

本記事は2018年6月11日に Josh Odgers 氏が投稿した記事の翻訳版です。
パート1から4をまだ確認していない場合はぜひご確認ください。これらは重要なレジリエンシーファクターの障害からの回復速度に関するもので、その場でRF2からRF3へ、もしくは同じ回復力レベルを提供しながら容量を節約するイレイジャーコーディング(EC-X)へと変換することで、回復力を向上させることについて解説しています。
パート5と6では、CVM のメンテナンスまたは障害時に読み取りと書き込みI/Oがどのように機能するか解説し、このシリーズのパート 7 では、ハイパーバイザー (ESXi、Hyper-V、XenServer、AHV) のアップグレードが読み取りと書き込み I/O にどのような影響を与えるかについて説明します。
この投稿ではパート5と6を頻繁に参照するので、このブログを完全に理解するには前の投稿をよく読んでください。
パート5とパート6で説明したように、CVM の状況に関係なく、読み取りおよび書き込み I/O は引き続き提供され、データは設定されたレジリエンシーファクターに準拠したままです。
ハイパーバイザーをアップグレードした場合、仮想マシンはまずノードから移行し、通常通りIO操作を続行します。ハイパーバイザーに障害が発生した場合、仮想マシンは HA によって再起動され、通常のIO操作を再開します。
ハイパーバイザー (またはノード) の障害またはハイパーバイザーのアップグレードのいずれの場合でも、最終的にはいずれのシナリオにおいても、仮想マシンを新しいノードで実行し、元のノード (下の図のノード 1) がオフラインになり、ローカルドライブ上のデータが一定の期間利用できなくなります。
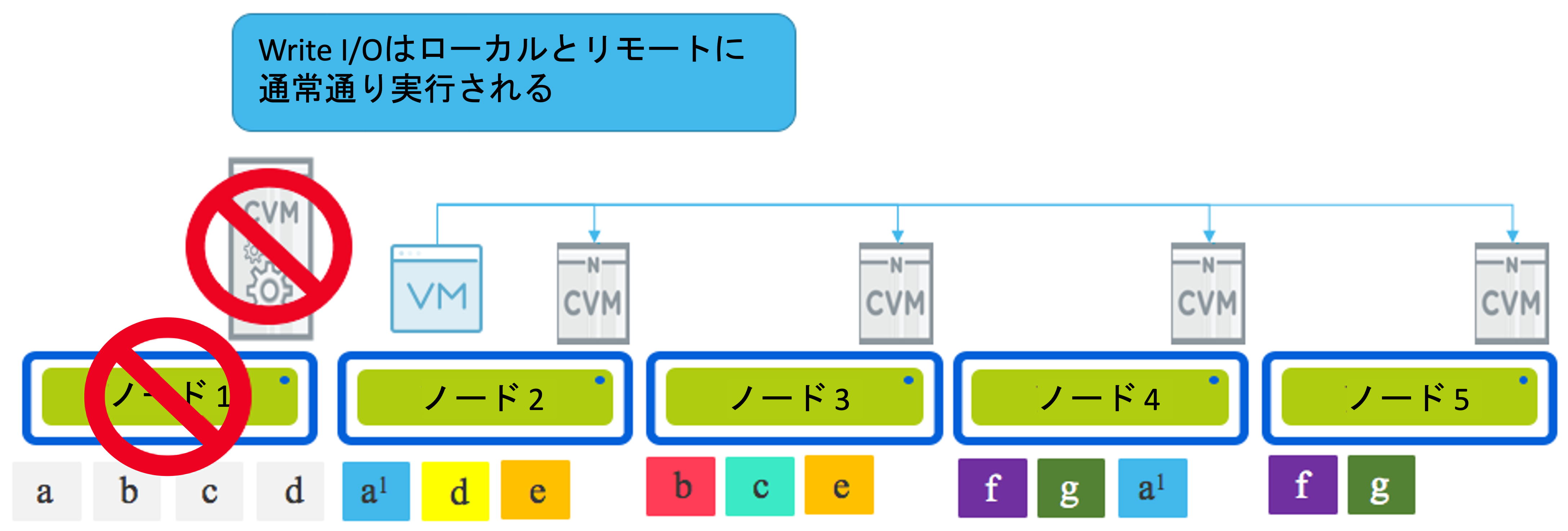
このシナリオでは、読み取り I/O はどのように機能しますか? パート5での説明と同じ方法で読み取りはリモートで処理されます。または、2 番目のレプリカが仮想マシンが移行された (または HA によって再始動された) ノード上に存在する場合、読み取りはローカルで行われます。リモートでの読み取りが発生した際に、1MB のエクステントはローカライズされ、その後の読み取りはローカルで実行されるようになります。
書き込みI/Oはどうですか? パート6と同様に、すべての書き込みは設定されたレジリエンシーファクターに常に準拠します、ハイパーバイザーのアップグレードまたは CVM、ハイパーバイザ、ノード、ネットワーク、ディスク、SSD の障害に関係なく、1 つのレプリカはローカル ノードに書き込まれ、その後の 1 つまたは 2 つのレプリカがクラスター全体に分散されます。
この仕組みは本当にシンプルであり、このレベルの回復力は、アクロポリス分散ストレージファブリック(ADSF)によって実現されます。
まとめ:
- ハイパーバイザーの障害が ADSF の書き込みパスに影響を与えることはありません
- ハイパーバイザー(ノード)障害が発生しても、データ整合性は常に維持されます
- ハイパーバイザーのアップグレードは、読み取り/書き込みパスを停止させることなく完了します
- 読み取りは、アップグレード、メンテナンス、障害に関係なく、ローカルまたはリモートで継続して行われます
- ハイパーバイザーの障害時には、書き込みに対するデータローカリティを維持して、アップグレード/障害シナリオで最適な読み取り/書き込みパフォーマンスを実現するため、VM が存在する場所に常に1 つのコピーをローカルに保持します