

本記事は2020年3月27日にGary Little氏が投稿した記事の翻訳版です。
原文はこちら。
データベースの統合率をどのように測定しますか?
- より多くのDBを統合することによってデータベース性能はどのように変化しますか?
- CVMの実行は利用可能なホストリソースにどのような影響を与えますか?
- クラスタの性能は理論的上の最大値の90%を達成できました。
- CVMのオーバーヘッドはこのワークロードの5%でした。
テスト環境設定
評価の目的は、クラスタにデータベースワークロードを徐々に追加していくことでDBのパフォーマンスがどのように影響を受けるかを確認することでした。2つ目の目的として、データベースサーバーと同じホストで仮想ストレージコントローラーを動かすことによる負荷を測定します。Postgresデータベースでpgbenchワークロードを用いて1秒当たりの合計トランザクションを測ります。
クラスタ構成
- 4ノードのNutanixクラスタにて、各ホストはソケットあたり20コアで構成された2つのXeon CPUを備えています
データベース構成
各データベースは下記スペックやソフトウェアで構成します
- Postgres 9.3
- Ubuntu Linux
- 4 vCPU
- 8GBのメモリ
- pgbenchベンチマークは、”Simple”のクエリセットを実行します
データベースのサイズはメモリ内に収まるように調整します。IOではなくCPU/メモリのテストです。
テスト手順
1台のホスト上の1つのデータベースよりテストを行います。合せて40データベースになるまでクラスター上にデータベースを追加します。40のデータベースではそれぞれ4つのvCPUとCPUバウンドのワークロードで構成され、クラスター上で160個のCPUコアをすべて利用します。
データベースはホストのDRAMメモリに収まるように構成しており、ベンチマークはCPUバウンドであり、可能な限り高速に実行されます。
結果
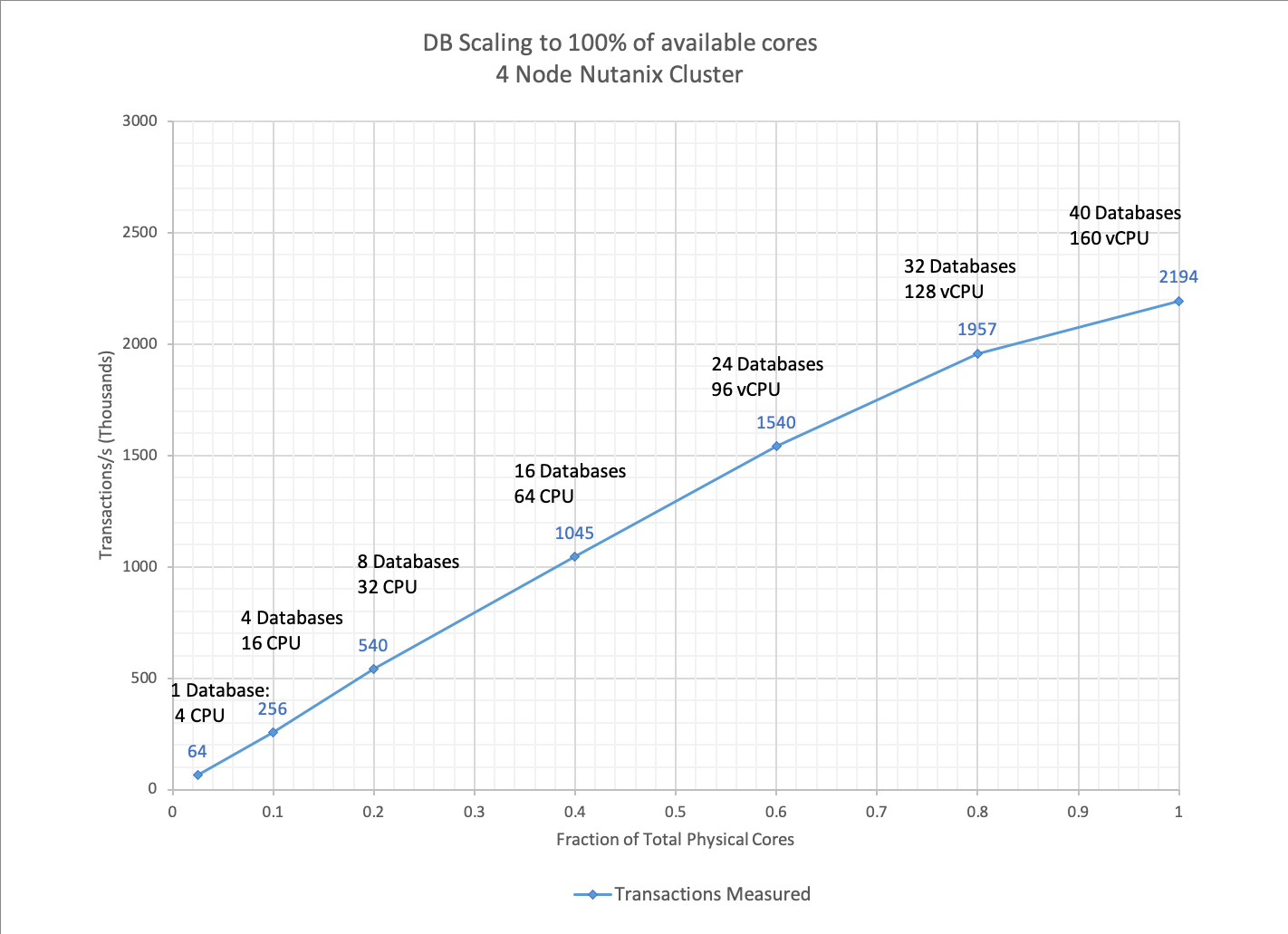
下記より4ノードクラスタ上で1-40台のデータベースを実行した際の測定結果をご覧ください。
40台のデータベースでCPUコアが飽和状態になるまで、パフォーマンスは4から160 CPUまでほぼ直線的に上昇し、明らかなボトルネックはありません。
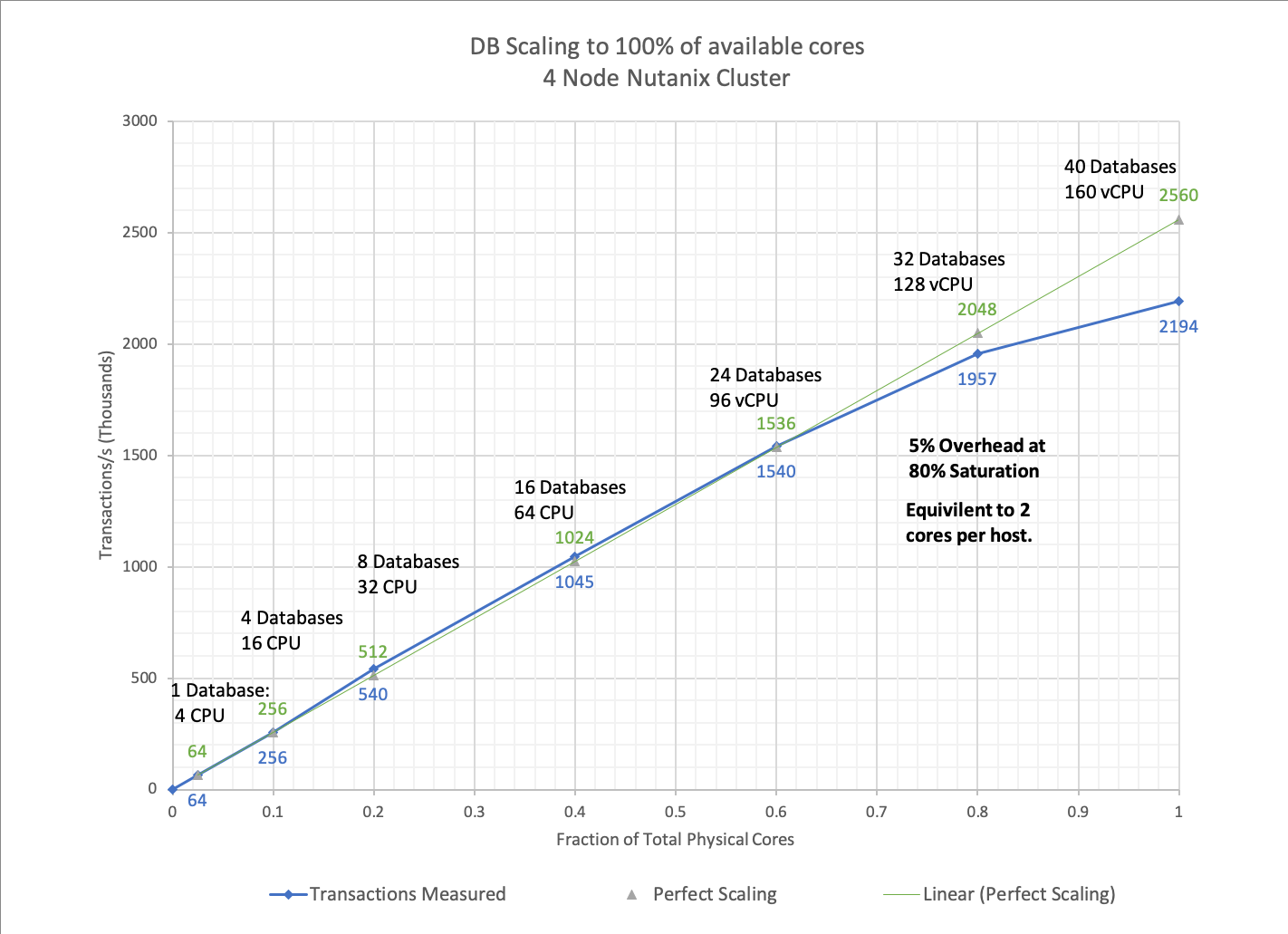
完全なスケーリング 対 実際のスケーリング
それでは、クラスタにおける拡張性について上のグラフから何がわかるでしょう? 結果は良い? 悪い? それともこんなもんでしょうか? システムがどの程度拡張できたかを理解するには、つまりシステムに追加された新たなデータベースで同じ性能を提供し続けるために、測定結果を「理想的なスケーリングが行えるプラットフォーム」において期待される数値と比較します。
下表の「理想的なスケーリング」と書かれた列は、1 台のデータベース上で測定された数値を実行中のデータベース数にかけて算出してます。そうすることで、ワークロードがシステムにおいて飽和し始めるにつれて、計測値と「理想的な」値が乖離することがわかります。これは予測されることであり、主にユニバーサルスケーラビリティ法(USL)で説明されている効果によるものです。
最大負荷 (40コアすべてビジー) では、「完全な」値が2560に対して、測定値は2194です。したがって、このシステムは理論上の最大値に対して85%を超えてスケーリングしており、とてもよい性能といえます。
| DB数 | 総コア数 | 総コアの利用段階 | 実測 トランザクション/秒 (K) | 理想的な拡張 トランザクション/秒 (K) |
| 1DB | 4 | 0.025 | 64 | 64 |
| 4DB | 16 | 0.1 | 256 | 256 |
| 8DB | 32 | 0.2 | 540 | 512 |
| 16DB | 64 | 0.4 | 1045 | 1024 |
| 24DB | 96 | 0.6 | 1540 | 1536 |
| 32DB | 128 | 0.8 | 1957 | 2048 |
| 40DB | 160 | 1 | 2194 | 2560 |
ストレージCVMオーバヘッドの測定
ワークロードを拡張するにつれて、CPU負荷が理想的なスケーリングから乖離してくることがわかります。このケースでは、DBワークロードそれぞれが完全に独立していても、共有のハイパーバイザーやCPUのスケジューラのもとでワークロードが実行される点が関係することが、USLからも理解できます。
更に起動してサービスを続けているCVMを考慮する必要があります。
オーバーヘッドを計算するために、性能が飽和するコアの割合を80%とすることにしました。それより低いと測定値が完全なスケーリング値に等しく、リソース競合がないことを示しています。80%を超えると共有リソースのために競合や干渉を管理するために性能が低下していくことがわかります。
80%の飽和状態では、「理想的な」値と「測定」値の差はおよそ5%です。測定値 (1957) / 完全な値 (2048) = 0.95
したがって160コアの場合、CVMでは160コアの5% (クラスタ全体で8コア、ホストあたり2コア) 消費すると予想できますが、実際にはこの構成環境ではCVMは16 vCPUで設定されています。
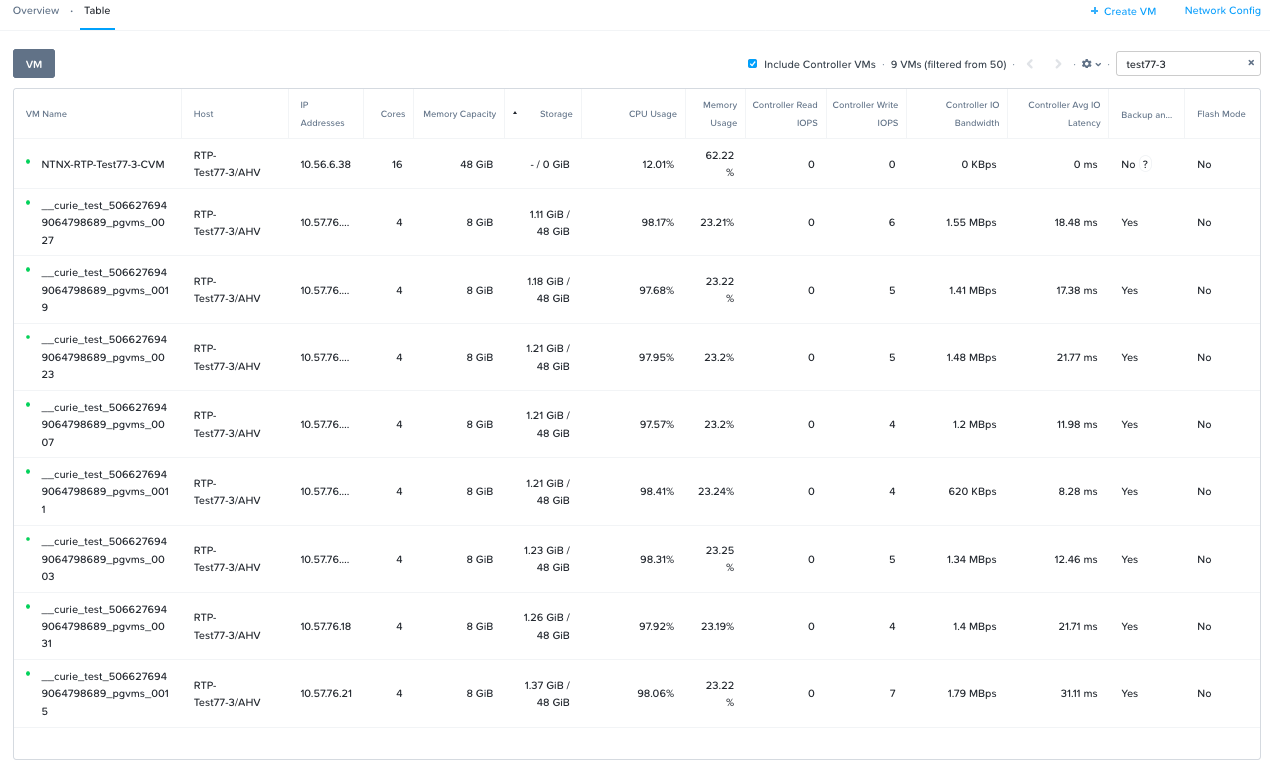
Prism上では、CVMは16 vCPUと設定してますが、その割り当てられたCPUに対して(平均で)12%(約2vCPU/コア) しか使われてないことが確認できます。
結論
- スケーリングは合計CPU容量の80%まで (理想的に)線形に拡張しており、主に USL で説明される効果によるものです。
- 実際のCVM利用状況はおおよそ2 vCPUであり、この例ではほとんどがCPUバウンドのワークロードです。
- AHVハイパーバイザーは、CVMよりデータベースワークロードを優先的に処理しています。