを作成するのにかかった時間を見てみましょう。
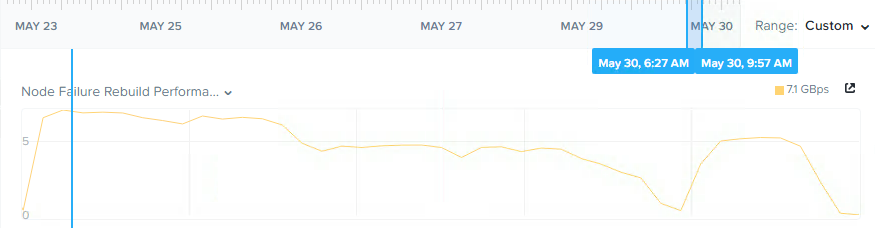
今回は、7GBps以上のスループットで3時間未満の処理時間を示しており、1時間あたり約8.3TBとなりました。このプロセス全体を通して、クラスターはRF2レベルの完全な回復力を維持しつつ、このフェーズで新しい書き込みが行われた際には、すべてRF3で保護されていたことに注目してください。
下の図は、ストレージプールの使用量が運用中にリニアに増加していることを示しています。
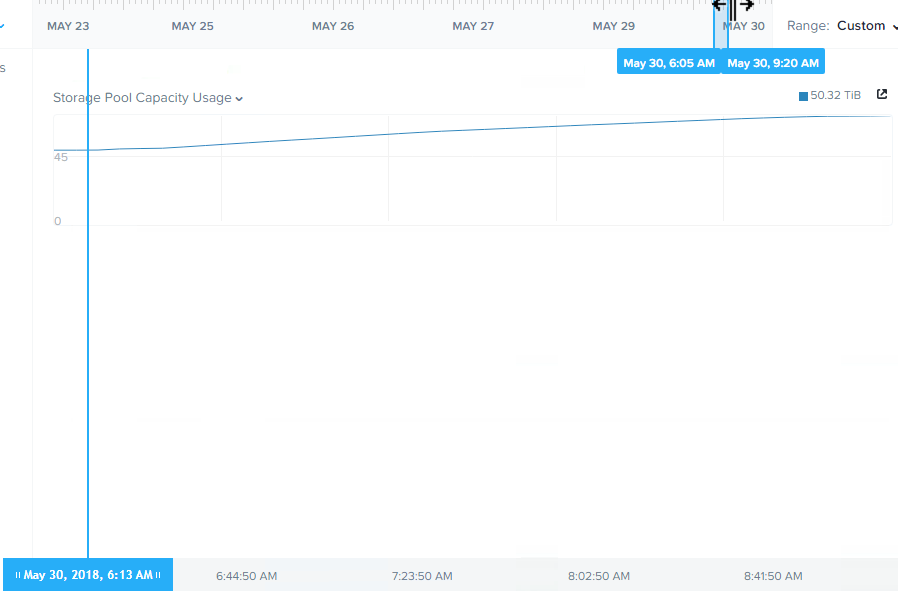
ADSFは本当の意味での分散型ストレージであり、ノード数が多ければ多いほど、すべての書き込みアクティビティに参加するコントローラの数が増えるため、クラスターの規模が大きければ、このタスクはより速く実行されるであろう、という点は重要です。ノードを追加することの利点については、Scale out performance testing with Nutanix Storage Only Nodesをご覧ください。
処理が完了すると、ストレージプールの使用量が期待通りに75TBになっていることがわかります。
Nutanix ADSFがどのくらい物理ドライブを制御できるかに興味がある方のために、冗長性準拠の処理中におけるいくつかの統計情報を取得してみました。
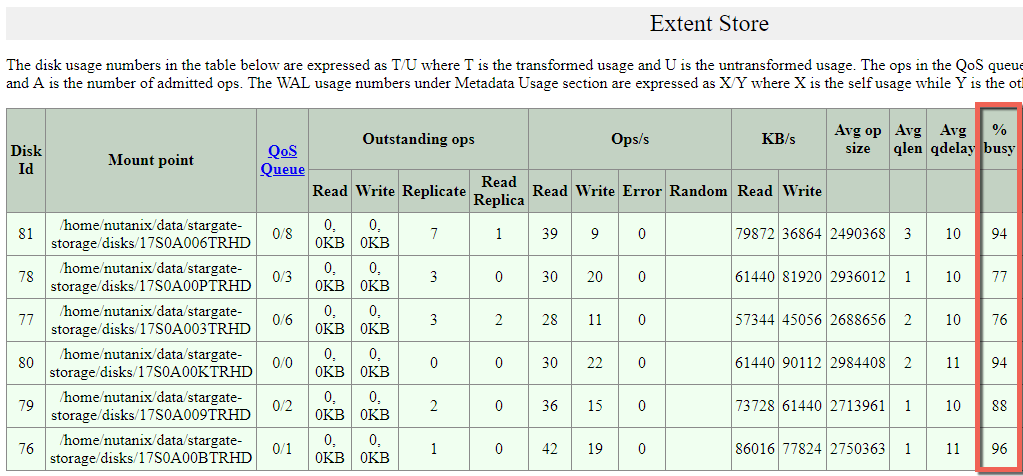
強調表示している部分が意味するのは、物理ドライブが最大またはそれに近い状態で駆動していること、また、読み込みと書き込みのI/Oがすべてのドライブに渡って処理されていることです。インテリジェントでないHCIプラットフォームのように、1台のキャッシュドライブで負荷を処理し、その後で容量ドライブにデータを送る、というような仕組みではありません。
概要
- Nutanix ADSFは、冗長化レベル(RF2とRF3)を稼働状態のまま直接変更することができます。
- 25TB以上のデータを作成する冗長性準拠のための処理を3時間以内に完了できました(しかも5年前の機器で)。
- 冗長性準拠のためのタスク全体を通して、リニアにパフォーマンスを発揮します。
- Nutanix Controller VM (CVM)1台で、6台の物理SSDを最大限に近い状態で駆動させることができる。
- ADSFは、すべてのドライブに対して読み書きを行い、キャッシュディスクと容量ディスクを分けた非効率なアーキテクチャを使用しません。