- ISO used for install: phoenix.x86_64-fnd_5.6.1_patch-aos_6.8.1_ga.iso
After I installed the nodes I run following command on one of the CVM to create a new cluster: - cluster -s 172.19.1.121,172.19.1.122,172.19.1.123,172.19.1.124 create
But short after the cluster creation process stuck and shows the following message in a refreshing state: (Waiting about 12h but nothing has changed)
Do you have any hints where I can take a look into to find out why the services does not start as expected during the cluster creation process?
Thank you very much in advance!
Page 1 / 1
Hey,
That’s great lab hardware, very jealous ;)
What do you see in the genesis.out on the nodes during this period?
I suspect something is stuck trying to start and everything else is hanging off the back of it, does it work if you ctrl + c and run it again?
Can all CVMs see each other happily etc?
Are you using multiple NIC’s plugged in or just one at the moment?
Thanks,
Kim
Hi Kim,
thanks for your quick reply!
Checked the genisis.log this are the last logs entries after I run the cluster creation command:
2025-05-21 14:43:19,275Z INFO MainThread service_utils.py:1274 Genesis service start with current context pid is : 36391 audit login uid : 4294967295 2025-05-21 14:43:19,275Z INFO MainThread service_utils.py:1276 Genesis service start request with command line args: ['/home/nutanix/cluster/bin/genesis', 'start'] audit user_login_id: 4294967295 2025-05-21 14:43:19,277Z INFO MainThread zookeeper_session.py:136 Using multithreaded Zookeeper client library: 1 2025-05-21 14:43:19,279Z INFO MainThread zookeeper_session.py:248 Parsed cluster id: 2255648239335055121, cluster incarnation id: 1747836779032507 2025-05-21 14:43:19,279Z INFO MainThread zookeeper_session.py:270 genesis is attempting to connect to Zookeeper, host port list zk1:9876,zk2:9876,zk3:9876 2025-05-21 14:43:29,289Z ERROR MainThread genesis_utils.py:3315 Could not reach zookeeper 2025-05-21 14:43:29,291Z ERROR MainThread service_utils.py:254 Not syncing gflags from zookeeper 2025-05-21 14:43:29,291Z INFO MainThread service_utils.py:1365 Starting genesis with rlimits {} 2025-05-21 14:43:29,291Z INFO MainThread service_utils.py:1431 HTTP handler based gflags updates disabled for genesis 2025-05-21 14:43:29,294Z INFO Dummy-1 zookeeper_session.py:941 Calling zookeeper_close and invalidating zhandle 2025-05-21 14:43:29,299Z WARNING MainThread service_utils.py:788 Component genesis is being run without a cgroup memory limit, creating a cgroup with unlimited memory 2025-05-21 14:43:29,300Z ERROR MainThread service_utils.py:708 Failed to apply memory limit for genesis as negative value provided. 2025-05-21 14:43:29,300Z INFO MainThread service_utils.py:839 Adding process id 45020 to cgroup genesis. 2025-05-21 14:43:29,373Z INFO MainThread service_utils.py:536 Adding process id 45020 to CPU cgroup genesis. 2025-05-21 14:43:29,444Z INFO MainThread service_utils.py:860 Setting oom score -1000 for genesis with process id 45020. 2025-05-21 14:43:29,524Z INFO Dummy-1 zookeeper_session.py:941 Calling zookeeper_close and invalidating zhandle
Also tried to restart the cluster creation process with CTRL+C → re run cluster creation command. But then you will get the message that the nodes are already part of a cluster and can not be used again. So you need to destroy the cluster first to be able to re run the cluster creation command.
Yes all CVMs can reach each other. All nodes are in the same network with same VLAN access port applied to the network ports where the nodes are connected to.
All nodes are connected with two interfaces one interface of each of the two used NICs.
Update: My first reply still needs to be checked by a moderator my seconds reply this one seems to be directly shown thats why I am adding the missing infos from the first reply as well because they will not be shown so far.
Thank you for you quick reply Kcmount!
I already tried to stop the process with CTRL+C and re run the cluster creation process. Unfortunately the process says that the nodes can not be added because there are already part of a cluster. So I stopped the cluster and destroyed it to be able to recreate the cluster with the command.
Right now all nodes have two NICs and on interface of both are connected to switch. Also all ports are in the same VLAN and the nodes are able to see each other.
I only checked genesis.log not genesis.out log. Checked it on all 4 nodes and on node 3-4 there seems to be issues with Cassandra on node 1-2 it looks OK from my site.
Node 3:
2025-05-22 09:17:59,212Z INFO 19420864 service_mgmt_utils.py:146 current_disabled_services {'SnmpService'} 2025-05-22 09:17:59,212Z INFO 19420864 service_mgmt_utils.py:147 current_enabled_services set() 2025-05-22 09:17:59,813Z INFO 19420864 zookeeper_service.py:598 Zookeeper is running as follower 2025-05-22 09:17:59,813Z INFO 19420864 genesis_utils.py:8761 Executing cmd: /usr/local/nutanix/secure/bin/ntnx_privileged_cmd genesis get_pids --all 2025-05-22 09:17:59,905Z WARNING 27989056 cassandra_service.py:854 Unable to get the Cassandra token for 172.19.1.123, ret 3, stdout , stderr Error: "Failed to retrieve RMIServer stub: javax.naming.ServiceUnavailableException eRoot exception is java.rmi.ConnectException: Connection refused to host: localhost; nested exception is: java.net.ConnectException: Connection refused (Connection refused)]" connecting to JMX agent, host: localhost port: 8080
2025-05-22 09:18:00,674Z INFO 19420864 zookeeper_service.py:598 Zookeeper is running as follower 2025-05-22 09:18:00,675Z INFO 19420864 epsilon_service.py:395 Checking epsilon status 2025-05-22 09:18:00,708Z INFO 19420864 service_mgmt_utils.py:146 current_disabled_services {'SnmpService'} 2025-05-22 09:18:00,709Z INFO 19420864 service_mgmt_utils.py:147 current_enabled_services set() 2025-05-22 09:18:01,106Z WARNING 27989056 cassandra_service.py:854 Unable to get the Cassandra token for 172.19.1.123, ret 3, stdout , stderr Error: "Failed to retrieve RMIServer stub: javax.naming.ServiceUnavailableException eRoot exception is java.rmi.ConnectException: Connection refused to host: localhost; nested exception is: java.net.ConnectException: Connection refused (Connection refused)]" connecting to JMX agent, host: localhost port: 8080
Node 4:
2025-05-22 09:18:00,710Z INFO 29804576 service_mgmt_utils.py:146 current_disabled_services {'SnmpService'} 2025-05-22 09:18:00,710Z INFO 29804576 service_mgmt_utils.py:147 current_enabled_services set() 2025-05-22 09:18:00,714Z INFO 29804576 genesis_utils.py:8761 Executing cmd: /usr/local/nutanix/secure/bin/ntnx_privileged_cmd genesis get_pids --all 2025-05-22 09:18:00,845Z WARNING 00528512 cassandra_service.py:854 Unable to get the Cassandra token for 172.19.1.124, ret 3, stdout , stderr Error: "Failed to retrieve RMIServer stub: javax.naming.ServiceUnavailableException eRoot exception is java.rmi.ConnectException: Connection refused to host: localhost; nested exception is: java.net.ConnectException: Connection refused (Connection refused)]" connecting to JMX agent, host: localhost port: 8080
2025-05-22 09:18:00,960Z INFO 29804576 epsilon_service.py:395 Checking epsilon status 2025-05-22 09:18:02,006Z WARNING 00528512 cassandra_service.py:854 Unable to get the Cassandra token for 172.19.1.124, ret 3, stdout , stderr Error: "Failed to retrieve RMIServer stub: javax.naming.ServiceUnavailableException eRoot exception is java.rmi.ConnectException: Connection refused to host: localhost; nested exception is: java.net.ConnectException: Connection refused (Connection refused)]" connecting to JMX agent, host: localhost port: 8080
Can you tell a bit more about the disks in the nodes? (nvme, ssd, hdd etc?) And are you using RAID?
And also, remove 2 disks per node as 4 disks per node is the limit for CE. (not counting the ahv boot disk)
Hi JeroenTielen,
the hardware comes from an old Nutanix cluster which was take out of service.
I have configured the disk like shown in the installer setup. I was not fully sure if I mark multiple disk as CVM disk if I still can use the disk as data. But this cluster should be a testing cluster to get some experience with Nutanix CE before we create a real Nutanix CE cluster.
So if I did some mistakes in the setup please let me know :)
Node 1: Disk 1 - SSD 223.6 GiB - Hypervisor Disk 2 - SSD 223.6 GiB - CVM Disk 3 - SSD 3.5 TiB - Data Disk 4 - SSD 3.5 TiB - Data Disk 5 - SSD 3.5 TiB - Data Disk 6 - SSD 3.5 TiB - Data Disk 7 - SSD 3.5 TiB - Data Disk 8 - SSD 3.5 TiB - Data
Node 2: Disk 1 - SSD 223.6 GiB - Hypervisor Disk 2 - SSD 223.6 GiB - CVM Disk 3 - SSD 3.5 TiB - Data Disk 4 - SSD 3.5 TiB - Data Disk 5 - SSD 3.5 TiB - Data Disk 6 - SSD 3.5 TiB - Data Disk 7 - SSD 3.5 TiB - Data Disk 8 - SSD 3.5 TiB - Data
Node 3: Disk 1 - Marvell_NVMe_Controller__1 476.9 GiB - Hypervisor Disk 2 - SSD 3.5 TiB - CVM Disk 3 - SSD 3.5 TiB - CVM Disk 4 - SSD 3.5 TiB - Data Disk 5 - SSD 3.5 TiB - Data Disk 6 - SSD 3.5 TiB - Data Disk 7 - SSD 3.5 TiB - Data
Node 4 : Disk 1 - Marvell_NVMe_Controller__1 476.9 GiB - Hypervisor Disk 2 - SSD 3.5 TiB - CVM Disk 3 - SSD 3.5 TiB - CVM Disk 4 - SSD 3.5 TiB - Data Disk 5 - SSD 3.5 TiB - Data Disk 6 - SSD 3.5 TiB - Data Disk 7 - SSD 3.5 TiB - Data
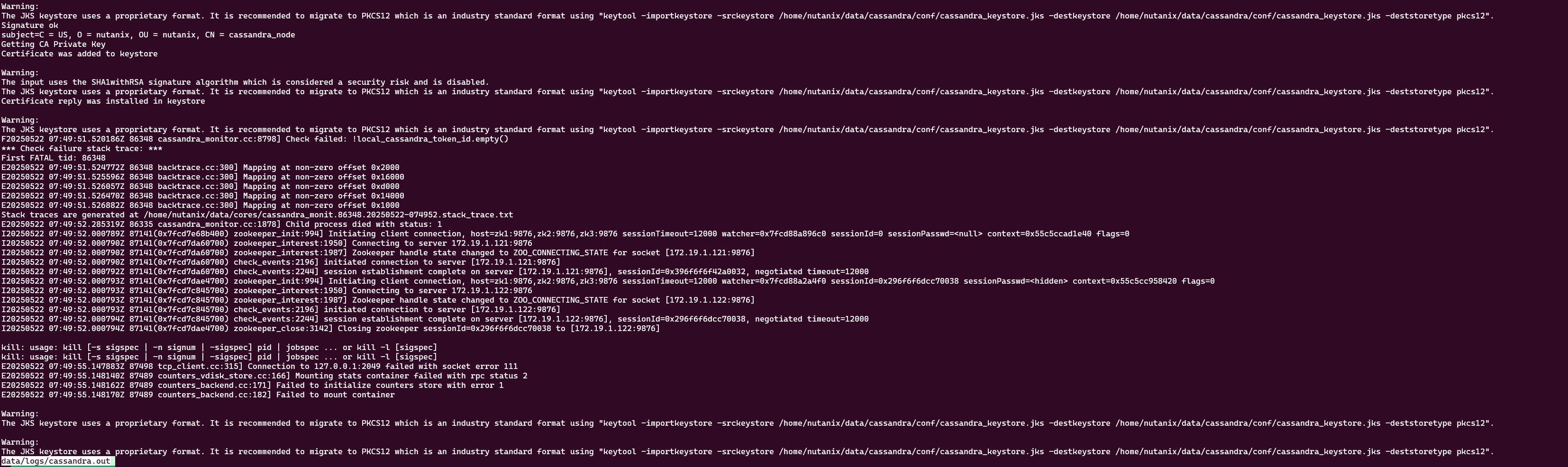
Update: Attached strack_trace_file
I see a stack trace in a loop in cassandra.out log. Unfortunately all posts with the raw log has been marked for checking via moderator team. So I try to paste the stack trace via image to quick this up and hope that I can post it without reviewing.
I understand that the nodes are orignal nutanix node but the limit for ce is 4 disks per node.
i would really suggest to remove all disks and only leave 4x 3,5ssd’s in it for cvm/data. And then select 2x for cvm and 2x for data.
ok, I will try it and reinstall the nodes with 1 hyperbvisor disk and 4 CVM/Data disk (2CVM & 2 Data) and will check if this will solve the issue which I have with node 3&4 .
However, I am surprised that in the installation dialog of Nutanix itself more than 4 disks are preselected for CVM/Data when Nutanix itself specifies a maximum number of 4 CVM/Data disks. Also that you are able to select more than 4 disks. I there any reason for that?
That is only for CE. Normal production/commercial version you can use more. But yes, the installer will show more, and probably it will work as well for you, but better getting it to work withing the requirements and later you can try to add the disks.
One more thing, the first two nodes are those older G6 nodes? If so, enable the built-in RAID controller (in the bios) and create a RAID 1 from the two (2) 240GB disks. And use that one for AHV.
Yes I will create a RAID 1 out of the two 240GB disks and will setup everything as suggested.
Thank you for your help!
I enabled the “Intel VMD Technology” (screenshot 1) and set the “Configure sSATA as” from “AHCI” to “RAID” (screenshot 2). I than created a RAID 1 volume out of the the two 240GB disks with the “Intel Rapid Storage Technology” during startup. But unfortunately after changes. I was not able to select the raid volume. The installer only show still the 240GB disks in the setup dialog and furthermore the data/cvm disks disappeared. (screenshot 3)
I was only able to get the disks back in the install dialog when I changed the “Configure sSATA as” back from “RAID” to “AHCI”. But than I am not able to create a RAID via “Intel Rapid Storage Technology” during startup.
Did I miss anything or doesn't support Nutanix CE software raid volumes?
Good news, the cluster creation command ran without problems this time and the cluster was created successfully.
Maybe someone also know or have a hint why Nutanix didn’t show the RAID volume inside of the setup dialog, or why the other disks will not be shown if “AHCI” has changed to “RAID”.
Thank you very much so far for your help and have a nice weekend!