
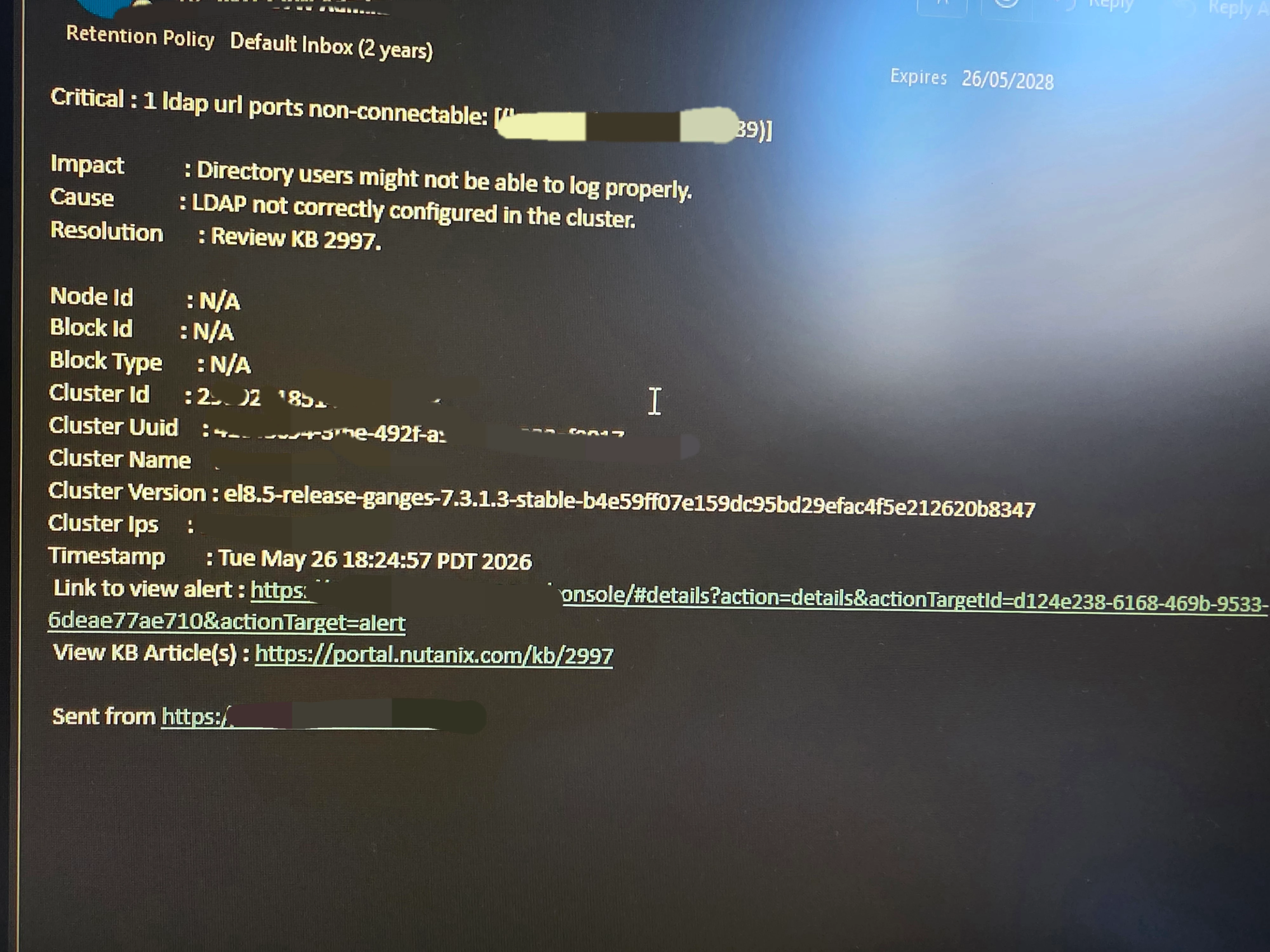
Hola,
Tengo un Prism Central con esta alerta.
Como veis parece que no contacta con ldap, en ralidad lo que pasa es que a veces se va a buscar un servidor con alta latencia en vez de coger el que tiene al lado. Tengo otros Prism en misma localización y misma configuración y no tienen este problema. El Kb en mi caso no ha servido de mucho. Esta alerta la tuve en otro cluster, actualicé ncc y no volvio a salir. En este cluster no he tenido la misma suerte. Alguna idea? Gracias

