


Nutanix was founded with a bold vision: to make managing IT infrastructure so simple that it becomes invisible. We made compute, storage, virtualization, and clouds invisible—a technology stack that practically runs itself. Now, we’re making the support needed to operate such a complex stack invisible too.
While Nutanix continues to deliver products that are simple and easy to use, underneath, the complexity and availability of ecosystem options for the technology stack has continued to increase.
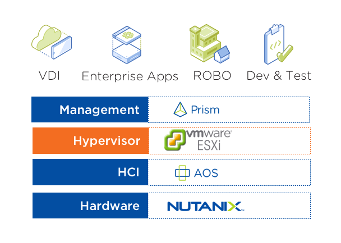
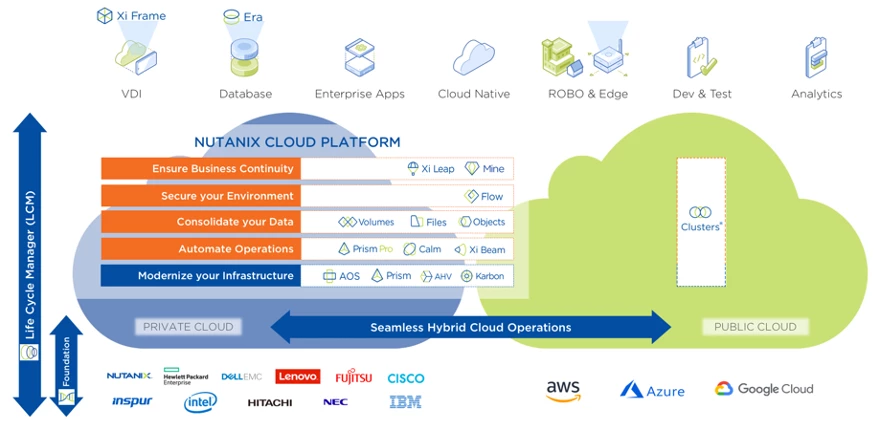
The disruptive Hyperconverged Infrastructure (HCI) solution that Nutanix pioneered a decade ago originally consisted of Nutanix NX nodes, AOS software, the ESXi hypervisor, and Prism management software. Over time additional infrastructure layers have been added, providing an end-to-end environment for hybrid cloud and multicloud solutions.
Nutanix has consistently provided world-leading Support with a 90+ Net Promoter Score on average for the last 6 years in row, in spite of our growing portfolio of software products, an increase in the number of supported OEM, and third-party platforms, and a mature ecosystem of supporting technologies. A 96% customer satisfaction score gives us confidence that these numbers will continue to increase in the coming years.
Far from resting on its laurels, Nutanix Support has continued to invest in improving its practice. This not only includes scaling and structuring the support organization for improvement, but also the investment in new tools. These tools are automation and most recently leveraging the wealth of “call home” telemetry data to advance the proactive nature of the customer-Support relationship.
A dedicated team of R&D engineers at Nutanix has put a lot of effort into technological innovations for the Support organization, with the aim of making the support invisible to the customers. These solutions aim to:
- Avoid customer infrastructure issues
- Proactively detect issues by leveraging customer telemetry data
- Fast diagnostics of any issues detected, with customer-actionable resolutions
Even though the above mentioned practices are relatively new, this concept has been imbued on day zero into the SaaS product development culture under the umbrella of “Observability.”
Nutanix has always acknowledged and adopted the benefits of the SaaS world. Some examples of this include the Nutanix move to a software-subscription finance model, nimble non-disruptive upgrades, zero-touch IT infrastructure deployments, and more. On the Support side, we acknowledge the stability, responsiveness, and ease of maintenance SaaS services provide, and have brought the same delight to our customers by implementing observability for Nutanix hybrid and multicloud solutions.
As a part of implementing observability culture within Nutanix, we are practicing the Observability-Driven Development (ODD) among engineers and PMs. Tracking business KPIs for products and features helps enable us to make informed business decisions, understanding the impact and scope of the incidents. We have written tools to make it easy and efficient for instrumenting code, data cleansing, and enrichment. An implemented data lake or warehouse is used to store telemetry data, which is consumed for dashboards and reports by deployed solutions.
We have custom data discovery and policy engines that can detect any anomalies, non-standard configuration, or best practices violations based on telemetry data. For observability dependencies like log or trace collection where there are physical limitations due to the sheer volume of data generated and data transfer latencies involved between customer datacenters and ours, we use intelligent edge services to process logs and traces and perform hundreds of other checks on the cluster itself, only reporting it periodically or conditionally.
All this has enabled us to:
Avoid issues
Implement data-driven design decisions: Developers/PM write software/PRDs backed by complete data and move away from decisions based on intuition or sample and subset of data obtained via customer surveys. They query data to validate or invalidate design hypotheses.
Provide continuous system behavior monitoring: The writers themselves monitor the systems and observe for unexpected behavior or anomalies. They spend time on understanding the production behavior. This experience makes them fluent in debugging on production so that when an issue emerges, they are able to quickly resolve it.
Resource utilization and capacity forecasting: Forecasting is performed on both, the resources consumed by Nutanix services and also for the resources consumed by customers. This prevents surprises that often come with a new release or over a period of time.
Accurate QA scoping: Using telemetry data, we are able to mimic all the production scenarios accurately and avoid relying on a few falsified dev/test environments.
Efficient Feedback loop: Developers work very closely with Support. They have established a fast and efficient way to share insights and feedback for production systems behavior.
Anomaly detection: By understanding the data patterns over a long period of time, our machine learning algorithms can detect anomalies faster and more accurately, thus taking us closer to complete AIOps future.
Proactively detect issues
Automate KB articles and best practices: We have built a framework that codifies the KB articles and best practices and are executing these rules and policies periodically to detect the unexpected or inefficient configurations and behaviors.
Cross customer analytics: We have jobs running that analyse configuration and workload similarities for clusters and provide alerts and recommendations for optimal behavior.
Fast diagnostics+resolutions to the issues detected and reported
Remote monitoring: We track and analyze the health checks and alerts regularly and take appropriate actions to resolve any issues observed.
Automated metric, log, and traces collector: To avoid the cumbersome process of manually collecting support bundles, we have automated the process of triggering and collecting the necessary information with customers approval.
Notifications via portal and email: We have built a customer-facing portal where one can, for example, get insights related to the cluster, take recommended actions, and configure notifications.
1-click upgrades: All the product improvements and capabilities are pushed in an extremely simple and efficient manner.
Help Nutanix Engineering design, prioritize, and contribute to the future product feature-set with stability, maintenance, and support responsiveness of your clusters in mind.
Remove the burden of reactionary infrastructure support by managing issues invisibly: ENABLE PULSE today!
This post was authored by Sameer Narkhede, Nutanix Staff Engineer.
© 2021 Nutanix, Inc. All rights reserved. Nutanix, the Nutanix logo and all Nutanix product, feature and service names mentioned herein are registered trademarks or trademarks of Nutanix, Inc. in the United States and other countries. Other brand names mentioned herein are for identification purposes only and may be the trademarks of their respective holder(s). This post may contain links to external websites that are not part of Nutanix.com. Nutanix does not control these sites and disclaims all responsibility for the content or accuracy of any external site. Our decision to link to an external site should not be considered an endorsement of any content on such a site. This post may contain express and implied forward-looking statements, which are not historical facts and are instead based on our current expectations, estimates and beliefs. The accuracy of such statements involves risks and uncertainties and depends upon future events, including those that may be beyond our control, and actual results may differ materially and adversely from those anticipated or implied by such statements. Any forward-looking statements included herein speak only as of the date hereof and, except as required by law, we assume no obligation to update or otherwise revise any of such forward-looking statements to reflect subsequent events or circumstances.