

Cloud-based disaster recovery with Nutanix MST (Multi-cloud Snapshot Technology) gives organizations a cost-effective way to replicate VM snapshots to object storage targets like AWS S3, Azure Blob, or Nutanix Objects and recover workloads when it matters most. Object storage is purpose-built for durability and geographic distribution, which makes it an ideal replication target. The trade-off has always been recovery speed: pulling data back from object storage to the AOS cluster is slower than reading from local NVMe or SAN-backed storage, and for large workloads that gap translated into hours of hydration time before a recovered VM could power on. For latency-sensitive workloads including clinical applications, financial systems, and operational databases, that recovery window was the one remaining challenge to address.
Nutanix Instant Restore changes the equation for MST-protected workloads. Now generally available in AOS and Prism Central 7.5.1, it decouples recovery from object storage hydration and lets workloads come back online in minutes rather than hours.
The problem with waiting for full hydration
MST snapshots stored in object storage (AWS S3, Azure Blob, or Nutanix Objects) are durable, cost-effective, and geographically distributed. But object storage is not block storage. When a VM disk read hits an object store, you are looking at single-digit millisecond latencies at best, compared to microsecond-range latencies from local NVMe or SAN-backed storage. That gap is invisible during normal operations but catastrophic during a failover when the AOS cluster has to pull gigabytes or terabytes of VM data before workloads can run.
Before Instant Restore, every MST recovery workflow triggered by an unplanned failover, a test failover, or an out-of-band restore forced teams to wait through that full object storage hydration window before the VM or volume group could be used. When RTO targets are measured in minutes, a multi-hour hydration queue driven by object storage throughput limits is a compliance and operational problem, not just an inconvenience.
How Instant Restore works
The key insight is that VMs need their metadata to start, not all their data. Instant Restore splits the recovery process into two phases:
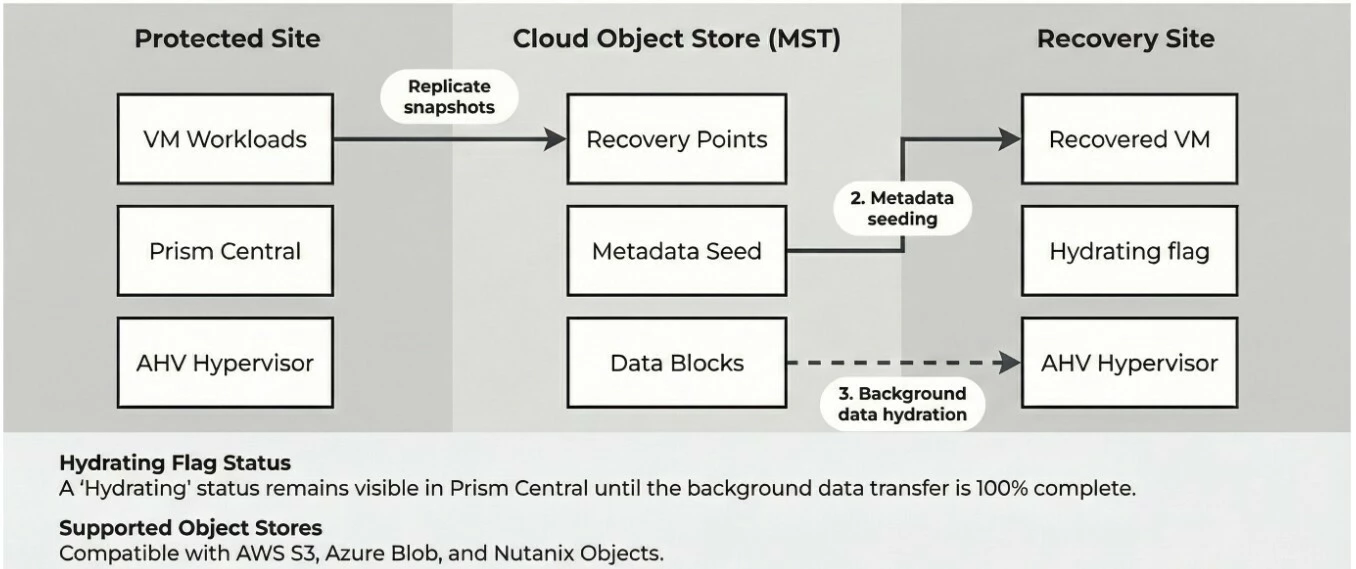
Phase 1: Metadata seeding. As soon as the metadata for the recovery point is available on the AOS cluster, Prism Central restores and powers on the VM. This happens in seconds to minutes, not hours.
Phase 2: Background hydration. Full data replication from cloud storage continues in the background. Any read requests for blocks not yet local are served directly from the originating object store, transparently. The VM is live and usable throughout.
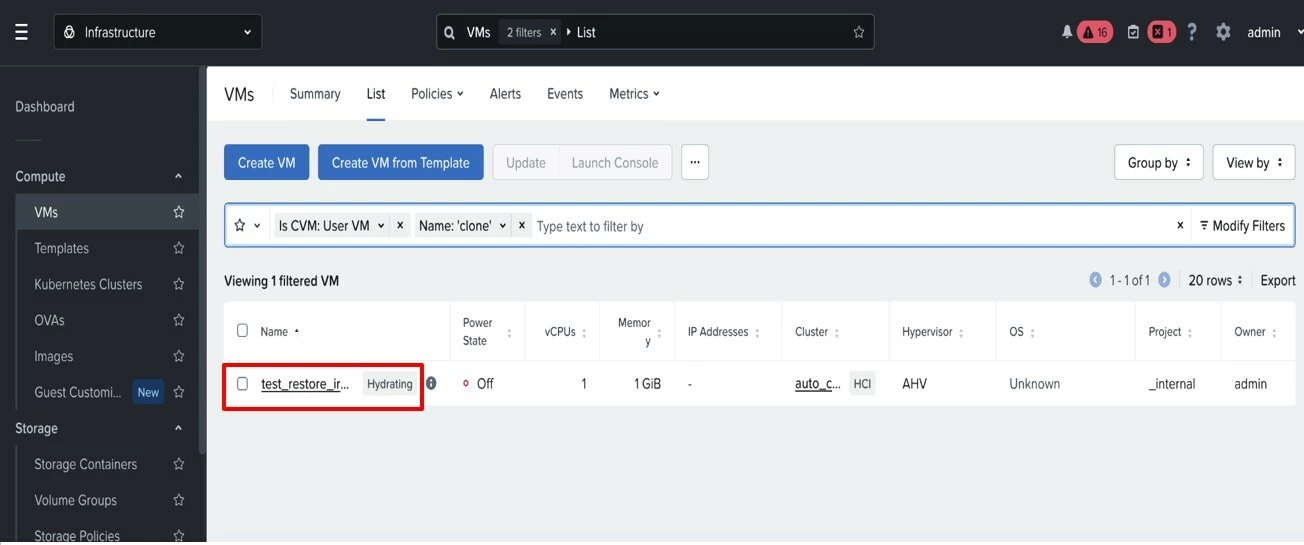
In Prism Central, recovered VMs and volume groups display a Hydrating flag alongside a real-time counter of remaining bytes so your team always knows where they stand. Once hydration completes, the flag clears and the entity operates entirely from local storage.
What to know before you deploy
Instant Restore requires AOS and Prism Central at version 7.5.1. There are a few important constraints to plan around. While background hydration is in progress, the recovered entity cannot be snapshot, cloned, or replicated to a secondary object store. Multi-site protection policies that include the originating object store as a target are also not supported until hydration completes.
See it live at .NEXT in Chicago
If you want to see how Instant Restore fits into a broader hybrid multicloud continuity strategy, join us at Nutanix .NEXT in Chicago on April 7th for the session Hybrid Multicloud Without Chaos: Continuity, Control, Consistency, running from 3:30 PM to 5:00 PM. We will cover how to architect for continuity across on-premises and cloud environments without giving up operational control.
Also on April 8th from 3:30 PM to 4:30 PM, catch the session DR Innovation in the Public Cloud with Nutanix Cloud Clusters (NC2), a deeper dive into how NC2 extends your on-premises DR strategy into AWS and Azure without rebuilding your operational model.
Instant Restore is one piece of that puzzle. The bigger picture is building infrastructure that lets you recover on your terms: fast, compliant, and without surprises.
