I was testing Link Failover and it was not working as expected. I have configured ACtive-Standby, and once I am taking out the cable from NIC1 all the traffic does not goes through Standby link, after connecting nic back, the traffic was also restored. Just want to know the faiover scenario related to NIC.
Note : Time seems to be correct in every CVM
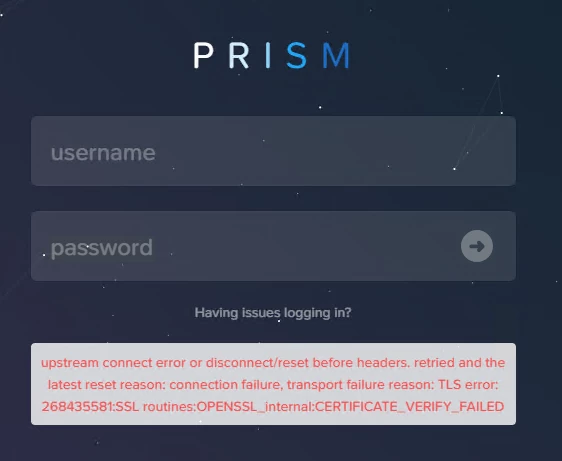
Once the traffi is back I am trying to access CVM with virtual IP giving below error
Page 1 / 1
Can you show us a screenshot from the network Dashboard in prism element?
I am unable to login to element not sure how can I show? Can you guide more?
Hi there, based on the error:
“upstream connect error or disconnect/reset before headers. retried and the latest reset reason: connection failure, transport failure reason: TLS error: 268435581:SSL routines:OPENSSL_internal:CERTIFICATE_VERIFY_FAILED”
This appears to be is a TLS/SSL verification error when accessing Prism via a virtual IP (VIP). The connection is failing due to certificate validation issues, likely triggered by:
Untrusted or expired certificate on the CVM hosting the VIP.
DNS or VIP misrouting, causing a mismatch between the expected hostname and the certificate CN/SAN.
Client-side certificate validation strictness (e.g., using curl or gRPC libraries with hardened TLS settings).
Virtual IP being reassigned to a different CVM that doesn't have the SSL state correctly initialized, especially after your failover event.
Action
1. Bypass TLS Verification Temporarily (Only for Testing)
If you're using a script or CLI and not a browser, you can test:
curl -k https://<VIP>:9440
If that works, it confirms that TLS certificate validation is the blocker.
The link provided by you is not understandable unfortunately. I cannot do it.
Hi Himanschu, just to give a bit of clarity as to what's happened here is your NIC failover broke part of the trust path. Now Prism Central can’t securely talk to one of the CVMs (or VIP), because the cert it’s getting back is either invalid or doesn’t match what it expects. Restarting Genesis and making sure the cert is valid usually clears it.
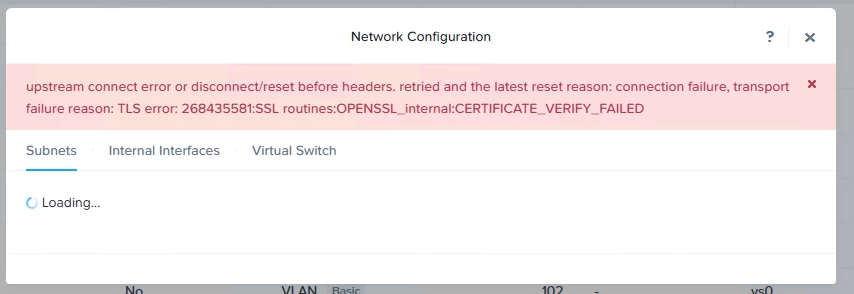
The same TLS error (CERTIFICATE_VERIFY_FAILED) is now happening within Prism Central, specifically when trying to load networking configuration (subnets, internal interfaces, virtual switches). This suggests:
Prism Central is attempting a secure gRPC/REST API call to a CVM or other Prism Element node, and the certificate presented is not valid or trusted.
This is not just a client-to-UI error, but a control plane internal trust issue between Prism Central and cluster services (likely over port 9440).
It’s likely triggered by recent failover or incorrect VIP handoff, which exposed an untrusted cert or stale service binding.
What this Confirms:
Your NIC failover did not complete cleanly.
As a result, the CVM that now holds a role (possibly VIP or service endpoint) is presenting either a self-signed, expired, or mismatched certificate.
Prism Central cannot establish trusted communication with the back-end component (e.g., Prism Element on the CVM).
Recommended Action
1. Check Certificate State on Affected CVM(s)
SSH to the CVM (or use the one hosting the VIP) and run:
Or do it via Prism GUI → Settings > SSL Certificate.
Point no 2 screenshot
Point No 3 : Does not show any thing in CVM CLI
Point No 4, I am unable to open the webpage
I am under very critical situation, help please
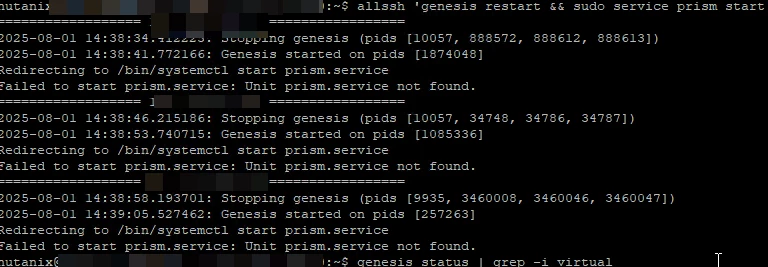
this is now very clearly a Genesis-level failure, not just a UI or cert issue.
Let me try to summarize what’s happening based on your screenshot:
What you are seeing:
You're running:
allssh 'genesis restart && sudo service prism start'
Genesis restarts successfully.
prism.service fails with:
Failed to start prism.service: Unit prism.service not found.
Running:
genesis status | grep -i virtual
...returns no VIP ownership or output.
What This Tells Us:
The prism.service you tried to start doesn’t exist because Prism is part of the genesis process tree and not managed via systemd on the CVMs.
The VIP assignment has not returned, likely due to a networking fault, misconfiguration, or certificate state issue that’s preventing Genesis from successfully reassigning it.
Next Steps
1. Skip the prism.service start, it's not needed.
Instead, just use:
allssh 'genesis restart'
Genesis handles Prism startup automatically on CVMs.
2. Check VIP assignment manually
Run this on each CVM:
ip a | grep 9440
Look for which CVM (if any) has the VIP bound to port 9440.
Also, try:
host <your-prism-vip>
and
ping <VIP>
to see if it's reachable.
3. Force VIP Reassignment (advanced)
You can try rotating the VIP manually:
genesis --rotate_virtual_ip
If that fails silently, try:
manage_ovs show_uplinks
...to ensure uplinks and bonds are healthy on each host.
4. Check Genesis Health Deeply
If Prism VIP isn’t coming back after restarting Genesis, check the Genesis logs:
cat ~/data/logs/genesis.out | grep -i vip
You're looking for lines like:
Assigning virtual IP ...
Binding VIP ...
Or errors like:
Failed to bind VIP due to ...
This is now beyond a simple cert issue, you have a VIP that’s not assigned, likely due to one of the following:
Bonding failure (interface not healthy or link not detected).
Misconfigured uplinks (Genesis can't bind VIP).
Inconsistent Genesis state (restart didn’t properly re-elect a CVM leader).
If this doesn’t resolve the issue and its a Production Cluster then I would urge that you contact Nutanix Support.
All Genesis Service Restarted successfully.
ip a | grep 9440 does not show anything
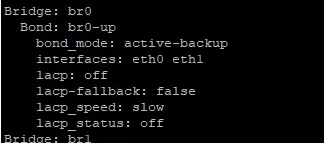
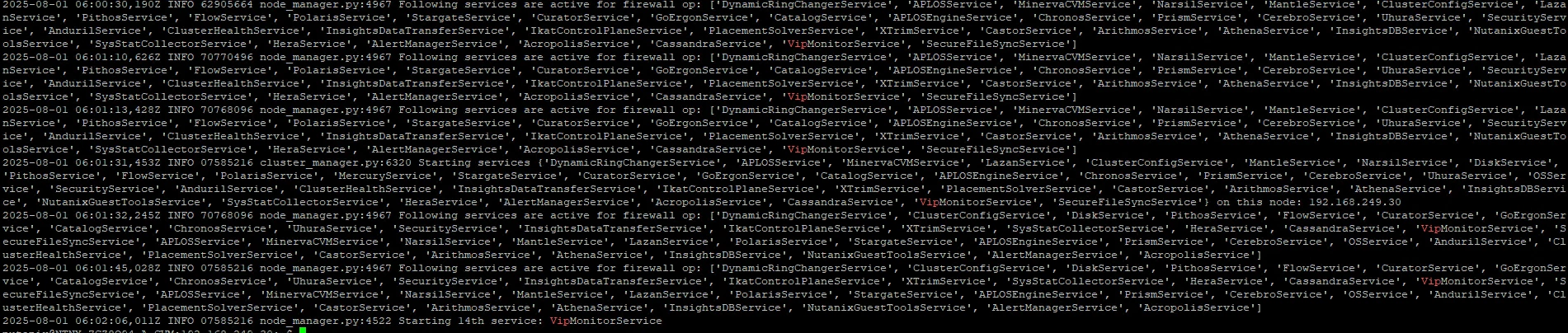
genesis --rotate_virtual_ip - provide lot of text what to look in to that? manage_ovs show_uplinks - SHows below
this confirms Genesis and Prism services are up, but the VIP is not assigned, and that’s your root problem now.
Confirmed is:
br0 is in active-backup mode with eth0 and eth1, no LACP this is fine.
Genesis logs show VipMonitorService started, which is responsible for managing VIPs.
ip a | grep 9440 shows nothing so the VIP is not currently assigned to any CVM.
genesis --rotate_virtual_ip runs, but you’re unsure what to look for in output.
What to Check Right Now:
1. Check Output of genesis --rotate_virtual_ip
Scroll through the output and look for lines like:
Releasing VIP from this node...
Assigning VIP 192.168.x.x to this node
Failed to assign VIP...
Unable to bind VIP to interface br0...
If there is any failure to bind, it will show there. Let me know or paste that snippet.
2. Check All CVMs for VIP via IP and Port
Run this on each CVM individually:
ip a | grep 192.168.249
Replace 192.168.249 with your VIP subnet. This ensures it's not hiding on another CVM.
3. Check Uplink Health
You said manage_ovs show_uplinks shows “below” but I can’t see that detail. You should look for:
State: up
A valid MAC address on each interface
Interface not disabled or down
If any bond member (eth0 or eth1) is showing down or link: false, Genesis may refuse to assign the VIP for safety.
Recovery Options:
If everything seems healthy but VIP is still unassigned, you can manually assign it temporarily for access (for emergency access only):
sudo ip addr add <VIP>/24 dev br0
Important: Do this on only one CVM, and only if you're confident it's safe.
Once you're in Prism:
Check Cluster > Settings > IP Addresses
Validate the VIP is properly configured there.
Then later you can let Genesis take over again by:
sudo ip addr del <VIP>/24 dev br0
genesis restart
TL;DR
Your system is healthy except VIP isn’t getting assigned. That’s likely due to:
Bond/interface state not healthy
Genesis logic refusing to bind
Network condition preventing VIP ARP announcement
Note, as I mentioned previously, if this is a “Production” Cluster you should seek Nutanix Support
I am under very critical situation, help please
Please involve support. That is the way to go. The AI answers given here can break more then you want.
this confirms Genesis and Prism services are up, but the VIP is not assigned, and that’s your root problem now.
Confirmed is:
br0 is in active-backup mode with eth0 and eth1, no LACP this is fine.
Genesis logs show VipMonitorService started, which is responsible for managing VIPs.
ip a | grep 9440 shows nothing so the VIP is not currently assigned to any CVM.
genesis --rotate_virtual_ip runs, but you’re unsure what to look for in output.
What to Check Right Now:
1. Check Output of genesis --rotate_virtual_ip
Scroll through the output and look for lines like:
Releasing VIP from this node...
Assigning VIP 192.168.x.x to this node
Failed to assign VIP...
Unable to bind VIP to interface br0...
If there is any failure to bind, it will show there. Let me know or paste that snippet.
2. Check All CVMs for VIP via IP and Port
Run this on each CVM individually:
ip a | grep 192.168.249
Replace 192.168.249 with your VIP subnet. This ensures it's not hiding on another CVM.
3. Check Uplink Health
You said manage_ovs show_uplinks shows “below” but I can’t see that detail. You should look for:
State: up
A valid MAC address on each interface
Interface not disabled or down
If any bond member (eth0 or eth1) is showing down or link: false, Genesis may refuse to assign the VIP for safety.
Recovery Options:
If everything seems healthy but VIP is still unassigned, you can manually assign it temporarily for access (for emergency access only):
sudo ip addr add <VIP>/24 dev br0
Important: Do this on only one CVM, and only if you're confident it's safe.
Once you're in Prism:
Check Cluster > Settings > IP Addresses
Validate the VIP is properly configured there.
Then later you can let Genesis take over again by:
sudo ip addr del <VIP>/24 dev br0
genesis restart
TL;DR
Your system is healthy except VIP isn’t getting assigned. That’s likely due to:
Bond/interface state not healthy
Genesis logic refusing to bind
Network condition preventing VIP ARP announcement
Note, as I mentioned previously, if this is a “Production” Cluster you should seek Nutanix Support
Nothing can be found in genesis --rotate_virtual_ip
IP is proverly assigned to CVMs
sudo ip addr add <VIP>/24 dev br0 - What we are doing here?
Note : I can ping the virtual IP Address.
this confirms Genesis and Prism services are up, but the VIP is not assigned, and that’s your root problem now.
Confirmed is:
br0 is in active-backup mode with eth0 and eth1, no LACP this is fine.
Genesis logs show VipMonitorService started, which is responsible for managing VIPs.
ip a | grep 9440 shows nothing so the VIP is not currently assigned to any CVM.
genesis --rotate_virtual_ip runs, but you’re unsure what to look for in output.
What to Check Right Now:
1. Check Output of genesis --rotate_virtual_ip
Scroll through the output and look for lines like:
Releasing VIP from this node...
Assigning VIP 192.168.x.x to this node
Failed to assign VIP...
Unable to bind VIP to interface br0...
If there is any failure to bind, it will show there. Let me know or paste that snippet.
2. Check All CVMs for VIP via IP and Port
Run this on each CVM individually:
ip a | grep 192.168.249
Replace 192.168.249 with your VIP subnet. This ensures it's not hiding on another CVM.
3. Check Uplink Health
You said manage_ovs show_uplinks shows “below” but I can’t see that detail. You should look for:
State: up
A valid MAC address on each interface
Interface not disabled or down
If any bond member (eth0 or eth1) is showing down or link: false, Genesis may refuse to assign the VIP for safety.
Recovery Options:
If everything seems healthy but VIP is still unassigned, you can manually assign it temporarily for access (for emergency access only):
sudo ip addr add <VIP>/24 dev br0
Important: Do this on only one CVM, and only if you're confident it's safe.
Once you're in Prism:
Check Cluster > Settings > IP Addresses
Validate the VIP is properly configured there.
Then later you can let Genesis take over again by:
sudo ip addr del <VIP>/24 dev br0
genesis restart
TL;DR
Your system is healthy except VIP isn’t getting assigned. That’s likely due to:
Bond/interface state not healthy
Genesis logic refusing to bind
Network condition preventing VIP ARP announcement
Note, as I mentioned previously, if this is a “Production” Cluster you should seek Nutanix Support
I raised a ticket.
Interesting observation... but as I’ve mentioned earlier, if this is a production environment, then yes as JeroenTielen has also mentioned, engaging Nutanix Support is absolutely the right approach.
Hello Team,
Thank you so much for jumping out here and giving useful suggestion and feedback, finally issue was resolved after loggin a case withnutanix. The actual issue was somehow after Network Testing, the CVM time move ahead of PC time, thus causing browser access issue, after waiting for the time to match with not before, it automatically got accessed.