


This blog was authored by Anish Jain, Senior Technical Manager, Sujaikumar Jayarao, Director Product Management Business Continuity and Disaster Recovery, Nutanix
The primary motivation behind deploying clustering solutions like Windows Server Failover Cluster (WSFC) or Linux Pacemaker is to ensure uninterrupted business operations for mission-critical applications and services. In highly regulated sectors like finance, banking, health care, etc., this need is further reinforced by evolving compliance frameworks such as the Digital Operations Resilience Act (DORA). Administrators tasked to achieve this outcome understand the complexity of providing high availability across rooms, campuses, or data centers all the while maintaining zero data loss and balancing simplicity with cost efficiency.
A typical strategy involves deploying a dedicated storage subsystem mirrored (“stretched”) across different geographical regions via Fibre Channel or IP networks. However, this approach can be quite expensive and complicated, often requiring specialised infrastructure from multiple vendors, introducing additional layers of expertise, training, and maintenance overheads. Alternatively, replication at the database or application layer may seem appealing, but it is often not a feasible option as it introduces additional development/testing costs, license costs, and project delays that are difficult to justify.
The ideal solution should combine the durability of data across data centers and the high availability guarantees of a clustering solution - without the complexity of managing separate infrastructures or rearchitecting applications. It would ensure zero data loss (0 RPO) and deliver a near-zero downtime (~0 RTO) all while optimizing costs. Deployment and Management should be simple and automated, freeing admins from the obligation of constant uptime monitoring. By leveraging hyper-converged infrastructure (HCI), IT teams can implement a solution that could reduce capital expenses while improving operations and lifecycle management
The newly introduced Nutanix Metro Availability for Volume Groups is purpose-built to help IT teams pursue these ideal requirements. Available starting with the AOS 6.8 release, this solution delivers high availability for cross-clustered applications or database workloads, such as Microsoft SQL Server (MSSQL) Failover Cluster Instance (FCI)
The following section provides a detailed description of the solution and how it addresses the requirements discussed above.
Nutanix Metro Availability (MA) for Volume Groups (VGs)
The Nutanix Volumes Block Storage solution is an enterprise-grade, software-defined storage solution that delivers block storage to workloads running on both bare metal and virtualised environments. It operates as a collection of virtual disks distributed across the nodes of a cluster, which can be managed as a “Volume Group” (VG). Designed for high availability within a cluster, Nutanix Volumes Block Storage also supports shared storage use-cases like WSFC and MSSQL. While this helps provide high availability within a single cluster or data center, the resilience of applications against cluster failures remains a challenge.
Metro Availability addresses this limitation by synchronously replicating the VG’s data and configuration across Nutanix clusters, which may be located in different geographical locations, for a zero Recovery Point Objective (RPO) in the event of a site failure. This coupled with the presence of a tie-breaker (i.e., the Nutanix Witness Service solution) in a separate fault domain enables automatic and seamless failovers for applications during network or entire data center outages achieving near-zero Recovery Time Objective (RTO).
Feature Set
Metro Availability for VGs offers the following features:
Synchronous Replication – When data is written to any disk, it is synchronously written across both clusters before being acknowledged to the application. This helps prevent data loss in the event of a complete cluster failure.
Entity Centric – Synchronous replication protection and recovery can be configured for a single VG, eliminating the need to protect the entire cluster or VGs and VMs within storage containers. This provides users with fine-grained control to selectively protect mission-critical workloads.
Automatic Failovers – Business continuity for mission-critical workloads is provided during disasters, like network partitions, cluster outages, etc., via automatic failovers driven by Nutanix Witness Service hosted in a different fault domain that facilitates quorum arbitration.
Multisite protection – To protect against outages affecting multiple Nutanix clusters, users can configure asynchronous replication to a third Nutanix cluster in a separate fault domain for a VG already protected by synchronous replication.
This technology enables the deployment of clustered databases like MSSQL FCI on top of WSFC with shared storage mirrored across data centers, clusters or sites to help ensure business continuity for mission-critical workloads.
Failure Scenarios
To fully explain how the solution works end to end, let's examine some common failure scenarios and see how the system maintains high availability.
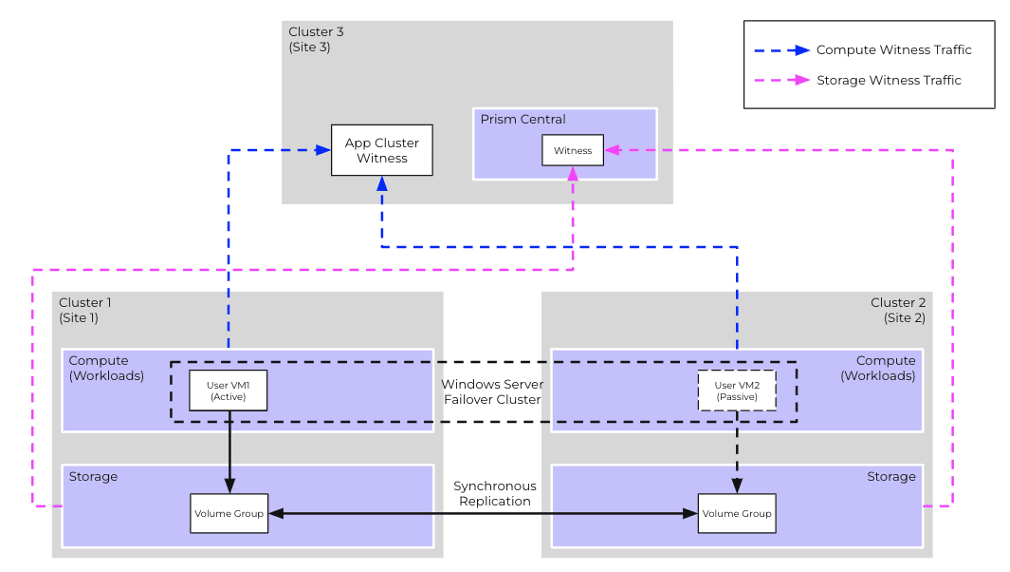
For the above exercise, let’s consider a typical deployment scenario:
- The deployment spans across 3 different sites:
- Cluster 1 and Cluster 2 host the VMs running the clustered application (MSSQL database over WSFC in this example). The storage instances, on the other hand, utilise synchronous replication for high availability of VG across the clusters.
- Cluster 3 hosts:
- App Cluster Witness: A component used by clustering applications like WSFC so only one of the instances can access cluster resources during split-brain scenarios.
- Nutanix Witness Service: A component that provides similar tie-breaker functionality for storage instances
- Nutanix Prism Central: The management component responsible for overseeing Nutanix managed components across sites. It is typically a centralized management service that provides visibility, configuration and monitoring capabilities.
- In this setup VM1 and VM2 are deployed on separate sites, forming a WSFC cluster.
- WFSC ensures that only one VM can own and access cluster resources at any given time, preventing simultaneous access by both VMs
- In this scenario, VM1 is the current owner of the resources, meaning it has exclusive access to them and can handle requests and workloads. If VM1 fails or becomes unavailable, VM2 will take over the ownership of the resources to keep things running smoothly.
- In a split-brain situation, the App Cluster Witness quorum helps decide which VM should own the resources, preventing simultaneous VM access.
- The shared storage required by the WSFC is provided across data centers using synchronous replication of Volume Groups (VGs)
- VM1 attached to the shared VG via iSCSI using the Data Services IP of Cluster 1 (Site 1)
- VM2 attached to the same shared VG via iSCSI using the Data Services IP of Cluster 2 (Site 2)
In the below scenarios, VM1 running on Cluster 1 owns complete access to storage.
Scenario #1: Production Site VM Failure
Consider a scenario where the VM1, actively interacting with the storage, experiences a crash.
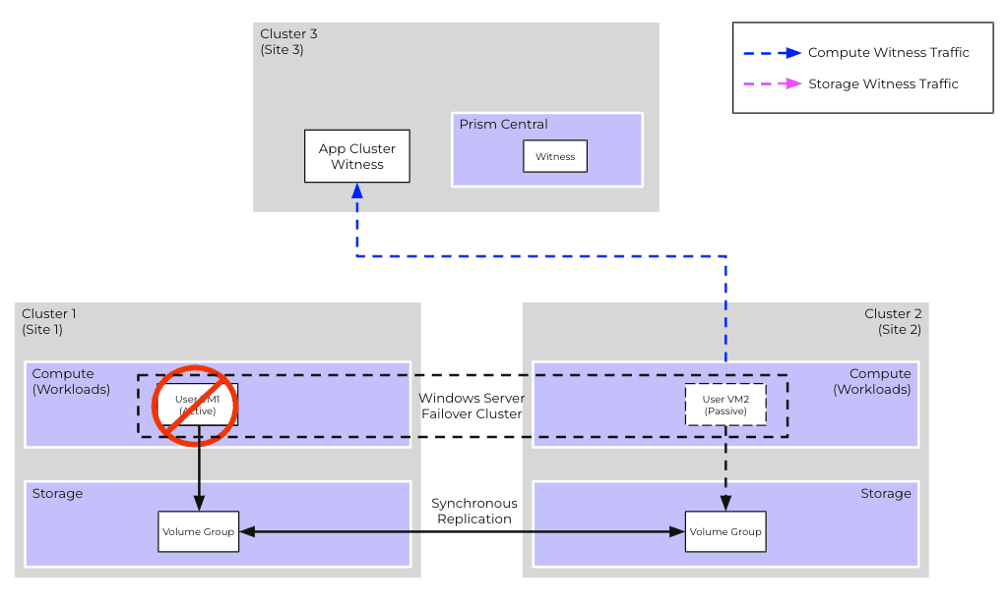
Recovery Procedure
- WSFC transfers the ownership of cluster resources from VM1 to VM2
- VG hosted on Cluster 2 processes the incoming traffic from VM2.
- No administrative operations are necessary
Scenario #2: Production Site Failure
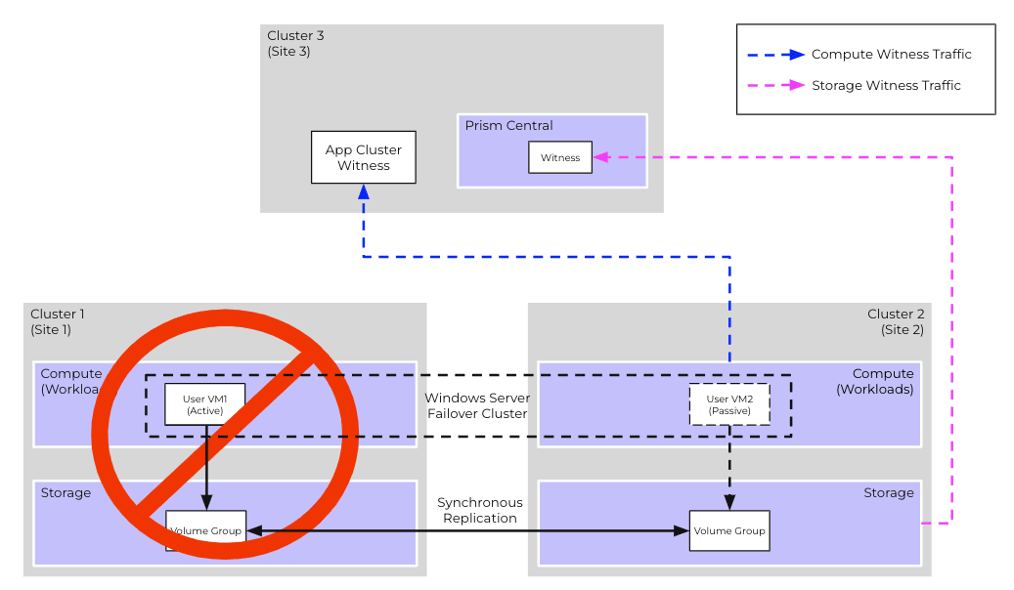
Recovery Procedure
- Storage instance on Cluster 2 detects an outage on Cluster 1 due to heartbeat failures
- After the user-configured timeout (default = 30 secs), the storage instance on Cluster 2 will attempt to acquire exclusive ownership of VG via the Witness Service and succeeds
- Unplanned failover is initiated on Cluster 2
- This results in VG on Cluster 2 becoming independent and no longer in synchronous replication, with all further updates persisted locally
- WSFC transfers the ownership of cluster resources from VM1 to VM2
- No administration operations are necessary
- If Cluster 1 recovers later, synchronous replication is automatically re-established on the VG and any delta changes are synced. Additionally, VM1 will be automatically reconnected to the VG instance on Cluster 1
Scenario #3: Network Partition between sites but both sites can access the 3rd site
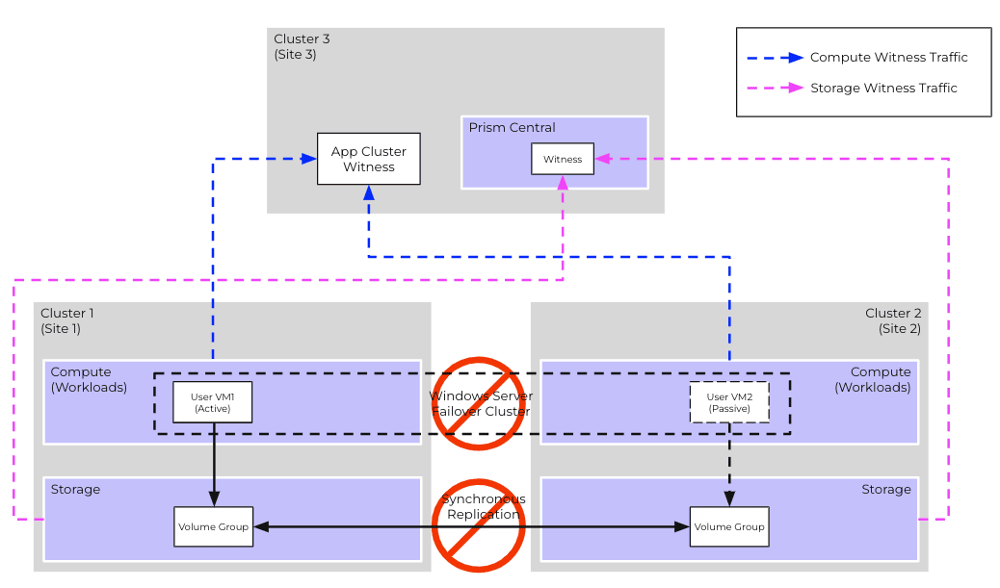
Recovery Procedure
- Storage instances on both Cluster 1 and Cluster 2 will consider the other as not reachable due to heartbeat failures
- After the user-configured timeout (default = 30 secs), both storage instances will attempt to claim exclusive ownership of the VG via the Witness Service
- Witness Service will resolve the tie and the winner (in this case, storage instance on Cluster 1) will become the exclusive owner of the VG
- The storage instance on Cluster 1 will then pause synchronous replication, and all further updates to the VG will be persisted locally
- WSFC ensures that VM1 remains the owner of cluster resources
- No administrative operations are necessary
- Once the network partition is resolved, the administrator can manually resume synchronous replication on the VG. After doing so, VM2 will automatically connect to the VG instance present on Nutanix Cluster 2
Scenario #4: DR Site Failure
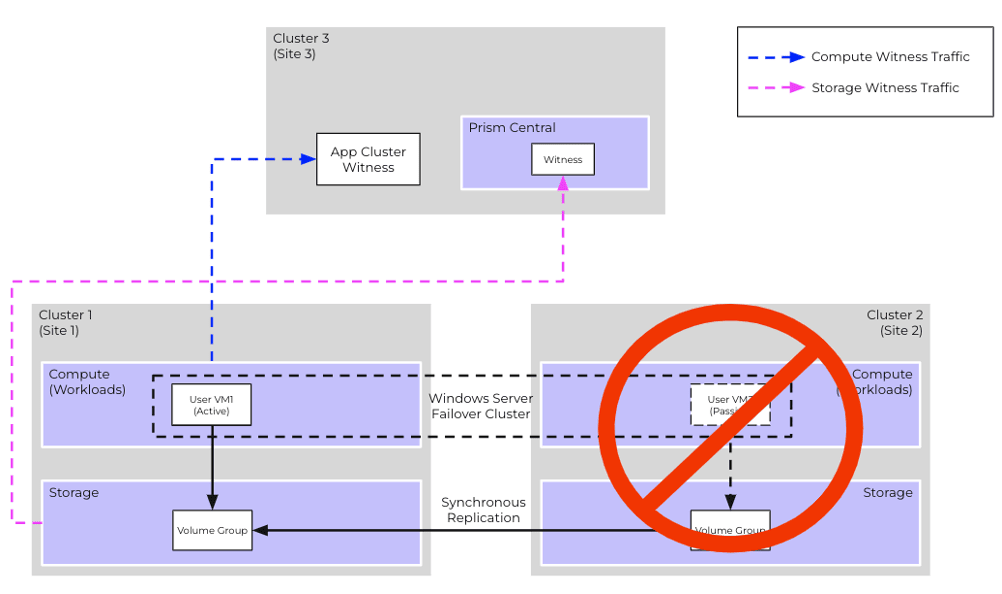
Recovery Procedure
- Storage on Cluster 1 detects an outage on Cluster 2 due to heartbeat failures
- After the user-configured timeout (default = 30 secs), storage instance on Cluster 1 will attempt to claim exclusive ownership of the VG via the Witness Service and succeed
- The storage instance on Cluster 1 will then pause synchronous replication, and any future data or config updates to the VG will be persisted locally
- WSFC ensures that VM1 remains the owner of cluster resources
- No administrative operations are necessary
- Once the network partition is resolved, the administrator can manually resume synchronous replication on the VG. After doing so, VM2 will automatically connect to the VG instance present on Nutanix Cluster 2
Scenario #5: Production Site Network Isolation
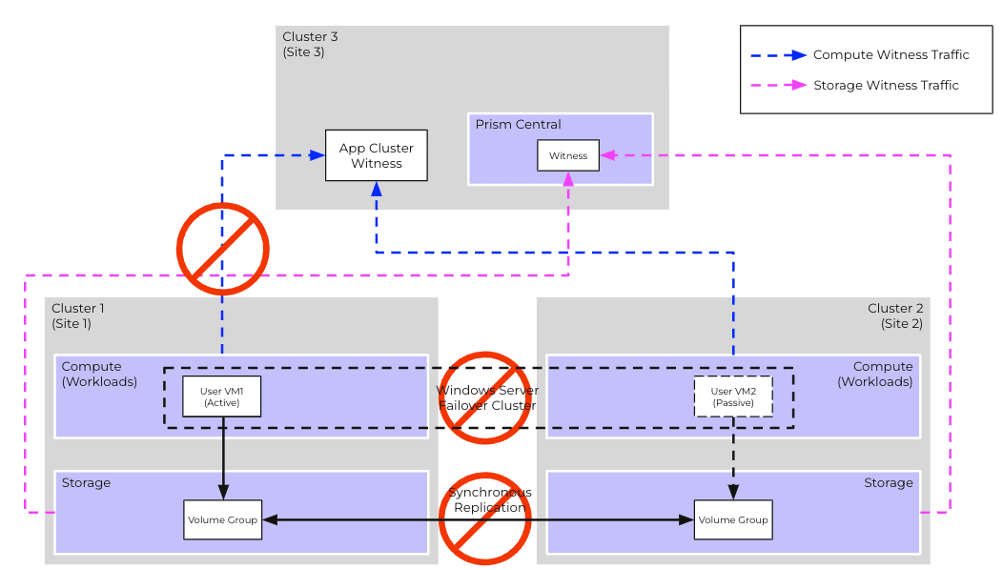
Consider a scenario where Cluster 1 is network-isolated from Cluster 2 and Cluster 3. This typically represents a double failure scenario, where multiple independent network links fail simultaneously.
Recovery Procedure
- Storage instances on both Cluster 1 and Cluster 2 will detect heartbeat failures from their respective peers.
- Both storage instances will periodically attempt to contact Witness Service on Cluster 3
- However, the storage instance on Cluster 1 will be unable to reach the Witness Service for a sustained period and will pre-emptively revoke storage access to the VG
- This action is taken to prevent the VG from being accessible from both clusters simultaneously
- After the user-configured timeout (default = 30 secs), storage instance on Cluster 2 will acquire exclusive ownership of the VG via the Witness Service and initiate an unplanned failover
- This results in VG on Cluster 2 becoming independent and no longer in synchronous replication, with all further updates persisted locally
- WSFC transfers the ownership of cluster resources from VM1 to VM2
- No administration operations are necessary
- If Cluster 1 recovers at a later point in time, the storage instance on Cluster 2 automatically resumes synchronous replication on the VG and resyncs the delta. VM1 will also be automatically reconnected to the VG instance on Cluster 1
Scenario #6: Prism Central cluster outage
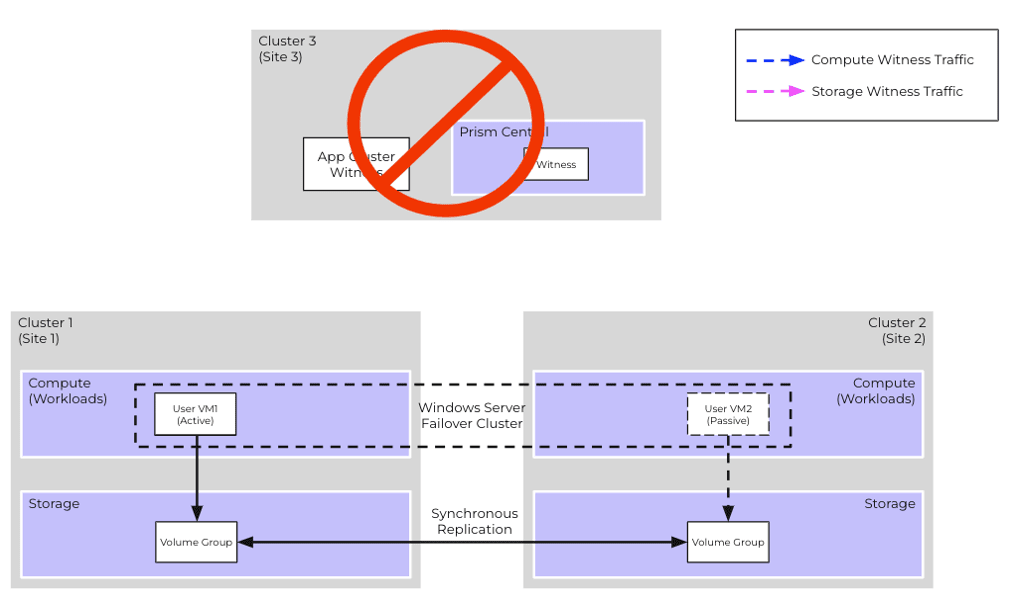
If Cluster 3, which hosts the App Cluster Witness and the Witness Service, experiences an outage, there is no impact on existing application workloads. They will continue to operate.
However, if another failure occurs alongside the outage, such as a network partition between sites, it would impact the running workloads and the application could experience downtime.
Conclusion
In today’s enterprises, data protection and disaster recovery of mission-critical workloads are paramount. This is further bolstered by regulations like the Digital Operations Resilience Act (DORA) which involves compliance requirements for the same.
Technologies like Nutanix Metro Availability (MA) for Volume Groups (VG) can be leveraged to satisfy these regulations by making data available across sites for resiliency. Nutanix also provides disaster recovery orchestration for automatic failure detection and seamless recovery, without a need for administrative actions, allowing the entire disaster recovery process to be automatic.
When combined with Microsoft Windows Server Failover Cluster (WSFC) for application-level resiliency, the solution empowers enterprises to deliver high availability and fault tolerance for their mission-critical database workloads.
©2025 Nutanix, Inc. All rights reserved. Nutanix, the Nutanix logo and all Nutanix product and service names mentioned herein are registered trademarks or trademarks of Nutanix, Inc. in the United States and other countries. All other brand names mentioned herein are for identification purposes only and may be the trademarks of their respective holder(s).
This post may contain express and implied forward-looking statements, including but not limited to statements regarding our plans and expectations relating to new product features and technology that are under development, the capabilities of such product features and technology, and our plans to release product features and technology in the future. Such statements are not historical facts and are instead based on our current expectations, estimates and beliefs. The accuracy of such statements involves risks and uncertainties and depends upon future events, including those that may be beyond our control, and actual results may differ materially and adversely from those anticipated or implied by such statements. Any forward-looking statements included herein speak only as of the date hereof and, except as required by law, we assume no obligation to update or otherwise revise any of such forward-looking statements to reflect subsequent events or circumstances. Any future product or product feature information is intended to outline general product directions and is not a commitment, promise, or legal obligation for Nutanix to deliver any functionality. This information should not be used when making a purchasing decision.