Hi,
I’m currently configuring synchronous replication (manual failover, no Witness VM yet) between two AHV clusters managed by Prism Central 7.5.0.5 (each cluster has it’s own PC).
Since there is no Witness deployed, this is not Metro Availability, but a synchronous Protection Policy with manual failover. As soon as I have the Witness VM I will test the Metro Availability feature.
Current setup
-
Created a container named
Metro_CPD1on both clusters. -
Created 3 test VMs on Cluster1 and placed them in the
Metro_CPD1container. -
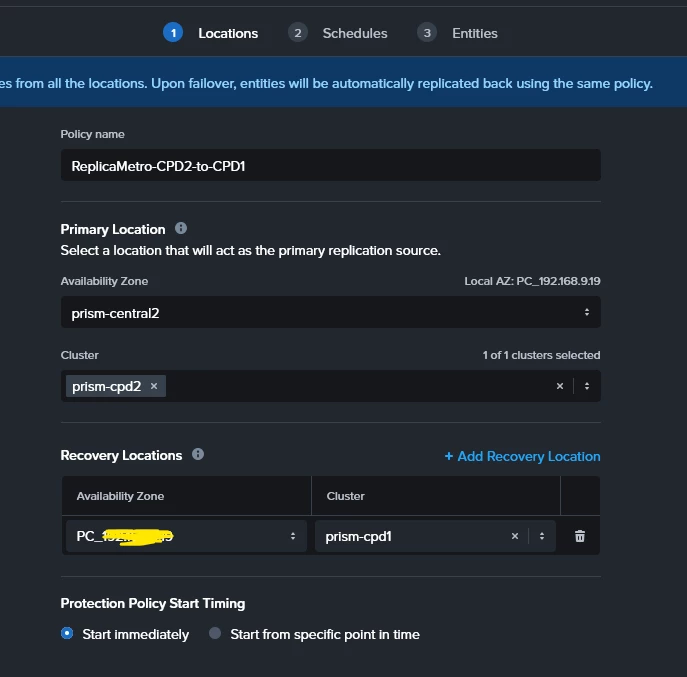
From PC1 I’ve created a Synchronous Protection Policy (
ReplicaMetro-CPD1-to-CPD2) with manual failover.

-
From PC1 I’ve created a Recovery Plan (
Recovery-metro-replica1) :-
Primary location: Cluster1
-
Recovery location: Cluster2
-
Execution mode: Manual
-
-
Added the 3 VMs to the Recovery Sequence.
-
Configured Network Mappings (Prod LAN and Test LAN with IP pools).

-
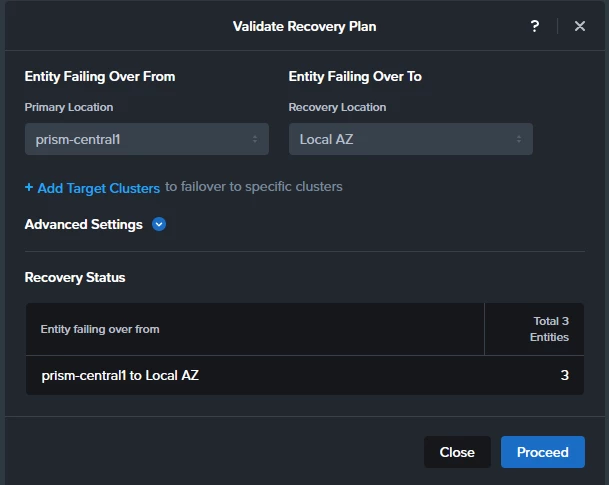
After creating the Recovery plan I do a “Validate” and it completes successfully on both sites
After some time (hours) on both PCs, under Recovery Points, I can see the Test VMs and their corresponding recovery points. So this suggests me that synchronous replication is working and checkpoints exist on both sides.

Problem
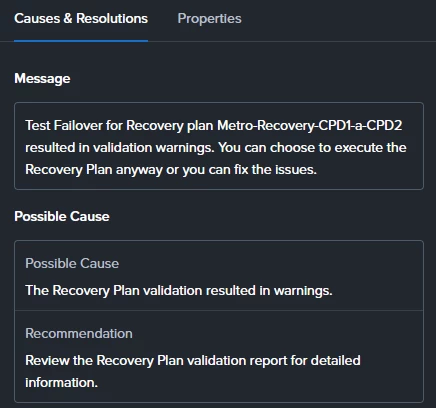
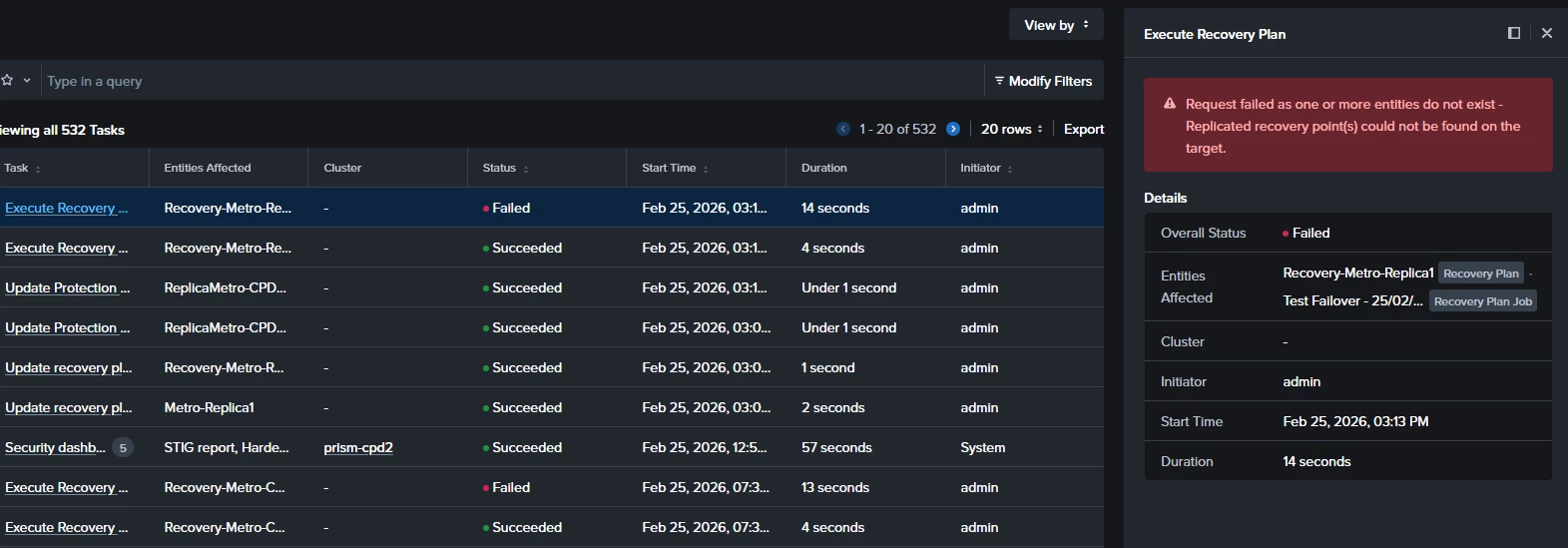
When I run a Test Failover from the secondary site, the execution starts but fails around the starting point with the following error:
"Request failed as one or more entities do not exist - Replicated recovery point(s) could not be found on the target."
Since recovery points are visible on both sides, I’m unsure why the Recovery Plan cannot locate them during the test execution.
Questions
-
A part of creating two containers with the same name on both clusters, do I have to “pair” them in some way?
-
Is there any specific requirement for Recovery Plans when using synchronous Protection Policies (without Metro container)?
-
Is there any known delay or additional step required before recovery points become usable for test failover?
Any guidance would be appreciated.
Thanks!!!