

2018年6月8日にJosh Odgers氏が投稿した記事の翻訳版です。
これまでのシリーズでは、ADSFがクラスタ全体にデータを分散することで、ノード障害から迅速に回復する方法について説明してきました(パート1)。また、耐障害性をRF2(Resiliency Factor 2)からRF3へ変換した場合や(パート2)、よりスペース効率の高いEC-X(Erasure Coding)構成へ変換する場合でも(パート4)、影響がないことを説明しました。
ここでは、AOSのアップグレードなどのNutanix Controller VM (CVM)のメンテナンス時や、CVMのクラッシュや誤ってまたは悪意を持って電源を切ってしまった場合などの障害時に、VMがどのような影響を受けるかという非常に重要なトピックを取り上げます。
早速ですが、Nutanix ADSFがどのようにデータを書き込み、保護するのか、その基本を説明します。
下図は、3ノードでクラスタで、1台の仮想マシンが稼働している構成です。仮想マシンはa,b,c,dのデータを書き込んでいます。通常、すべての書き込みは、1つのレプリカが仮想マシンを実行しているホスト(ここではノード1)に書き込まれ、もう1つのレプリカ(RF3の場合は1つまたは複数)がディスク配置の選択優先順位に基づいてクラスタ全体に分散配置されます。ディスク配置の選択優先順位(私は「インテリジェント・レプリカ・プレースメント(Intelligent replica placement)」と呼んでいます)は、データが最初から最適な場所に置かれることを保証します。
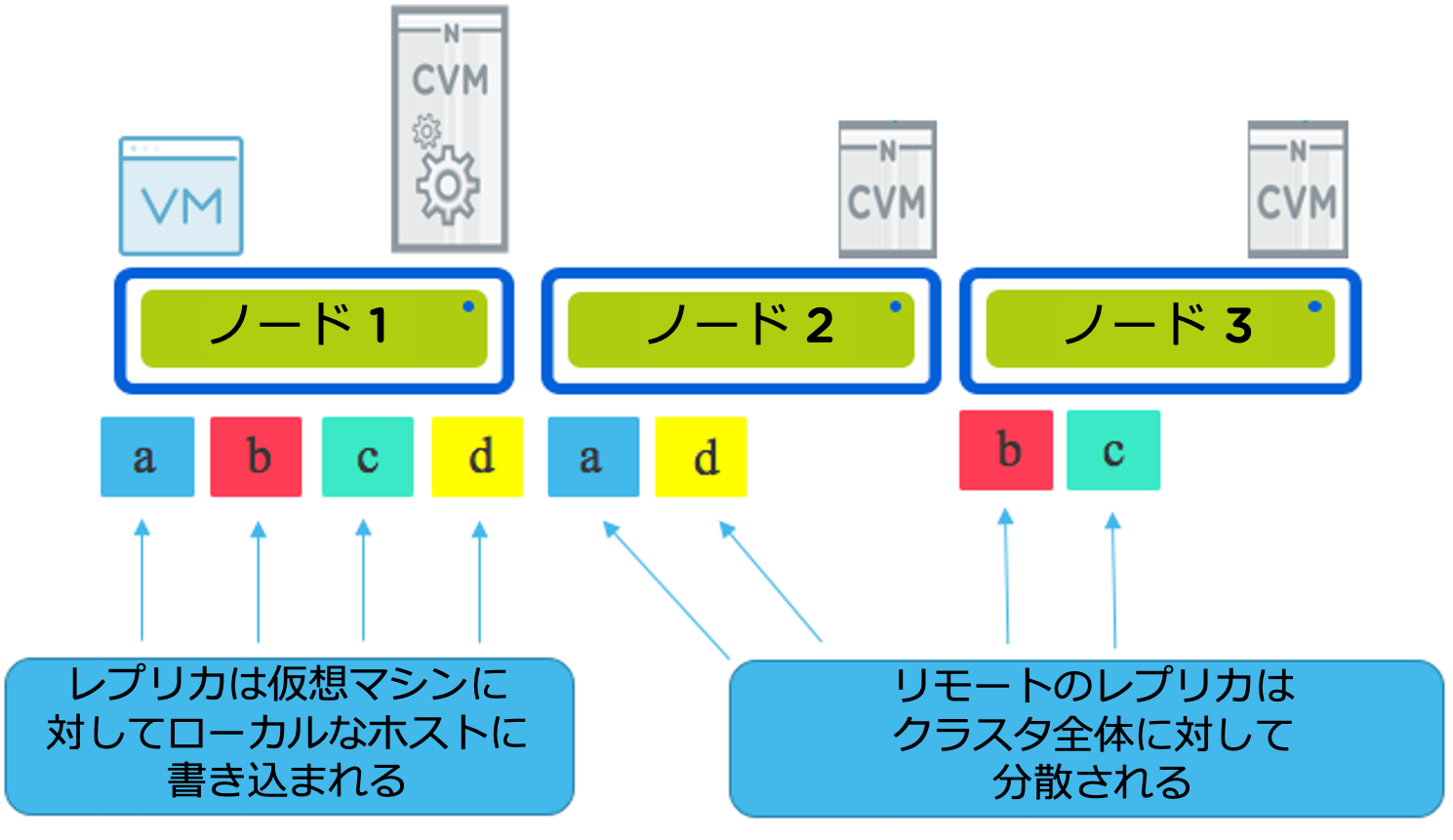
クラスタに1つ以上のノードが追加された場合、インテリジェント・レプリカ・プレースメントは、新たな書き込みが発生しなかった場合でも、クラスタがバランスのとれた状態になるまで、それらのノードに比例してより多くのレプリカを送信します。
ADSFは低い優先度のバックグラウンド処理でディスクバランスを行います。
Nutanixがどのように複数のレプリカを使用してデータ保護を行っているか(「Resiliency Factor」と呼ばれる)の基本がわかったところで、Nutanix ADSFストレージ層のアップグレード時にどのようなことが起こるかを確認します。
アップグレードは、“1-Click“で開始されます。設定されている回復力(RF)やEC-Xの使用にかかわらず、一度に1つのController VM(CVM)に対してローリング・アップグレードを行います。ローリング・アップグレードでは、一度に1つのCVMをオフラインにしてアップグレードを実行し、セルフチェックを行った後、クラスタに復帰させ、次のCVMをアップグレードするプロセスを繰り返します。
Nutanixがストレージをハイパーバイザーから切り離す(カーネルにストレージを組み込まない)ことの多くの利点の1つは、ここで紹介している、アップグレードやストレージ層の障害でも、稼働中の仮想マシンに影響を与えないことになります。
VMの再起動(HAイベントのようなもの)や他のノードへの移行(vMotionなど)も必要ありません。ローカルコントローラ(CVM)がどんな理由でオフラインになった場合でも、VMはストレージトラフィックを中断することなく継続されます。
ローカルのCVMがメンテナンスや故障で停止した場合、VMのI/Oはクラスタ全体で動的にリダイレクトされます。
CVMが(何らかの理由で)オフラインになったときのRead I/Oを見てみましょう。
CVMがオフラインになるということは、物理ドライブ(NVMe、SSD、HDDなど)が利用できないことを意味し、ローカルデータ(レプリカ)が利用できないことを意味します。
すべてのRead I/Oはリダイレクトされ、クラスタ内のすべてのCVMによって提供されるようになるため、ストレージトラフィックを中断することなく継続されます。
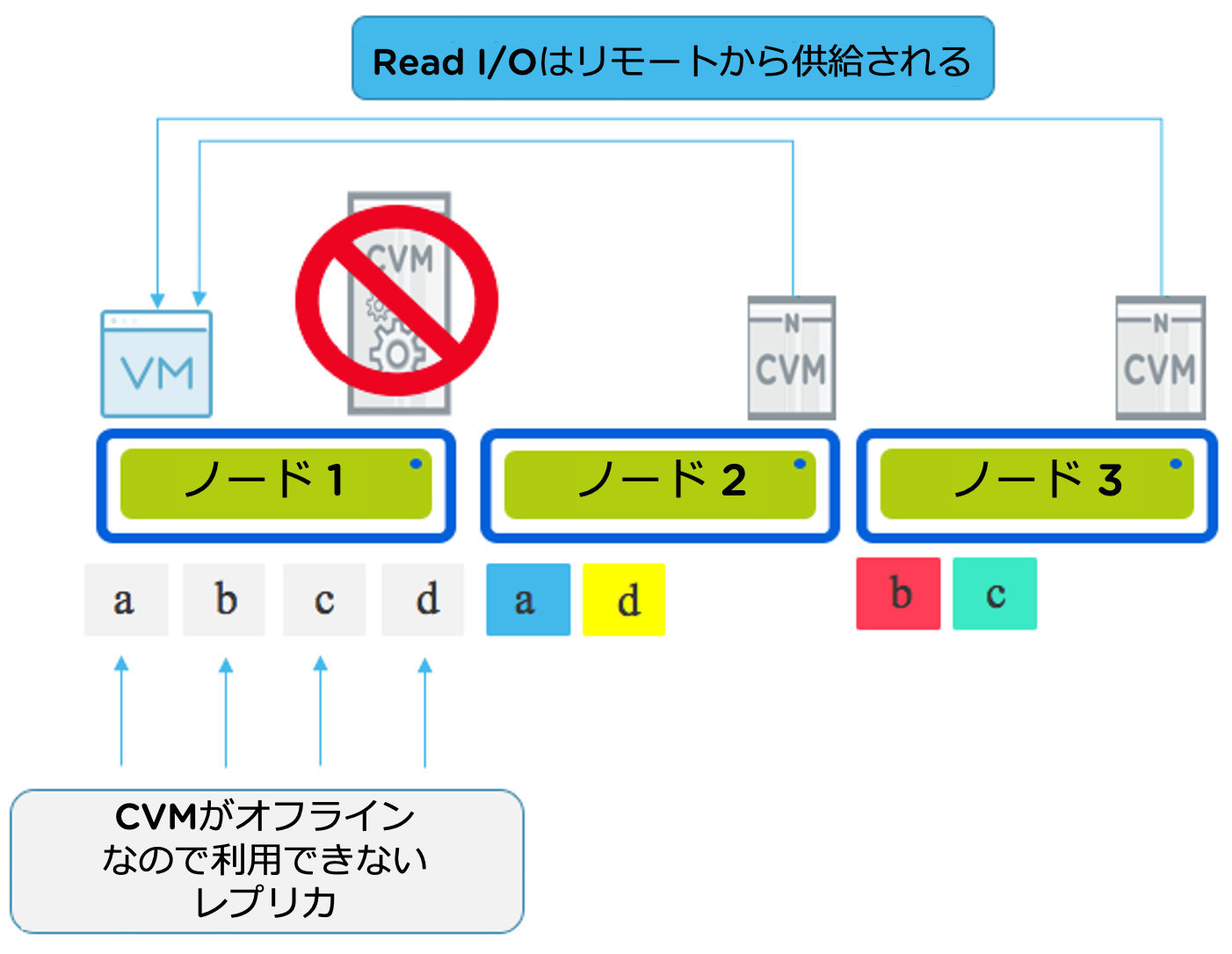
このメンテナンス/障害シナリオは、VMを実行しているノードが現在ストレージを提供しておらず、ネットワーク経由でストレージに接続しているという点で、3階層アーキテクチャと比較することができます。
しかし、Nutanixは分散型アーキテクチャであるため、クラスタ内のすべてのノードが読み取りを行います。つまり、3ノードクラスタでの障害やメンテナンス時でさえも、最適時のデュアルコントローラの3階層アーキテクチャと同等になります
例えば、Nutanixクラスタが8ノードで構成されていて、1ノードがメンテナンスを行っていたり、CVMが何らかの理由でダウンしていた場合、7ノードがそのノード上のVMにIOを提供することになります。この処理は実は新しいものではなく、Nutanixが長い間行ってきたものです。
2015年7月に公開した「Acropolis Hypervisor (AHV) I/O Failover & Load Balancing」で詳しく説明しています。
CVMがオンラインに戻ると、Read I/Oは再びローカルCVMによって処理されます。唯一のリモートへのRead I/Oは、データがローカルノード上に存在しない場合になります。リモートへのリードが発生すると、1MBのエクステントがローカライズされ、その後の読みこみはローカルから読み込まれます。
エクステント(レプリカ)データをローカライズするプロセスは、リモート・リードと比較してネットワーク上に追加のオーバーヘッドを発生させないため、ローカルライズすることで追加のオーバーヘッドなしにパフォーマンスを向上させることができます。
サマリ:
- ADSFは、VM が存在するノードにデータを書き込み、その後の読み取りがローカルであることを保証します。
- Read I/OはローカルCVMによって処理され、ローカルCVMが何らかの理由で利用できない場合、Read I/Oはクラスタ内のすべてのCVMによって分散して処理されます
- ローカルCVMがメンテナンスや故障でオフラインになっても、仮想マシンのフェイルオーバや、ノードからマイグレーションする必要はありません。
- 3ノードのクラスタでCVMがダウンするという最悪のシナリオでも、Nutanix上で動作する仮想マシンは少なくとも2つのストレージコントローラでトラフィックを処理します。これはサーバー+デュアルコントローラストレージアレイ(3層)アーキテクチャのベストシナリオと同等です
- 3ノード以上のクラスターでは、Nutanix上の仮想マシンは、サーバー+デュアルコントローラーストレージアレイ(3階層)アーキテクチャの最適なシナリオよりも多くのストレージコントローラーでリードI/Oを処理します。