Hi,
I successfully deployed three nodes as VMs in my VMware nested environment without any issues. All are pinging each other. CVMs are also pingable from each other.
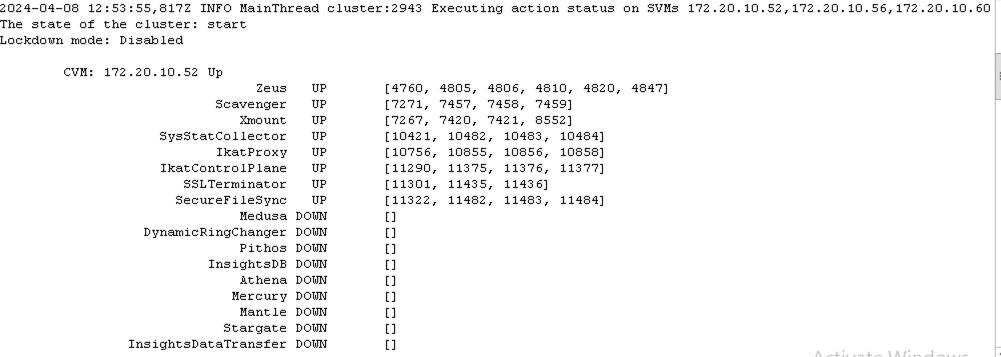
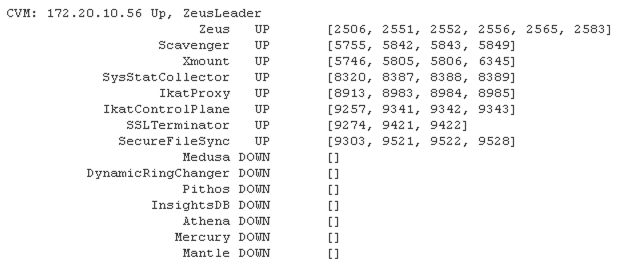
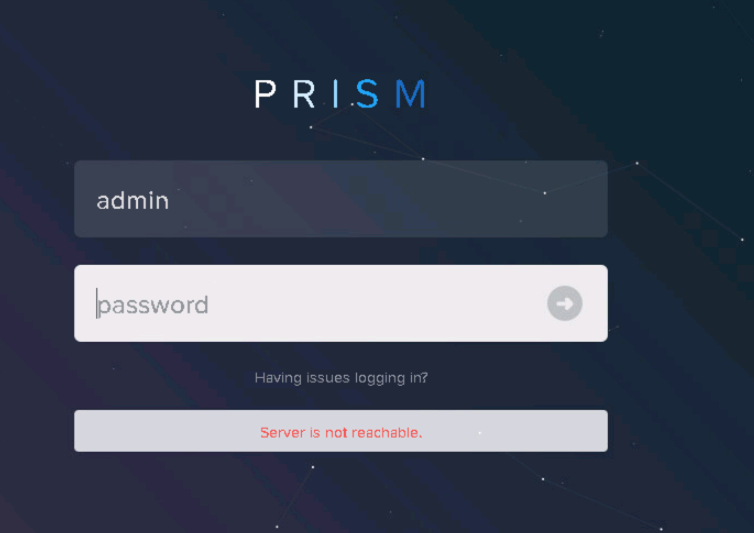
But when I create cluster from a CVM, cluster creation failed, medusa and its below listed services are having DOWN status.
Please help.
Regards,
Gurdeep Sandhu