

本記事は2020年3月5日にJosh Odgers氏が投稿した記事の翻訳版です。
このシリーズでは、重複排除と圧縮、およびイレイジャーコーディングを使用する際に、Nutanixはより多くの使用可能な容量を提供し、より高い容量効率、柔軟性、回復力、およびパフォーマンスを提供することを学びました。
その後、ギアを切り替えて、異機種が混在したクラスタのサポートをカバーしました。これがHCIプラットフォームの拡張能力にいかに重要であるか、また、ツギハギやサイロを作らずに、強力なROIを実現できることを学びました。
次に、書き込み操作のためのI/Oパスを取り上げ、クラスタ内のVMの現在の位置とパフォーマンス/容量利用率に基づいてインテリジェントにデータを配置するNutanix独自のデータローカリティの多くの強みを解説しました。最適な書き込みレプリカの配置により、その後の読み込みI/O操作はNutanix ADSFでは主にローカルで提供されることが保証されます。これは(従来のSANのように)主にリモートで読み込みを提供するvSANとは対照的です。
また、Nutanixは、はるかに簡単で優れたストレージの拡張性を提供しているため、ドライブの故障による影響が大幅に軽減されることがわかりました。
今回は、回復力という重要なトピックをとりあげます。それぞれのプラットフォームがどのようにして様々な ノード障害シナリオに対処し、回復するかについて説明します。反論を避けるために、前回の記事でドライブの障害を取り上げたときと同様、DellEMCの圧倒的に人気の高いオールフラッシュのハードウェア構成であるVxRAIL Eシリーズを使用します。
注:使用されているコモディティなハードウェアは、この記事で提供されている例で、vSANやNutanix ADFS用のSWの動作という観点では、違いはもたらしません。しかし、フラッシュデバイスの量は、本記事で取り上げている、2つの製品間の違いについて、劇的な影響を与えます。
例1: ホストが応答しない/障害になった
vSAN ホストが応答しない場合、VMware のドキュメントには以下のようにプロセスが記述されています:
"ホストの障害または再起動によりホストが応答しなくなった場合、vSANは、クラスタ内の他の場所にあるホスト上にコンポーネントを再構築する前に、ホストの回復を待ちます。"
VMwareは、vSANがデータを再構築する前に発生するプロセスを説明しています:
"ホストが 60 分以内にクラスタに再参加しない場合、vSAN は、クラスタ内の他のホストのいくつかがアクセスできないホスト上のオブジェクトのキャッシュ、スペース、および配置ルールの要件を満たすことができるかどうかを検討します。こうしたホストが利用可能な場合、vSAN はリカバリ プロセスを開始します。
60 分後にホストがクラスターに再参加し、リカバリが開始された場合、vSAN はリカバリを継続するか、リカバリを停止して元のコンポーネントを再同期するかを評価します。"
別のVMwareの記事では、この挙動がはっきりと示されています:
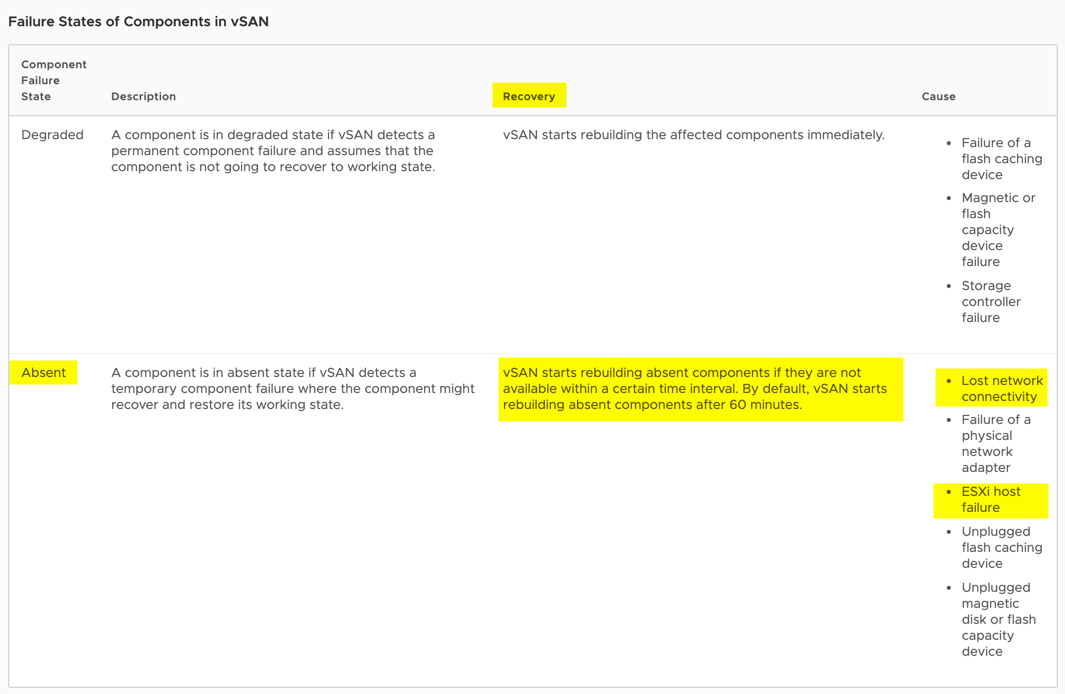
これは、障害が発生したノード上のオブジェクトに格納されているデータが利用できないことを意味し、vSANクラスタ内の単一ドライブの障害が発生するとデータロストが発生する可能性があることを意味します。クラスタが重複排除と圧縮を使用している場合、リスクは大幅に増加します。1台のドライブに障害が発生するとディスクグループ全体のデータ損失が発生するためです。
このリスクは、60分の待機時間が経過し、リビルド作業が完了するまで続きます。
再構築は、"Virtual SAN Object Health "を参照して "Rebuild Objects Immediately "オプションを選択することで、タイマーが60分経過する前に管理者が手動で開始することができます。
一方、Nutanixでは、ノードが応答しない場合には直ちに(1分未満)再構築の操作が開始されます。ノードがオンラインに戻った場合には、設定されたレジリエンシー・ファクター(Resiliency Factor)の係数(2または3)よりも多くのコピーを持つデータは、次のキュレーター(Curator)スキャンの間に自動的に削除される対象としてマークされます。(キュレーターは完全に自動化されたバックグラウンド機能で、クラスタを最適な状態に保つのに役立ちます)
これは、Nutanixの顧客のデータ再構築が、vSANの60分の待機時間が経過する前に完全に完了する可能性が高いことを意味します。
注:vSAN の 60 分間の待機時間は手動で変更できます。この比較では両製品のデフォルト設定に焦点を当てています。
例2: リビルドのための基礎となるストレージアーキテクチャ
vSAN は、ソースノード上のオブジェクトをホストするキャパシティドライブから、クラスタ内の他のノード上のキャッシュドライブ(ディスクグループごとに1台)のみに対してオブジェクト(最大255GBまで)をリストアします。
VxRAIL E シリーズでは、全てのドライブはオールフラッシュで構成されているため、リビルド操作では主に 2 台の SSD(キャッシュドライブ1本 x ディスクグループ2つ)が使用されます。ディスクグループごとの残り 4 台の SSD(合計 8 台)はリビルドに間接的に使用されることになります。
これは、DellEMCの圧倒的に人気の高いオールフラッシュハードウェア構成を使用しているお客様にとって、vSAN/VxRAILは主にリビルドに物理ドライブの20%しか使用していないことを意味します!
これは、vSANがクラスタ内の利用可能なハードウェアを最大限に活用できていないことを意味します:
- 信頼性の回復するのにより多くの時間がかかる
- データがリスクに晒される時間が長くなる(構成されたFTTに準拠していない)
- vSANは800GBに制限されている書き込みキャッシュドライブを介してバルクデータを送信するため、パフォーマンスへの影響が大きくなる
- フラグメンテーション(使用できないキャパシティ)が発生しやすくなる
Nutanixでは、再構築は4MBのエクステントグループに基づいて実行され、クラスタ内のすべてのノードとドライブを使用して多対多型の手法で実行されます。
VxRAIL E-Seriesと同等のハードウェアプラットフォーム基盤で、同じオールフラッシュの構成を使用した場合、Nutanixリビルド操作はクラスタ内のすべてのノードですべてのSSDを使用します。VxRAIL E-Seriesの構成を使用するこの例では、Nutanix ADSFはノードごとに10台のすべてのSSDを使用します。加えて、こうすることによって、2つのキャッシュドライブから8つのキャパシティドライブにデータをドレインする必要もなくなります。
これは、Nutanix ADSFが再構築のために5倍の利用可能な物理ドライブを使用することを意味します。
これが可能になるのは、Nutanixがディスクグループの概念に制約を受けず、クラスタ内のすべてのドライブが単一のストレージプールを形成するためです。
Nutanix ADSFはまた、クラスタ内の利用可能な容量の断片化を避け、プロセス全体のパフォーマンスを最適化するために、クラスタ全体で再構築されるデータを動的にバランスさせます(すべての書き込みIOと同様の挙動です)。
再構築データは"Oplog" (永続的な書込みバッファ領域)ではなく、エクステントストアに直接書き込まれます。再構築データは大きなシーケンシャルIOなので、ランダムな書込みのためのバッファであるOplogを経由するメリットがないためです。
これにより、vSANで直面した、キャッシュから再構築データをドレインしなければならないという問題を回避できます。
一例として、Nutanixがノード障害からどれだけ速く再構築できるかについては、以下の投稿をチェックしてみてください:
例3: ホストが応答を停止したときの書込みI/Oの整合性
vSANでは、再構築操作を開始する前の60分の待機時間の間、および再構築操作が完了するまでの間、新しい書き込みI/Oは、設定されたFTT(Failures to Tolerate)ポリシーで保護されることが保証されません。
Nutanixでは、クラスタの状態に関係なく、全ての新規の書き込みは、設定されたレジリエンシーファクター(RF2またはRF3)が遵守されるまで、ゲストにack(動作完了応答)を返しません。
これは全てのストレージが最低限として備えているべき重要的な機能です。永続的なメディアにデータの冗長性が担保された状態がコミットされるまで、書き込みに対してackを返してはなりません。vSAN では、この実用レベルのストレージ製品の必須要件が守られていません。
私のNutanixの回復力シリーズのパート6- メンテナンスや障害時の書込みI/Oをチェックしてください。
例4:3ノードのクラスタでノードが故障した場合はどうなりますか?
vSANでは、十分な容量があってもデータが再構築されず、新たな書き込みがFTT1に対応できなくなってしまいます。
VMwareのドキュメントにはこう書かれています:
“vSAN は 2 ノードおよび 3 ノード構成を完全にサポートしていますが、これらの構成は 4 ノード以上の構成とは異なる動作をする可能性があります。特に、障害が発生した場合、クラスタ内の別のホストでコンポーネントを再構築して別の障害に備えるためのリソースがありません。また、2ノードおよび3ノード構成では、メンテナンス中にノードからすべてのデータを移行する方法がありません。
2ノードと3ノードの構成では、データの複製が2つとウィットネスが1つあり、これらはすべて異なるホストに存在しなければなりません。2ノードおよび3ノード構成では、1つの障害しか許容できません。このことの意味するところは、ノードに障害が発生した場合、vSANはコンポーネントを再構築することができず、耐障害性を求められる新しいVMをプロビジョニングすることもできないということです。障害が発生した後、障害が発生したコンポーネントが復元されるまで、仮想マシンオブジェクトを再度保護することはできません。
設計上の判断: 最大の可用性を実現するために、vSANクラスタを設計する際には4台以上のノードを検討しましょう"
参照: HTTPS://STORAGEHUB.VMWARE.COM/T/VMWARE-R-VSAN-TM-DESIGN-AND-SIZING-GUIDE-2/3-NODE-CONFIGURATIONS-1/
Nutanixでは、十分な容量があればデータは再構築されます。これにより、3ノードクラスタはノード障害を許容し、再構築し、データを失うことなくその後のドライブ障害をサポートすることができます。実際には、後続のドライブ障害の後、クラスタは再び再構築されてRF2に準拠し、十分な容量があれば別のドライブ障害にも耐えられるようになります。
Nutanixはまた、ノード障害に見舞われた3ノードクラスタのようにクラスタがデグレードされた状態にある場合でも、すべての新規書き込みに対してRF2を維持します。
まとめ
今回の記事では、以下のNutanixのアーキテクチャをとりあげています:
- リビルド時にはクラスタ内で利用可能なすべてのハードウェアを適切に使用します
- 要求されているレジリエンシー・ファクター(RF)をより速く回復します
- データのリスクにさらされる時間が短くなります
- パフォーマンスへの影響が少ないです。なぜなら
- すべてのドライブに操作が分散されている
- キャッシュドライブからキャパシティドライブへデータをドレインすることを避けている
- 再構築は、潜在的なディスクバランシングの問題を最小限に抑えます。再構築中に最も適切な場所にデータを配置して、ポストプロセスでのディスクバランシングを回避するためです
- Nutanixの再構築のオペレーションは直ちに開始されます(1分未満)
- リビルド操作では、実装されている全ての物理SSDを使用します。
- Nutanixは、「キャッシュ」ドライブを介して再構築データの書き込みを強制されないため、後続のバックエンドIOを回避できます
- Nutanixは、すべてのノード/ホストの障害シナリオにおいて、常に書き込みI/Oの整合性を維持します
- Nutanixは、構成されたレジリエンシー・ファクターを維持するためのノードが不足しており、クラスタの状態がデグレードしている場合でも、データの再構築を継続します。
- vSAN 3ノードクラスタでは、1ノードの損失後にデータの再構築や整合性の維持ができません。
次回はストレージのアップグレードを比較します。