

本記事はNutanixのSenior Technical Marketing EngineerのBhavik Desaiが2022年8月10日に投稿した記事の翻訳版です。
原文はこちら。

このブログシリーズはAOSのユニークな分散型ストレージアーキテクチャについて説明し、Nutanixのエンジニアがレジリエンシーと低遅延のパフォーマンスのために、スケールアウトクラスタ全体に動的に分散されるデータに対してどのように難しいアプローチを取ったのかということを取り上げていきます。
さて、今回は2つ目の記事です。AOSが仮想マシンのvDiskデータをどのようにして、extent groupと呼ばれる4MBのちょうどよいサイズのチャンクに分割しているのかについて、掘り下げていきたいと思います。 このアプローチは保存の効率が悪く、保護を行うためにネットワーク帯域を多く消費し、リビルドに時間のかかる静的な巨大なブロックを用いるアプローチに比べ遥かに洗練されたアプローチです。AOS内のextentは分散されたメタデータストアによって実現されています。分散メタデータストアはクラウドアーキテクトにとっては最適な状態においても障害発生時においても一貫性を保ち、効率的に分散されたデータを取り扱う方法として知られています。特に障害発生時の動きはストレージアーキテクトにとって興味を引く内容でしょう。
分散された拡張性のあるメタデータ
先の記事でご紹介したとおり、AOSのインテリジェンスはコントローラー仮想マシン(CVM)に格納されたサービスとしてクラスタ全体に分割され広がっています。AOS内のメタデータはグローバルとローカルのメタデータストアに分類できます。グローバルメタデータストアは論理的な、どのノードがデータを保持しているかと言うようなメタデータで、一方ローカルメタデータは物理的に実際にどのディスクのどの領域にデータが保存されているかというようなメタデータです。これによって柔軟かつ最適にメタデータを更新することができます。
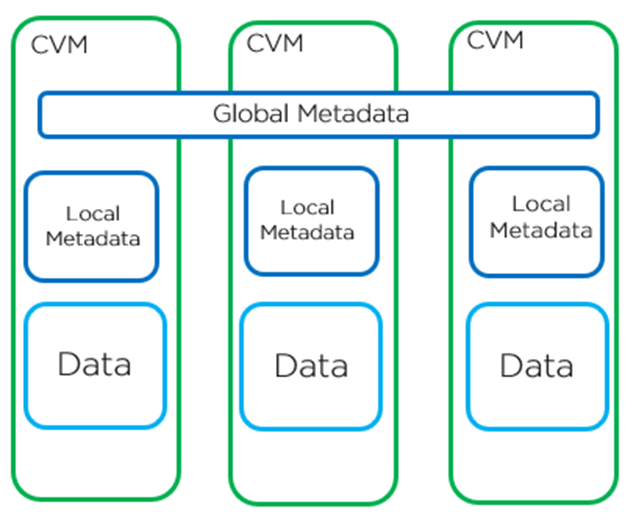
グローバルメタデータストアはかなり大規模に手を入れたApache Cassandraをベースとした分散ストアで、Paxosアルゴリズムを使って厳格に一貫性を担保しています。メタデータはリング状に分散して保存され、冗長性が提供されます。ローカルメタデータストアは物理的なメタデータはローカルの物理ノードの物理的なメタデータをRocksDBをベースとした自律エクステントストア(Autonomous Extent Store - AES)データベース内に保持します。どのようなメタデータがどこにどのように保存されているかについてのさらなる詳細についてはNutanixバイブルで確認することができます。
動的なアプリケーションを意識したデータ管理
分散メタデータストアによってAOSはvdiskをストレージにとって程よいサイズのデータのかけらとして分割することができ、動的で自動化されたデータ配置と管理が行えるようになっています。Nutanixはレプリケーションファクタ(RF)に応じてクラスタ内の 2 または 3 箇所にデータを書き込みます。アプリケーションがデータを書き込む際に、AOSは毎回動的にどこにデータのコピーを配置するのか選択します。データのコピーのうちの一つは常にアプリケーションが動作しているノードへと配置されます。AOSは他のコピーについてはインテリジェントにクラスタの可用性ドメインに応じて配置を行います。もしもクラスタが標準のノードを意識したドメインを利用している場合、異なるノードが選択されます。もしもクラスタがブロックもしくはラックを意識した構成になっている場合、異なるブロックもしくはラック内のノードが選択されます。新たな書き込みの2つ目と3つ目のデータのコピーでは同一ノードやブロック、ラックが選択されることはありません。AOSはデータのコピーを均等にクラスタ全体に分散させ、クラスタのバランスを保ちます。(ローカルとリモートの両方の)どのディスクにデータコピーが配置されるかの選択についても、ディスクの選択は利用状況、応答時間、キュー深度をベースとしたディスクのフィットネススコアを計算するインテリジェントなアルゴリズムを用いて行われます。
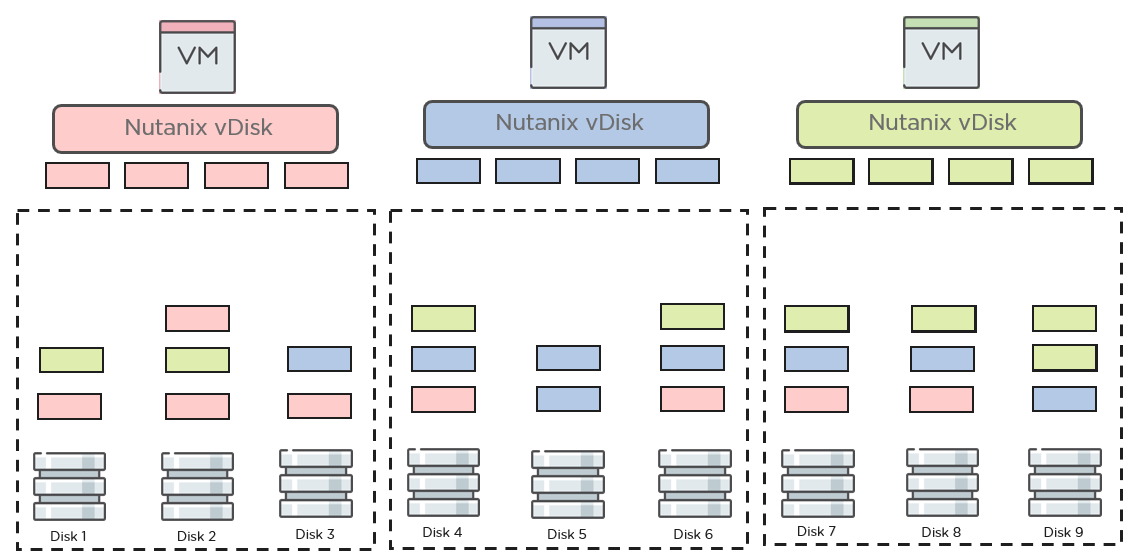
ちょうどよいサイズのアプリケーションを意識したデータストレージはAOSがクラスタ上のデータの管理を自動化することと、瞬時に障害から回復をすることを容易にしています。例えば、クラスタ内のノードをメンテナンスする場合、そのノードで稼働している仮想マシンは別のノードへと移動されます。これらの仮想マシン内のアプリケーションによってリクエストされたデータが仮想マシンが移動したノードにとってローカルではない場合で、そのデータに対するリクエストが複数回あった場合、AOSはそのリクエストされたデータを自動的にそのノードへと移動させます。もしもクラスタ内でノードやディスク、またはCVMが応答しなくなるなどの障害があった場合、AOSは分散されたメタデータストアのおかげですぐにそして容易にどのデータのコピーがもはや利用できなくなったのかを確定し、即座にリビルドのプロセスを開始します。こうしたリカバリデータコピーの作成や配置も自動的、動的、そして自律的に行われます。プロセスが即座に開始されるだけでなく、障害とその復旧の最中も、新たに行われる書き込みや既存のデータの上書きはRFポリシーに従って確実に保護され、アプリケーションの高いレジリエンシーを保証しています。
データの分散と管理のため:
- AOSはそれぞれのデータのコピーの配置先の決定を自律的に行います。
- コピーのうちの一つは常にアプリケーションが稼働しているノード内に保持されます。
- 他のコピーはアルゴリズムとクラスタの可用性ドメインの構成に基づいてクラスタ全体に均等に分散されます。
- 仮想マシンが移動した場合、リクエストされたデータがローカルで保持されることを保証するため、データはAOSによって自動的にノード間と階層間を移動します。
- 障害時、データコピーのリビルトは即座に行われ、データの可用性を保証します。
なぜこれが重要なのか?
AOSは一貫した想定通りのアプリケーションとそれらが利用するデータのパフォーマンスを事前の設計上の推定や予測をする必要をなく保証します。AOSはアプリケーションがデータを生成し、それにアクセスするのに応じて柔軟かつ動的な判断を行い、パフォーマンスとディスク利用に関してより優れた一貫性を保証します。AOSはデータをアプリケーションにとってローカルとなるノードに維持し、ネットワークへの飛び火を取り除くため、アプリケーションは常に一貫して高速なパフォーマンスを得ることができます。
データのコピーが失われた場合はAOSが適切なメタデータと分散されたデータ配置を活用して即座にリビルドを行います。プロセスがすぐに開始だけでなく、予めインテリジェントな選択を行って、複数のノードとディスクに動的にデータを分散させてあるため、複数のノードとディスクがリビルドに参加することができ、リビルドは非常に高速です。リカバリプロセスは実際にクラスタのサイズが大きくなるにつれてより高速になっていきます。システム内で特定のノードやディスクがリカバリのプロセス内で負荷が圧倒されてしまい、アプリケーションへパフォーマンス上の影響が出るというようなボトルネックも存在しません。AOSはデータのリカバリのスピードを最適化しながら、データが可能な限り高い可用性を持つように保証し、アプリケーションのパフォーマンスを早く最適な状態へ戻します。
このNutanixの設計は非常に実装が難しいものですが、アプリケーション観点での最適化、アプリケーションが展開されてからのライフサイクル全体を通した一貫した性能の保証、データの可用性、そしてレジリエンシー全般を提供しています。
次の記事では、このユニークな適切なデータ分散を実現する分散されたアーキテクチャがマニュアルでの介入なくクラスタのパフォーマンスとキャパシティの管理をシームレスに実現している点について見ていきます。
このシリーズのパート1はこちら: Nutanixのメリット その 1: 動的に分散されたストレージ。