

本記事は2020年2月26日にJosh Odgers氏が投稿した記事の翻訳版です。
このシリーズでは、重複排除と圧縮、およびイレージャーコーディングを使用する際に、Nutanixがより多くの使用可能な容量を提供するとともに、より大きな容量効率、柔軟性、回復力、およびパフォーマンスを提供することを学びました。
また、Nutanixははるかに簡単で優れたストレージのスケーラビリティを提供し、ドライブの障害による影響を大幅に軽減していることも知りました。
このパートでは、異なるモデルで構成するクラスタのサポートについて説明します。これは、HCIプラットフォームの拡張機能にとって非常に重要であり、絶えず変化するユーザーの要件を満たす/それ以上を提供するということを学んでいきます。
ハードウェアのキャパシティ/パフォーマンスは非常に速いペースで進歩し続けており、ユーザーが一様な(同一スペックのノードによる)クラスタを使用することを余儀なくされた場合、TCOは上がり、投資の回収に多くの時間を必要とする可能性があります。これだけでも好ましくない事態ですが、それだけでなく、ユーザーが非効率的なサイロを作らなければ、新しいハードウェアの性能や集約のメリットを活かせなくなることを意味します。
つまるところ、古いSAN時代のように、ハードウェアを「総入れ替え」する必要があるような状況にはなりたくありません。
それでは、簡単な「チェックボックスの比較」から始めてみましょう。
| サポートされているクラスタのノード構成 | Nutanix | VMware vSAN |
| Heterogeneous(異なるモデルノード混在構成) |
|
|
| Homogeneous(同一モデルノードのみの構成) |
|
|

以前にも私が記事で強調したように "チェックボックス "スタイルの評価は、一般的に製品の機能についての誤った理解につながることを述べました。今回の記事は、この("チェックボックス "スタイルの)評価における問題のまさに典型的なモデルで、簡単な例を挙げてみます。
再びDellEMCが推奨するハードウェアプラットフォームであるVxRail E-Seriesの4ノードクラスタを例にとります。
ここでは、CPUとメモリを大量に消費するビジネスクリティカルなアプリケーション(ExchangeとSQL)とActive Directoryのようなリソースをそれほど消費しない、小さなVMが混在して実行されるクラスタを想定します。
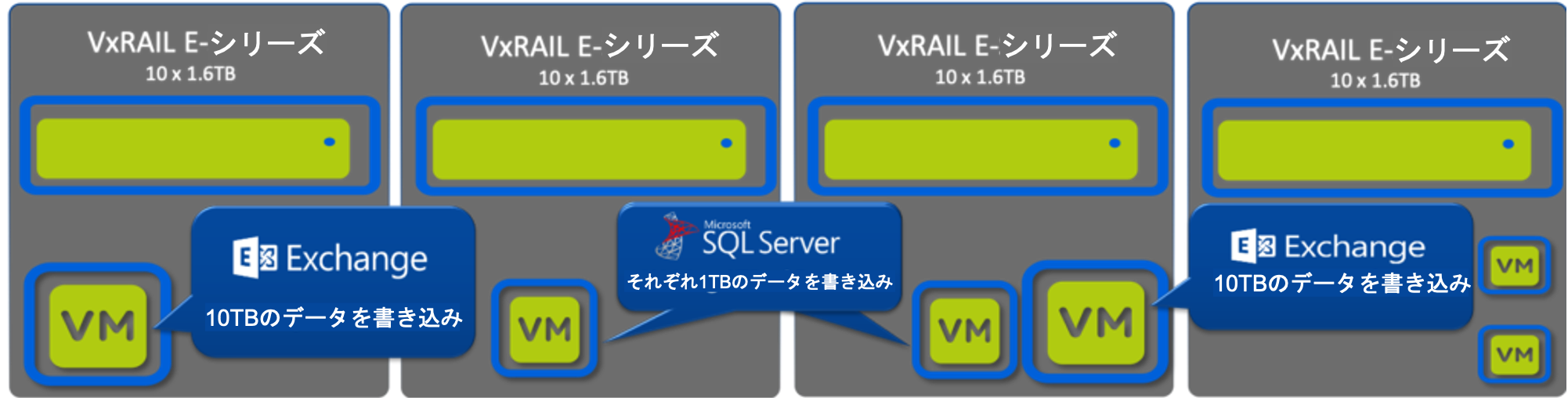
次に、コンプライアンス要件が新しくなり、メールの長期保存に必要な大容量のストレージのために、CPUとメモリだけでなくストレージも拡張し、自然な成長に応じた対応をしたいと考えます。これは、同じくコンプライアンスデータを格納するSQL環境にも影響を与える流れです。
ハードウェアオプションを確認し(DellEMC VxRailカタログを参考に)、以下の説明に基づいて要件を満たしていると思われるVxRail P-Seriesを見つけました。
データベースなどの集中的なワークロード向けのAll NVMeオプションを備えた、1、2、または4ソケットでの構成に最適化されたパフォーマンス重視の2U/1ノードプラットフォーム
すでにNutanixは、実際に(vSANより)最大で41.25%多い使用可能容量を提供可能であることを学びましたが、ここでは使用可能な容量の数値ではなく、新しいノードを追加したときに両製品がどのように動作するかに焦点を当ててみます。
ここで、既存のEシリーズノードと同じCPUとメモリを搭載する4台の新しい(Pシリーズの)ノードを追加しますが、Eシリーズの10台(のドライブ)に対して、Pシリーズは24台の1.6TB SSDドライブを備えたものになっています。これで、異なるモデルで構成された8ノードのクラスタになりました。
このシナリオでvSANがどのように動作するかについて確認していきましょう。
読み取りI/Oは、オブジェクトをホストしている4つのノード間でラウンドロビン方式で行われ、書き込みについても同様に、I/Oは新しいノードがクラスタに存在しないかのように同じ4つのノード内で継続されます。
これは、VMがこれらのノードにvMotionした場合でも、4つの新しいノードはvSAN I/Oに使用されないことを意味します。
結果として、4つの新しいノードへのI/Oが行われていないと言うことは(vSANオブジェクトが移動していないため)、管理者が手動でリバランスを行うか、またはノード(キャパシティ)が80%に達して自動リバランスが行われるまでは、新しいノードは何の価値も提供しないと言うことです。
使用率が80%未満であれば、管理者による手動でのリバランスが行われない限り、新しいノードは使用されません。
結果1:環境のパフォーマンスは向上しません。
追加の使用可能なキャパシティはどうですか?
vSAN データストアに追加されたキャパシティが表示されていても、以下のいずれかが発生しない限り、追加されたキャパシティそれ自体を使用できません:
- 一部のオブジェクトを新しいノードに移動する手動のリバランス
- 自動リバランス (ただし、ノードの利用率が80%(デフォルト設定値)を超えている場合のみ)
- 新しいVMまたは仮想ディスクが作成される
結果2:大量のデータ移動{および|または}管理者による手動での介入(新しいVMまたはvDiskの作成)がなければ、使用可能なキャパシティは改善されません。
このシナリオでは、4台の新しいノードが利用可能になったにもかかわらず、クラスタがバランスのとれた状態になっていないために、VMが書き込みエラー(Out of Space:スペース不足)が発生する可能性があります。
この時点で、vSANの管理者が手動で環境のリバランスを開始し、クラスタのバランスがとれた状態に戻ったと仮定しても、その際に生じる大量のデータ移動が、クラスタに何らかの影響を与え、データ移動が完了するまでに時間がかかることを認識しておきましょう。
新しい書き込みI/Oは、引き続き固定されたオブジェクトに書き込まれています。これは、将来の手動または自動のリバランスが必要な状態になる可能性が高く、すでに学んだように、最大255GBのオブジェクトを一括して移動することになります。
結果3:vSANクラスタ(のストレージキャパシティ)は積極的にバランスの維持がされておらず、環境のキャパシティ使用率が増加するにつれて、将来的にはバランスの再調整が必要になります。
これに加えて、特に重要なワークロード、このケースにおいてはMS SQL と MS Exchangeのパフォーマンスは、(vSANが)VMオブジェクトをホストするノードにのみ書き込みを行うため、このクラスタが持つ潜在的な書き込みI/Oのパフォーマンスを十分に発揮できない可能性があります。
vSANのリバランスは、クラスタのバランスをとるために、一度に最大255GBのオブジェクトを移動します。
vSANは異なるモデルの混在環境で大きな課題を抱えており、ユーザーは、追加のサイロを増築するか、または多くの運用上の複雑さとリスク抱えるか、の選択を迫られます。
ここからは、同じシナリオでNutanix ADSFがどのように機能するかを見ていきましょう。
Nutanix ADSFは、新しいvDiskを作成する、もしくはVMが新しいノードに移動されていない場合でも、すぐに4つの新しいノードを含むクラスタ全体に新しい書き込みI/Oの送信を開始します。
(この振る舞いは)本質的には、VMがDRSによって、または手動で新しいノードに移行されるまで、新しいノードは「ストレージ専用ノード」として動作するということです。
このインテリジェントなレプリカ配置(またはインラインバランシング)はリアルタイムに行われるため、クラスタのパフォーマンスを即座に向上させ、必然的に生じ得る将来の潜在的なディスクバランシング(とそのインパクト)を最小限に抑えることができます。
Nutanixでの結果:
1. 即効性のあるパフォーマンスの向上
2. 即時およびインラインの(プロアクティブな)クラスタバランシング
3. 有効化な/利用可能なキャパシティの即時の増加
上記の結果は、以下によって実現されます:
- 標準の VMDK、vDisks を使用した仮想マシン
- 一般利用可能なAOSの現行リリース
- 100%デフォルトのNutanix構成
- ADSFの高度なチューニングや設定が不要
- ESXiの高度なチューニング・設定が不要(ハイパーバイザーの依存性は100%なし)
次回以降に行われる「curator」スキャン(Curatorはクラスタ内のバックグラウンド操作を管理します)の間に、プロセスはクラスタの不均衡を検出し、自動化されたきめ細かいディスクバランシングタスクを処理します。
Curatorの使用率差分のしきい値は15%(以下に示す「gflag」)であり、バックグラウンドでのバランシング操作を開始するまで、ある程度の不均衡を許容します。
–curator_max_balanced_usage_spread=15
DEFAULT SETTING IN AOS FOR USAGE USAGE SPREAD.ADSFはパフォーマンスと容量利用率の両方に基づいて新規の書き込みをリアルタイムでバランシングしているため、入ってくる書き込み(クラスタのワークロード)が多ければ多いほど、クラスタはより早くバランスの取れた状態になります。
インテリジェントでダイナミックな書き込みレプリカの配置を行う完全に自動化されたプロセスのおかげで、将来の潜在的なディスクバランシングの影響を低減できるのです。
インテリジェンスはそれだけに留まりません。curatorはディスクバランシング(データの移動)のためのダイナミックなしきい値を持っており、curatorのスキャンごとに最小20GBから最大100GBのデータを移動します。これにより、ディスクバランシングにおける影響を最小限に抑えつつ、クラスタを健全な状態に維持することができます。
–curator_disk_balancing_linear_scaling_min_max_mb=20480,102400
DYNAMIC DISK BALANCING THRESHOLD IN AOS結果4:ディスクバランシングは4MB(エクステントグループ)の粒度で実行され(255GBオブジェクトごとではない)、クラスタのキャパシティ利用率に関係なく自動的に管理され、キャパシティ管理の問題が発生する可能性を最小化します。
Nutanix ADSFは、インテリジェントな(書き込み)レプリカ配置と完全に自動化されたディスクバランシング機能を備えており、異なるモデルで構成されるクラスタを単に「サポートする」だけではなく、ユーザーにとって現実的で信頼性の高い選択肢にします。
それでは、ここまで学んできたことをまとめてみましょう:
| 対応機能 | Nutanix | VMware vSAN |
| 異なるモデルのノード間のストレージレイヤーを効率的に活用するための管理者の介入は不要 |
|
|
| 新しいノードのキャパシティは、既存のVMでもすぐに有効化/利用可能 |
|
|
| 利用率に基づく新規ノードへのキャパシティのインラインバランシング |
|
|
| パフォーマンスに基づくインラインバランシング |
|
|
| 完全自動化されたきめ細かい粒度(4MB)でのポストプロセスバランシング |
|
|

* vSANはどのストレージデバイスでも利用率80%以上で自動的にバランスを取りますが、大きなオブジェクト(最大255GB)単位で行われます。
結果的に、VMwareは、私が強調した問題を認識しており、これらの理由からvSAN 6.7の計画と導入ガイドで次のように推奨していると考えています:
vSANは、(モデルが)統一された構成のホストで最も効果的に動作します。
異なるモデル構成のホストを使用するとvSANクラスタでは以下のような欠点があります:
* vSANは各ホストに同じ数のコンポーネントを保存しないため、ストレージパフォーマンスの見通しが低下する
* 異なる保守手順を踏む必要がある
* クラスタ内のキャッシュデバイスのサイズが小さい、または異なるタイプのキャッシュデバイスを持つホストでパフォーマンスが低下する引用: HTTPS://DOCS.VMWARE.COM/EN/VMWARE-VSPHERE/6.7/VSAN-673-PLANNING-DEPLOYMENT-GUIDE.PDF
vSANの状況を改善するために何かできることはありますか?
キャパシティ管理とパフォーマンスの課題のいくつかは、オブジェクト・ストライプあたりのディスクストライプ数をデフォルト値の1から最大で12まで増やすことにより軽減できる可能性があります。
このオプションについて、VMwareは次のように説明しています:
オブジェクトあたりのディスクストライプの数(一般にストライプ幅と呼ばれます)は、ストレージオブジェクトの各レプリカが分散される「capacity devices」の最小数を定義する設定です。vSANは、実際には、ポリシーで指定された数よりも多くのストライプを作成する場合があります。
とは言うものの、VMwareのドキュメントには次のようにも書かれています:
ただし、ストライピングによって緩和される可能性のあるパフォーマンスの問題が発生しない限り、ほとんどの場合、VMwareはストライピングをデフォルト値の1のままにしておくことを推奨します。
このドキュメントでは、ストライプ幅 - サイジングの考慮事項についてさらに詳しく説明しています:
ストライプ幅に関しては、2つの主要なサイジング上の考慮事項があります。
これらの考慮事項の1つめは、要求されたストライプ幅に対応可能な十分な物理デバイスが各ホストやクラスタ全体にあるかどうか、特に"NumberOfFailuresToTolerate "値のに対応できるだけのデバイスがあるかどうかに注意が必要です。
考慮事項の2つめは、ストライプ幅に選択された値がかなりの数のコンポーネントを必要とした場合に、ホストコンポーネント数をどの程度消費するかです。(vSAN)6.0のオンディスク・フォーマットv2で、最大コンポーネント数が増加したことを考慮すると、これはもはや大きな懸念事項ではありませんが、これらはいずれもvSAN設計の一部として考慮する必要があります。
最終的には、「Number Of Disk Stripes Per Object」を変更することで、キャパシティ管理や潜在的なパフォーマンスを向上させることはできるかもしれませんが、それだけではなく、複雑さやリスクを大幅に増加させることになるので、高度な設定が絶対的に必要な場合を除き、避けるべきだということです。
まとめ
Nutanix ADSFは、異なるモデルでのクラスタをサポートするだけでなく、その完全な分散型ストレージファブリックのおかげで、次のことを実現しています:
- vSANが抱える欠点をすべて回避
- ノードの種類やサイズに関係なく、クラスタ内で利用可能なすべてのハードウェアを最適利用する
- 新しいノードが追加されたときに、キャパシティの利用率とパフォーマンスに基づいて、新たに入ってくる書き込みI/Oを即座にインテリジェントにバランスさせる
- 完全に自動化されたディスクバランシングを提供
- 新しいノードのリソース(キャパシティ)が、管理者の介入なしに即座に利用可能
- 同一モデルのノードによるクラスタを維持するためのハードウェアの「サイロ」の構築を回避
- 潜在的に抱える困難なストレージキャパシティの管理及びパフォーマンスの課題に対処することなく、ジャストインタイム方式でのスケーリングが可能
- 複数世代のハードウェアを単一のクラスタに混在させ、パフォーマンス、回復力、投資回収率(ROI)を最大化
- デフォルトの設定から変更することなく、これらすべての結果を達成
次は、Write I/Oパスの比較 - Nutanix vs VMware vSAN を確認しましょう。