Hi
I'm using 6.5.2 LTS.
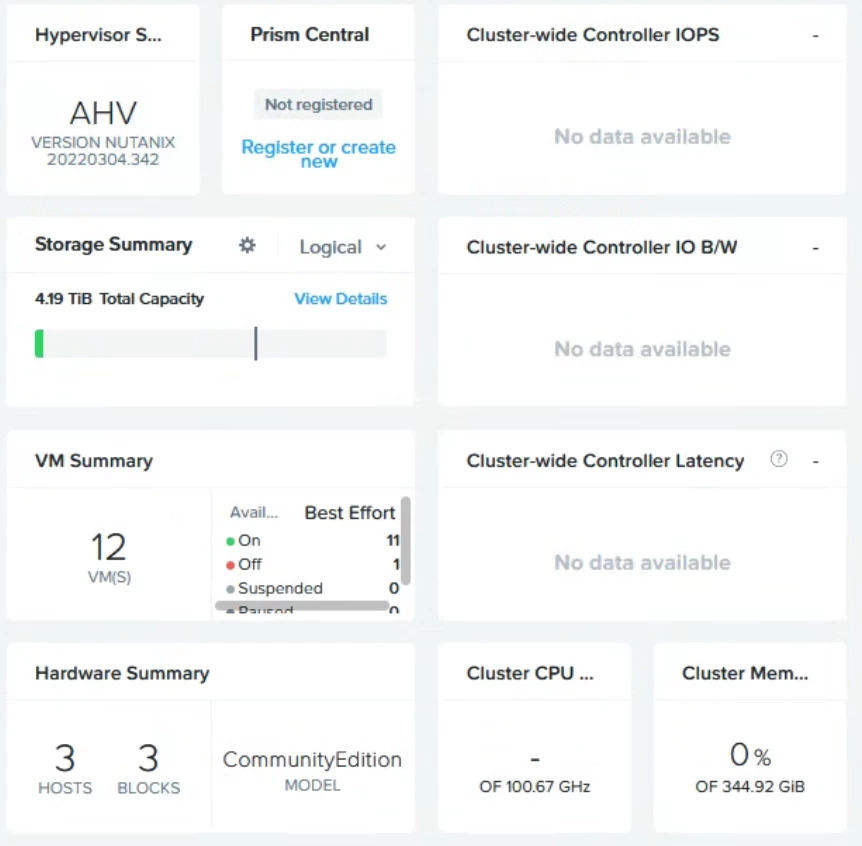
I have a cluster consisting of three machines.As you can see in the attached screenshot, on the Prism Element home screen, each resource in the cluster is displayed as "not available.
"The Storage Summary also shows values that differ from actual usage.
I've configured SNMP in Prism Element, and when I use snmpwalk to retrieve values such as hypervisorRxBytes from the monitoring server, the values always show the same.
If you know the cause, please let me know.
Thank you in advance.