


What is happening to my 2 node cluster during a failover or an upgrade?
What does a recovery process look like after a node failure?
If you are wondering the above, we have the answer for you!
You can monitor the progress of your 2 node cluster in these situations through Prism Element.
To monitor node recovery progress after failover:
Registering a witness is highly recommended to help the cluster handle the failover situation automatically and gracefully.
-
Stand-Alone mode: A failed node would trigger cluster to transition into stand-alone mode during which the following occurs:
-
Failed node is detached from metadata ring.
-
Auto rebuild is in progress.
-
Surviving node continues to serve the data.
-
Heartbeat: Surviving node continuously pings its peer. As soon as it gets a successful reply from its peer, clock starts to ensure that the pings are continuous for the next 15 minutes. If a ping fails after a successful ping, the timer will be reset.
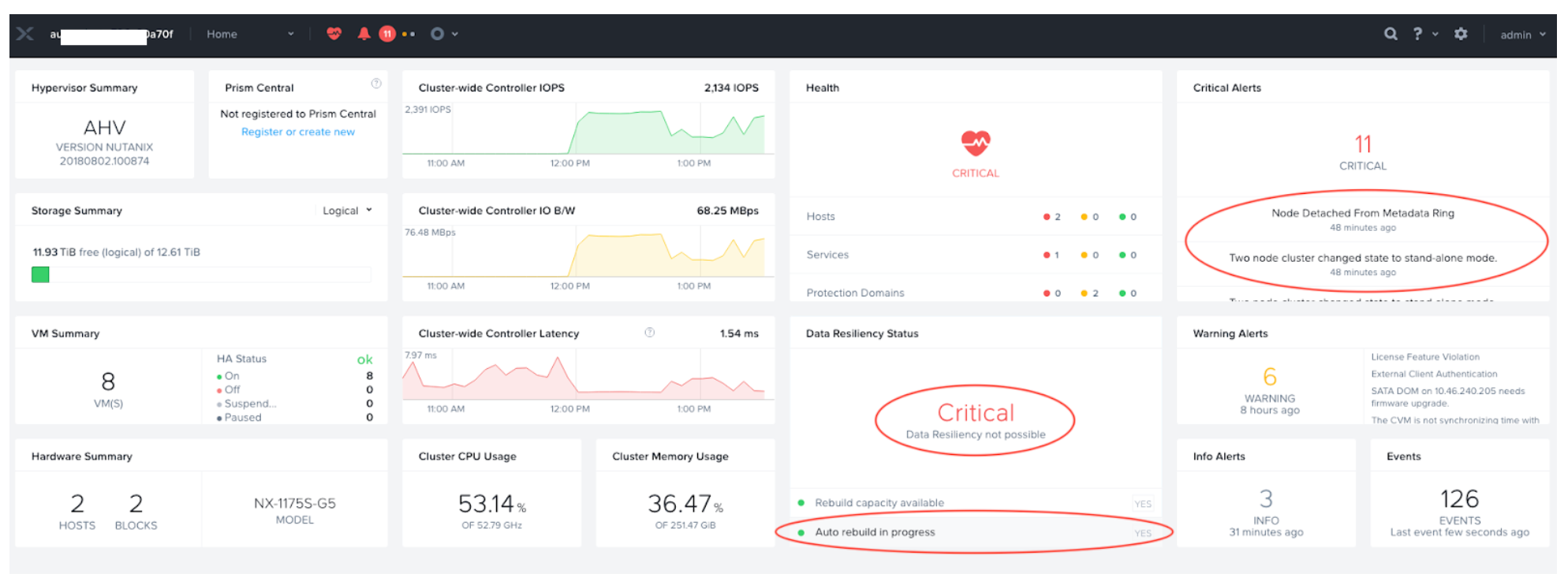
Prism Element Home page shows Critical Data Resiliency Status and corresponding alerts.
The critical alert shows the following messages:
-
"Two node cluster change state to stand-alone mode"
-
"Node Detached From Metadata Ring"
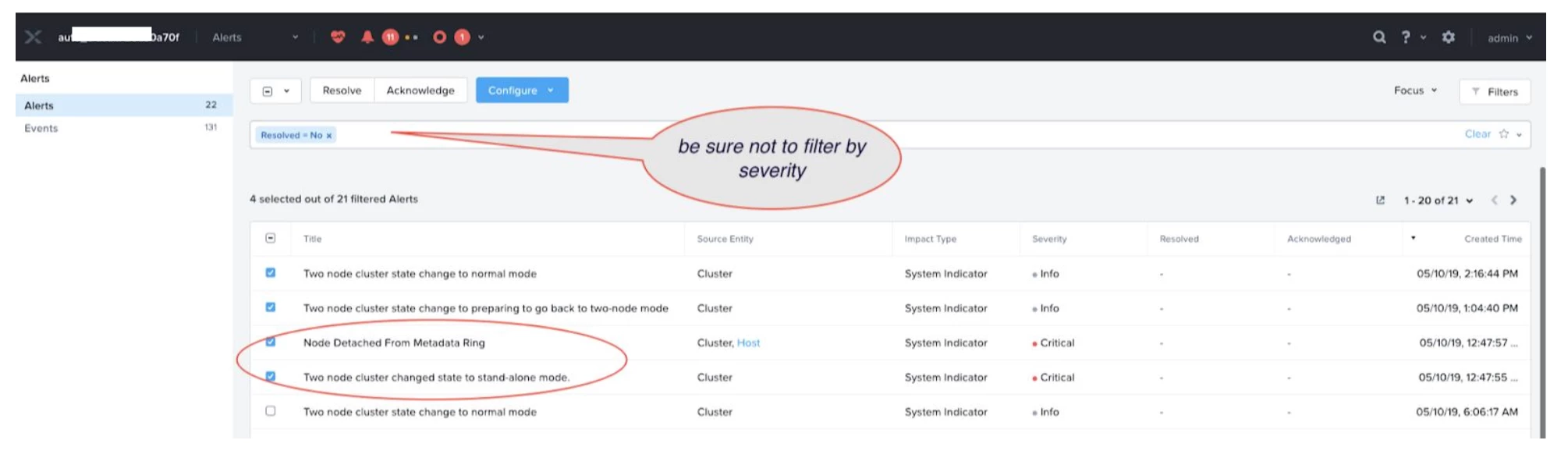
Alerts page shows stand-alone mode.
-
Preparing to go back to Two-Node Mode:
During stand alone mode, once ping is continuous for a 15-minute timer described above, the cluster will be transitioned to a stage called “Preparing to go back to two-node mode.”
Alert page shows an entry with the following description:
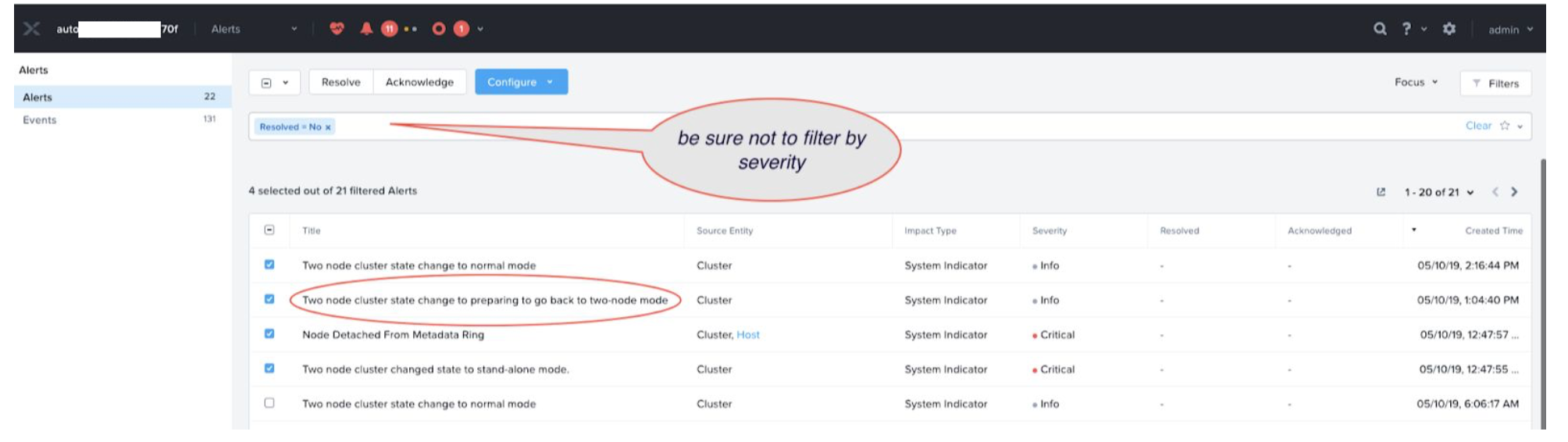
In this mode, be sure to refrain from performing any disruptive event on the leader node as cluster resiliency status is still critical.
During this time, the following occurs:
-
Both nodes are part of the cluster.
-
Both nodes serve data and no disruptive events to be done on the leader node
-
Cassandra will make sure that metadata on both nodes is in synchronization. The duration of this mode is depending on the delta of metadata generated while the peer was previously down.
-
Duration of this mode also depending on the time it takes to scan for the discrepancies of the data when both nodes serving data after a peer was previously down.
- Normal Mode
The process to reach this mode could be hours depending on how much data discrepancies between two nodes during the failure and recovery duration. After the cluster determines that both of the nodes are in synchronization, cluster transitions to “Normal Mode.”
Alert message shows the following information:
“Two node cluster state change to normal mode”
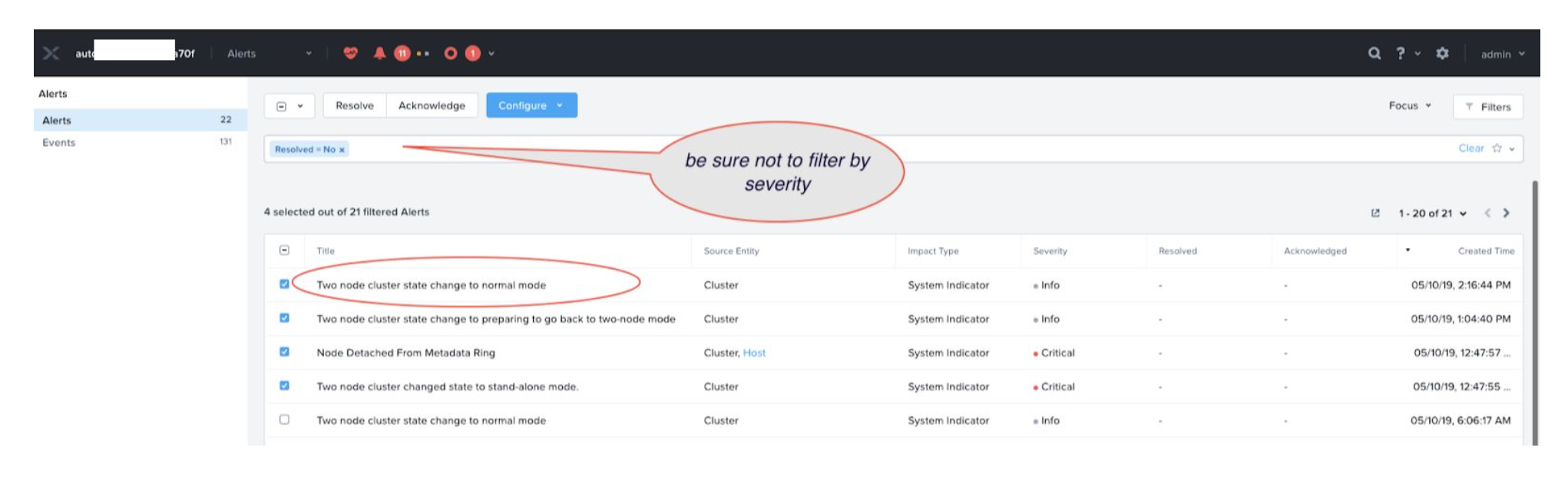
When the cluster reaches this mode, the cluster can tolerate a failure. Cluster home page should show Resiliency status as “OK.”
KB for reference:
https://portal.nutanix.com/page/documents/kbs/details?targetId=kA00e0000009DclCAE