
本記事はHarshit Agarwal氏 と Samuel Gaver氏による2021年12月9日のnutanix.devへの投稿の翻訳版です。
原文はこちら。

はじめに
Nutanixはハイパーコンバージドプラットフォームですが、その全てのサービス(ストレージサービスを含む)はコントローラーVM (CVM)と呼ばれる特殊な仮想マシン(VM)上で稼働しています。このCVMは現在カーネルバージョン3.10のCentOS Linuxディストリビューションで稼働しています。残念なことにこのカーネルのバージョンは結構古いもので、いくつかの課題を抱えており、このことが今回、Nutanixが新しいバージョンへとアップグレードをする動機となっています。
なぜアップグレードが必要か?
- バックポート作業の辛さを軽減する: バグやセキュリティ問題に出くわした場合、我々はより新しいバージョンのカーネルから、3.10.xへと変更をバックポートする必要がありました。これらのバックポートは大きく時間がかかるもので、開発者にとってはこうした変更が適用可能で、正しくポーティングされたのかを確認する必要のある大変な作業を必要とします。加えて、マニュアルでのバックポート作業はQAチームにもそれぞれの変更をテストして検証するという大きな負担となっていました。
- 新たな機能のメリットを享受する : より新しいカーネルでは io_uringとBBR、我々のI/Oスタック内でのCPU効率と性能の改善が含まれており、より要件の高いワークロードを取り回す事ができるようになります。
- LTSサポートへの追従 : 3.10のサポートは2017年に終了しています。最近のLTSカーネルを利用することで我々はLinuxコミュニティのサポートを受けやすくなります、Linuxコミュニティでは必要なバグ修正がすべてバックポートされています。LTS系列へと合わせることで、マニュアルで修正を監視してそれらをバックポートするよりも、劇的な改善が見込まれます。
- パフォーマンスの改善 : AMD Zen上での優れたコンピュート性能と ext4における高速コミットの2つが、新たなカーネルを利用することで我々が同じハードウェア上でもより優れたパフォーマンスを達成することに貢献するカーネルの改善点です。
問題はなにか?
作業を始めるにあたって我々は、最新のLTSバージョンのカーネルであるということから、5.10を選択しました。古い3.10のカーネルから新しい5.10のカーネルへ移行することは、大きなジャンプでCVM内の多くのサービス、特にパフォーマンスに影響を与えるサービスへと影響を与えることになります。パフォーマンスに関連しない殆どの問題はこの2つのバージョンのカーネルの振る舞いの違いに起因します。こうした変更のうちの1つはcgroupによるメモリの取り扱い方が異なるというものです。この取り扱い方の変更は、いくつかのサービスでメモリ不足エラーを引き起こし、これにより我々は、それぞれのサービスの制限について再確認する必要が出てきました。
以下のセクションでは、パフォーマンスに関連した問題の詳細について取り上げていきます。我々が遭遇したそれぞれの問題について取り上げ、続いて我々がどのようにそれを解消したのか ― 何がうまく行って、何がうまく行かなかったのかも含みます ― について補足していきます。
この記事のために得られたパフォーマンスの数値はテスト環境内でのものであるということを注意書きしておきます。これらの数字はテストの実施時にパフォーマンスが相対的にどう変化したかを示すためのもので、現実の環境で本稼働しているNutanixクラスタのパフォーマンスを示したものではありません。
問題その1: 全体的に低いランダムI/Oパフォーマンス
5.10のカーネルで作業を開始すると、ランダムI/Oのパフォーマンスが全体的に10%ほど劣化していることを確認しました。以下のテーブルは外部からのベンチマーク結果を示したものです。
| Test | Kernel Version 3.10 | Kernel Version 5.10 |
| rand_write (IOPS) | 38,196 | 35,106 |
| rand_read (IOPS) | 44,876 | 48,621 |
テストにおける注意事項:
- テストツール: VDBench
- ブロックサイズ 8 KB
- ユーザーVM (UVM)のディスクあたり 1つの負荷I/O
- 8つのディスクを持つ8つのUVM = 合計 64 UVMディスク
検証環境
問題を理解するため、我々はこの性能低下を再現できる限りの変動要素を取り除くことにしました。最初に、CVMのローカルにおけるテストを、ハイパーバイザー内のI/Oパスに追加で組み込まれた複雑なものを取り除いた状態で実施しました。次に、I/Oコントローラー内に埋め込まれたパフォーマンステストツールを利用し、fioのようなツールを利用する際に出くわすプロセス間通信(IPC – interprocess communication)帯域への依存度を減らしました。最後に、ネットワーク関連のあらゆる問題を取り除くため、1ノードのみで構成されたクラスタで、レプリケーションファクタ 1 で実験を行いました。
Nutanixの分散ストレージはすべてのI/OをStargate と呼ばれるプロセスで管理しています。Stargateにはperf_testと呼ばれるビルトインのユーティリティがあり、これによって異なるストレージアクセスパターンとブロックサイズでI/Oを発生させることができます。perf_testユーティリティを利用してランダムとシーケンシャルの両方のワークロードを発生させ、パフォーマンス問題を複数回の試行に渡って確実に再現することができました。ランダムワークロードでは一貫してパフォーマンスの劣化が見られましたが、シーケンシャルワークロードでは若干の改善が確認されました。
このテストのためのハードウェアの構成はベーシックなオールフラッシュノードで、我々のお客様の環境において最も広く利用されているものです。我々は同等のクラスタを古いカーネル3.10で同じハードウェアスペックでも構築しました。 非常に多くの潜在的な要素を取り除いたおかげで、カーネルバージョンの3.10と5.10の間のパフォーマンスの差が明らかになり、我々は問題がカーネル内のどこかで発生していることが確認できました。
パフォーマンス問題をデバッグしている際、こうした問題を再現するための小さなテストを実施することは とても重要です。この再現性と一貫した構成によって問題についての理解を繰り返し、解決策に確信を持つことができるからです。
デバッグ
問題がStargateにあることがわかった後は、2つの角度からそれを見てみることにしました : ディスクI/Oが遅いのか、または Stargateが十分なCPUサイクルを得られていないのか、です。少しだけ解説すると、Stargateは非常に多くの計算能力を利用し、CVMのリソースの大半を消費するサービスです。つまり、CPUの利用に関するちょっとした変動要素が大規模なI/Oパフォーマンスへの変動を引き起こすのです。I/Oレイテンシを最小化するため、NutanixはStargateを含むデータサービスにリアルタイム(RT)スケジューリングを利用し、標準のCompletely Fair Scheduler(CFS – 訳注:完全に平等なスケジューラー)によって発生する、あらゆる意に反した遅延を排除しています。RTスケジューリングは、データサービスに対してバックグラウンドまたはメンテナンスなどの重要ではないサービスよりも高い優先順位を割り当てています。
ディスクI/Oについてのいくつかのベンチマークを実施しましたが、その結果はいずれのカーネルでも似たようなものでした。Disk stat内でも同様で特に目立つものはありませんでした。しかし、ここでStargateが5.10のカーネルでは3.10での際とは異なり、CPUを劇的に消費していないことを確認できました。Stargateの内部のstatsを利用しI/Oを発生させているスレッドについての深い情報を得ると、CPUの消費が2つのカーネル間のパフォーマンスの差に相関していることを確認できました。この発見によって我々はフォーカスをCPUへ、特にStargateが大きく依存しているRTスケジューリングへと移すことにしました。ハイパフォーマンスのデータサービスではRTスケジューリングとCPUの複数のコアについてのアフィニティを確立しており、残りのコアで実行されるバックグラウンドサービスによって性能を食いつぶされないようにしながら、拡張的にそれぞれのコアの性能を利用できるようにしています。
これらの2つのカーネルのバージョンにはスケジューラーについて、特にRT関連要素においては多くの変更がなされています。我々の目的は5.10のパフォーマンスを3.10のレベルまで持っていくことですので、我々は当該のスケジューラーにおけるコードの変更と、対応するスケジューリング機能のフラグの確認をはじめました。はじめに、我々は2つのカーネル間において以下の相違点と類似点を見つけました。
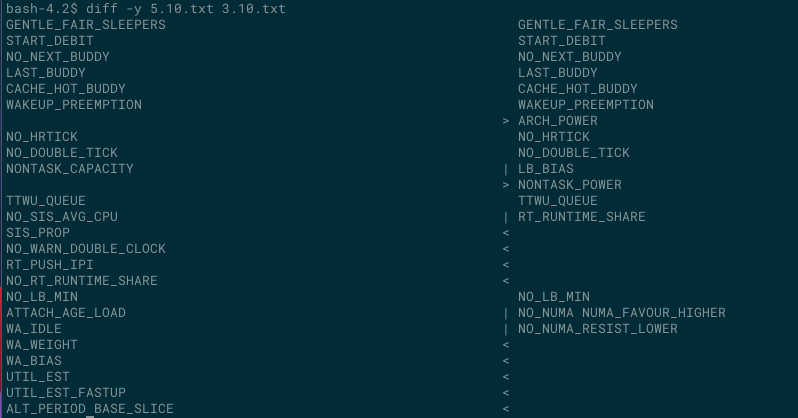
相違点
利用率推定(Utilization estimation)
UTIL_EST と UTIL_EST_FASTUP は3.10には存在しなかった2つのオプションになっています。スケジューラーのper-entity load tracking (PELT – エンティティごとの負荷追跡)モジュールではエンティティのスケジュールのための様々なメトリックの監視を行い、タスクの平均的な利用率を計算します。タスクの負荷貢献度は最も直近の利用率がほとんどの負荷に影響を及ぼすため、時を経るにつれて低下していきます。周期的なタスクの平均利用率は、実行中は期待される利用率が変わらなくても、タスクがスリープしている間に低下していくため、レジューム時には再びランプアップ(利用率を上げる)なければなりません。このランプアップのタスクは、要求されるCPUリソースを提供できていないにもかかわらずCPUが省電力状態に入ってしまうというDVFS (Dynamic Voltage and Frequency Scaling -電圧と周波数の動的なスケーリング)アーキテクチャにおける問題の1つです。 2つのオプションはこのランプアップによるペナルティを緩和するために役立つものです : 利用率の推定に指数荷重移動平均(EWMA - Exponentially Weighted Moving Average)を利用して更新を行うことで、CPU上で稼働しているエンティティの時間をキューから取り除くのです。
我々はDVFSに依存することはないので、我々はこれらのフラグをすべてオフにすることで、あらゆるオーバーヘッドと期待しないスケジューラーの振る舞いの変更を避けることができました。
Wake affinityメソッド(Wake affinity methods)
スケジューラー内のWake affinityメソッド(wake_affine_idle と wake_affine_weight)はタスクを稼働させられる最初のCPUを決定します。これらのメソッドにおいては、同じCPU上でキャッシュを共有させることを意図して、これから起動されるタスクを、起動元のタスクの近くへと配置する傾向があます。wa_idleオプションは、もしも以前使用していたCPUがアイドル状態で、かつキャッシュアフィニティがある場合、タスクを起動させたCPUから以前のCPUへと移行させることを指定するオプションです。このアプローチはキャッシュアフィニティよりも、アイドルなCPUを選ぶアプローチです。それと同じように、wa_weightオプションは、wa_idleによる戻し先となるアイドルなCPUのないワークロードを対象に、CPUスケジューリングの平均レイテンシを考慮します。
しかし、CVM上の割り込みリクエスト(IRQ – Interrupt Request)ハンドラーを含む、様々なパフォーマンスにとって重要なプロセスは、CPUに対するアフィニティを持っているため、このフラグを無効にしてしまうことで不必要な移行を抑制し、全体として優れたスループットを実現することができます。
割り込みを利用してRTタスクの移行をプッシュでトリガする
RT_PUSH_IPIが有効になっている場合、プロセッサー間割り込み(IPI – interprocessor interrupt)が過負荷のCPUへと送信され、プッシュ(push)操作が開始されます。もしも多くのRTタスクがCPUのうちの1つで待ち状態になっており、そしてそのCPUが他の優先順位の低いRTタスクをスケジュールしている場合、システムはプル(pull)ロジックを開始させ、他のCPUで優先順位の高いタスクが待ち状態になっていないか確認します。しかし、CPUのうちの1つがRTタスクによって過負荷状態で、複数のCPUがアイドルであった場合、複数のアイドルなCPUでプルが同時に開始されます。プル操作の一環として、これらのCPUは実行キューのロックを奪い合ってしまうのです。しかし、実際にはこれらのCPUのうち、一度には1つのCPUしかロックを取得することはできませんので、他のCPUは結局待たされてしまうことになります。
プッシュロジックは競合をへらすために設計されています。このロジックは最初の過負荷なCPUに対してIPIを1つ送信し、プッシュ可能なあらゆるタスクをプッシュします。その後、更にこのロジックは次に過負荷なCPUを探し出し、もとのCPUへとタスクをプッシュする可能性があります。IPIはすべてのCPUが過負荷で、もとのCPUがカバーできる以上の優先順位の高いタスクしかプッシュできない場合には停止されます。
このプッシュメカニズムはIPIを利用しており、IPIのレイテンシは 我々のシステムにとってはメリット以上のオーバーヘッドを生じさせます。このメカニズムのメリットは多くのコア数を抱えるシステムのRTプロセスで、こうしたコアの一部の中で限定的なアフィニティしかない場合により顕著になるはずです。
修正と結果
我々のシステムのパフォーマンスに影響を与える5つのスケジューラーの機能のフラグ (NO_RT_PUSH_IPI, NO_WA_IDLE, NO_WA_WEIGHT, NO_UTIL_EST, そして NO_UTIL_EST_FASTUP)を特定した後、それを無効にしました。これらのフラグを無効にした後、5.10のパフォーマンスは3.10のパフォーマンスと同等になりました。以下はその数値をまとめたものです :
| Test | Kernel Version 3.10 | Kernel Version 5.10 | Kernel Version 5.10 + Sched |
| rand_write (IOPS) | 38,196 | 35,106 | 38,593 |
| rand_read (IOPS) | 44,876 | 48,621 | 48,195 |
これらのスケジューラーの変更によって、パフォーマンスの劣化についての最初のハードルを越えることができました。ですが、これは最初のハードルに過ぎず、これだけではなかったのです。
問題その 2: 奇妙なレイテンシのスパイク
自動化されたテストでは見つけることのできないスポット的な異変を見つけることができるのが、パフォーマンステストを実施できる人材を抱えているメリットのうちの1つです。自らの手によるパフォーマンステストの最中に、さほど集中的ではないランダムreadをかけた際に、定期的なレイテンシのスパイクを発見しました。以前の実験と同じ検証機に、Stargateから直接ではなく、ユーザーVMからI/Oを発行しました。今回はI/Oジェネレーターとパフォーマンス計測ツール VDBenchから実際の環境を模したワークロードをかけました。ユーザーVM(UVM)内のVDBenchの出力に10秒ごとに100ミリ秒以上のスパイクが見られます。
以下のチャートは5.10(下)でのレイテンシのスパイクと比較のために3.10(上)のスムースなレイテンシのチャートです。
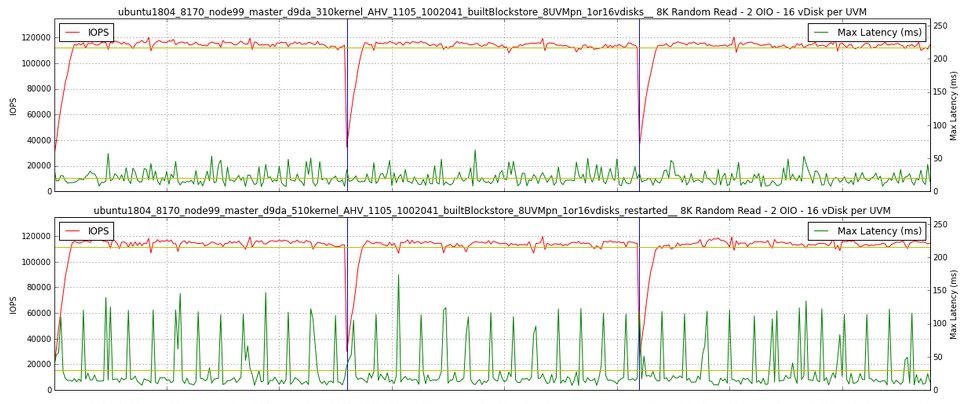
全体としての5.10でのランダムReadのレイテンシは低くなりますが、レイテンシの最大値の平均となるとかなり高いものとなります。この不審な挙動には大いに興味を惹かれました、そしてなぜそれが発生しているのかを考えなくてはなりません。
これらのレイテンシにおけるスパイクは、キューデプス(queue depth)が1の場合のI/Oテストを行っているときにのみ発生するということも考慮に値します。キューデプスが大きい場合のテストではシステムがより忙しくなり、レイテンシの平均値はもっと高いものになるため、レイテンシのスパイクはノイズによって埋もれてしまいます。
背景
次のセクションに進むためにCVMのレイアウトを確認しておきましょう。この議論をするためには特に、ハイパーバイザーネットワークスタックからCVM上のStargateプロセススタックへの流れを理解しておかねばなりません。

実験
こうした背景を頭に留めおきながら、この問題の根本原因を分析するために行った様々なことを列挙していきます:
- 最初の想定は、定期的に動作するプロセスやジョブがCPUまたはディスクの帯域を消費しているのではないかというもので、我々はCVM内のすべての必要不可欠ではないサービスを停止させました。しかし、スパイクが発生しました。
- 同じテストをESXiにおいても実施したところ、スパイクが発生しました。ESXi上でも再現するということは、レイテンシのスパイクはCVMのネットワークドライバーとは何ら関係ないということです。AHVとESXiでは異なるインゲストネットワークドライバーを利用しているからです。
- そこで、UVMとCVM間のパスの複雑性を取り除くためにStargateプロセス内(問題その1と類似した構成)でI/Oを生成するperf_testユーティリティを利用しました。レプリケーションファクタ1コンテナも利用し、こうしたWriteに紐づく他のCVMに対するあらゆるレプリケーションWriteとネットワークのレイテンシを回避しています。このテストではレイテンシのスパイクを再現させることはできませんでした、つまりこれは明らかにこれらのスパイクがStargateの外側のどこか、Stargateのバックグラウンドタスク以外で発生しているという証拠です。問題その1のセクションで確認してきたStargateのスケジューリングによって発生する問題でもないということです。
- 続いて我々は、StargateのI/O取り込み(I/O ingress)レイヤーをショートカットしました。イングレス(アドミッションコントロール)レイヤーを短絡することで、我々はすべてのStargateコードをデータパスから取り除き、ネットワークレイヤーだけについて検証することができます。この構成ではStargateはシンプルにWriteをacknowledge(完了確認応答)し、Readについてはゼロを返します。UVMからのVDBenchではまだレイテンシのスパイクが再現でき、Stargateの外側、そしておそらくはカーネル内に根本原因があるという我々の仮設が正しいことを更に確認できました。
- 最後に、tcpdumpとWireshark使って、最もレスポンスタイムが高い時点でフィルタリングを行い、レイテンシの高いパケットがハイパーバイザーのNICをT0 で出発して、CVMのNICにT0 + 90ミリ秒 で到着していることを確認しました。これにより、レイテンシはハイパーバイザーのNICから排出されたあとから、CVMのNICに流入するまでの間のどこかで発生していることがわかります。これほどの時間がかかることは非常に興味深いことです。CVMはUVMと同じホスト上にありますから、ハイパーバイザーのNICからCVMのNICへのパスは非常に高速であるべきです、というのも実質的にはメモリのコピーに過ぎないはずだからです。さらに言えば、tcpdump操作は非常に低レベルで実行されているため、tcpdumpが追跡できるよりも更に低いレイヤーでスパイクが発生しているに違いないということです。
ここまでで、問題がどこにあるのか明らかになりました。ハイパーバイザーには何ら変更を加えていませんから、そこでは何もするべきことはありません、それでは新たなCVMのカーネルのなにか特殊な部分であるはずです ― ですが 、それは何なのでしょうか?
SystemTapの脇道
我々が次に通った道は、脇道であることがわかりました。興味深く、将来的には他のバグに対して役に立つかもしれませんが、レイテンシのスパイクについてはこれが役立つことはありません。我々はネットワークレイヤーにフォーカスを当てていたので、パフォーマンス低下時のいくつかのFlameGraphsを生成して、その後はCloudFlareの方々による素晴らしいSystemTapスクリプトをいくつか利用し、特定のTCPカーネルコールを取得してそのレイテンシを見てみました。
残念なことに、このアプローチは結果として何かを生み出すことはありませんでした。ヒストグラムの結果は平坦なもので、我々の確認したレイテンシのスパイクとヒストグラム内のスパイクも相関があるものではありませんでした。この結果、我々はこの線でのデバッグを中断することにしました。
ブレイクスルー
CVM内の特定のコアについてのアフィニティを持つことが、パフォーマンスが重要なデータサービスにとって重要であることと同様に、IRQのハンドリングもまた、いくつかのコアとのアフィニティを持っています。コアの総合排他を保つことはStargateとネットワーク間の割り込みのハンドリングにおけるCPU内の不必要な競合を避けるために重要です。我々がIRQを特定のCPUのみに制限する際にはすべてのコアに割り込みを分散させてしまうirqbalanceサービスを無効にする必要があります。面白いことに、試験的にIRQをバランスさせてみたところ、定期的なレイテンシのスパイクは殆どなくなってしまいました。この結果によって我々はこれらのネットワークIRQをハンドリングしているコア上でのタスクを調べてみることにしました。
我々は以前にCVM上のすべてを停止させていますから、top -Hコマンドの出力結果はかなり空っぽ ― ランダムreadのワークロードを動作させるためのいくつかのディスクスレッドしかありません。いくつかのテストを走らせるうちに、我々はvip_utilという名前のスレッドがtopコマンドの出力結果にポップアップしてくることに気が付きます。このスレッドは、出力上はさほど高い負荷のスレッドではないのですが、この時点では一体何なのかわかりませんでした。試験的にvip_utilを呼び出しているvip_monitorを停止させてみました、すると、じゃーん! ― レイテンシのスパイクは消えてしまいました!!
根本原因
以前に述べたように、我々は様々な重要なサービスをCVM内でリアルタイム(RT)の優先度で稼働させて、CPUの競合が起きたときにも可能な限り早くそれらのサービスがスケジュールされるようにしています。
それではvip_monitorとはなんなのか?これはiSCSIとユーザーコントロールパスの制御に紐付けられたフローティング仮想IP(VIP)を、CVMがホストできるかどうかを定期的にチェックするサービスです。vip_monitorの一部はvip_util(topコマンドの出力結果に現れたのと同じプログラムです)が受け持ち、ローカルネットワークをチェックしています。vip_utilプロセスはサービスインフラストラクチャを呼び起こし、そしてioctlシステムコールを発行してネットワーク接続状態を取得します。vip_utilは比較的軽量なプロセスですが、親の優先順位を継承してスケジューラー設定を行うため、リアルタイムの優先順位で稼働します。
更に話を進めるため、我々がCVMの様々なコアをどのように使っているのかを見ていきましょう。テストに利用したCVMには以下のテーブルに示したとおり8つのvCPUがあります。それぞれのプロセスにはその優先度にあわせて色を付けており、さらに各々にどのようなアフィニティがあるかも併記しています。ダイアグラムに示されているとおり、StargateはCPU2-CPU7においてはvip_monitorよりも高いリアルタイム優先順位で稼働しています。

StargateとCPU2-CPU7の間にはアフィニティが確立されており、8 vCPU構成では他の2つのコアを他のサービスのために確保していますので、我々は重たいI/Oの最中でもSSHアクセスをブロックすることはありません。後者を実現するためにCPU0-CPU1の間でネットワーク割り込みについてもアフィニティを確立しています。
ここでネットワーク割り込みについて簡単に解説しておきましょう。NICはI/O操作を受信した際に、HW割り込み(一般的にはtop halfと呼ばれています)を生成します。HW割り込みは他の割り込みをマスクしてしまうため、素早く処理しなければなりません。そのため、top halfは(bottom halfのための)作業をソフト割り込みキューにキューイングして結果を返すことしかしません。ksoftirqd/<cpunum>という名前のカーネルスレッドはソフト割り込みキューからイベントを選択して、パケットに対しての残りの作業を実行します。それぞれのCPUには別々のキューがあり、bottom halfのソフト割り込みキューの待ち行列はtop halfのHW割り込みを行った同じCPU上にあります。例えば、もしもHW割り込みがCPU0で行われたのであれば、bottom halfで利用されるソフト割り込みのキューもCPU0です、その後ksoftirqd/0スレッドがパケットをサービスします(これらの処理はすべてtcpdumpのトレースよりも下で行われることに注意してください。)
この割り込みのハンドリングの分布については以下のmpstatの出力結果から見ることができます。すべてのネットワークトラフィックはCPU0とCPU1上で発生する一方、すべてのブロックI/OはStargateのCPU上にあります。
sudo mpstat -I SCPU
08:40:00 PM CPU HI/s TIMER/s NET_TX/s NET_RX/s BLOCK/s IRQ_POLL/s TASKLET/s SCHED/s HRTIMER/s RCU/s
08:40:00 PM 0 0.00 104.31 0.01 43924.35 41.42 0.00 3.15 67.03 0.00 761.08
08:40:00 PM 1 0.00 92.00 0.01 32644.21 73.73 0.00 3.67 72.12 0.00 731.32
08:40:00 PM 2 0.00 218.20 0.96 75.17 2699.12 0.00 0.08 232.29 0.01 480.61
08:40:00 PM 3 0.00 214.70 0.94 64.89 2694.66 0.00 0.08 226.59 0.01 477.86
08:40:00 PM 4 0.00 213.53 0.98 59.24 2713.62 0.00 0.08 219.56 0.01 479.78
08:40:00 PM 5 0.00 213.74 0.98 60.40 2780.72 0.00 0.08 206.89 0.01 487.93
08:40:00 PM 6 0.00 216.50 0.99 56.12 2810.43 0.00 0.08 200.55 0.01 482.76
08:40:00 PM 7 0.00 211.03 0.99 56.98 2894.45 0.00 0.08 192.21 0.01 483.27
Stargateとは異なり、vip_monitorサービスはいずれのCPUともアフィニティがありません。その代わり、カーネルのスケジューラーがそれを他のCPUの負荷状況をベースとして決定します。 StargateはCPUを多く利用するため、大抵の場合でCPU2-CPU7をすべて利用しつくします。結果としてvip_monitorは殆どの場合、CPU0-CPU1にスケジュールされ、ネットワーク割り込みをサービスしているコアと重複してしまうのです。
それでは、根本原因の仮説です。vip_monitorがvip_utilを呼び出した際に、vip_utilがCPU0-CPU1にリアルタイム優先順位で稼働することになり、同じCPU上で稼働するあらゆるネットワークI/Oをサービスするksoftirqdスレッドよりも先にスケジュールされてしまうことで、レイテンシのスパイクが発生しているのです。vip_utilの稼働にかかる時間が、レイテンシのスパイクの間隔に直接影響していました。
この仮説は簡単に証明することができます。すべてのネットワークIRQをCPU0に配置し、CVMに対してpingを連発します、こうすることでリアルタイムに動作するvip_utilをマニュアルでCPU0上でのタスクセットと供に呼び出すことができます。結果としてオンデマンドでvip_utilコマンドが呼び出されるたびに毎回レイテンシのスパイクを再現することができます。さらにvip_utilは間違ったふるまいをしていないことを証明するため、一時的に単にCPUを食いつぶす(乱数を生成する)ためだけのプログラムを作成しました。このプログラムをvip_utilの代わりに動作させることで、レイテンシのスパイクを確認できました。結果として、我々はプロセスが何をしているかに関わらず、リアルタイムにCPU0-CPU1で動作する限りこのような動きになることを学びました。Bottom halfのネットワーク割り込みのハンドリングをプロセスがブロックしてしまい、巨大なレイテンシを引き起こすのです。
修正
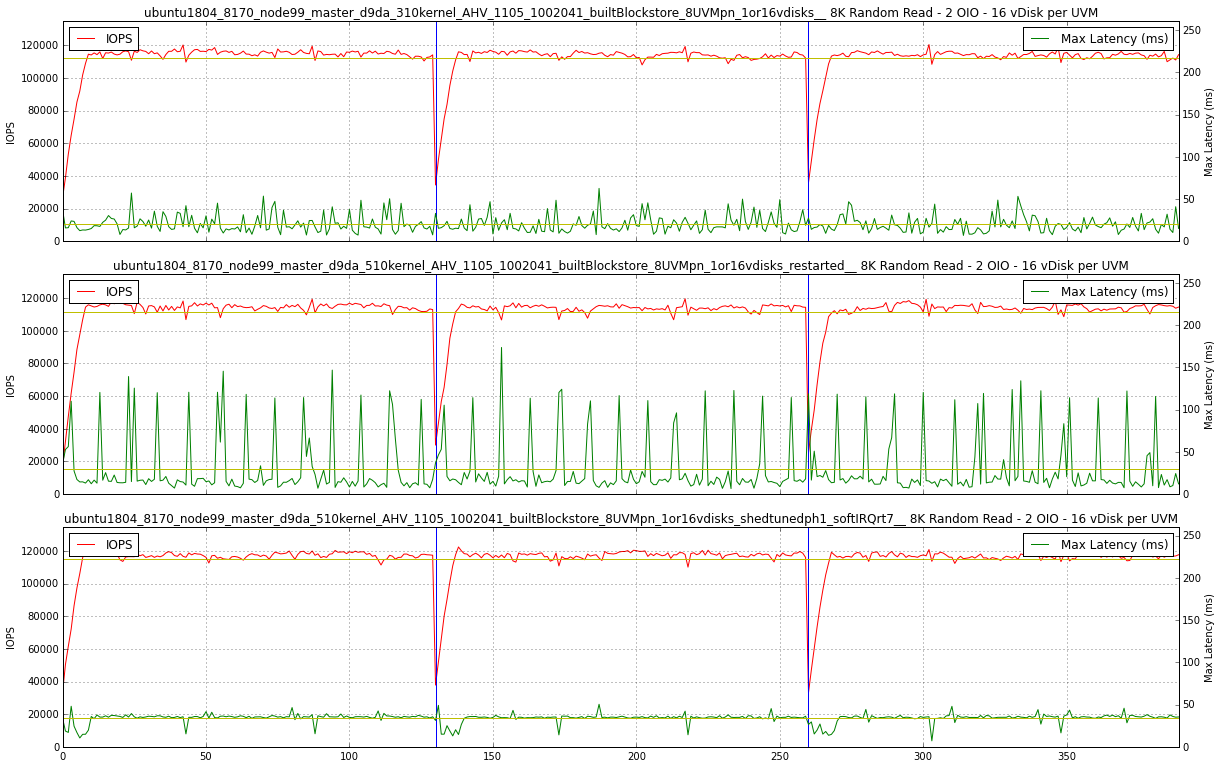
根本原因を見つけてしまえば、修正はこれまでに比べれば些細なことでした。Ksoftirqdスレッドの優先順位をリアルタイムへと変更し、その優先順位をvip_monitorの優先順位よりもさらに高くしました。このシンプルな1行の変更でレイテンシのスパイクはなくなりました!
以下のチャートはバージョン3.10(上)、以前の5.10(中)、そしてksoftirqdのスケジューラーを変更した5.10(下)を表しています。Ksoftirqdを変更した後の最大レイテンシは非常に安定しています ― 実際バージョン3.10上よりも更に安定しています。
問題その3: 低いランダムWriteのスループット
定期的なレイテンシのスパイクを乗り越えた後、もうこれで解放された、クリアしたと考えたのではないですか? 違うのです! 3.10のカーネルと比較してランダムWriteのスループットが依然として劣化していました。我々も最初の検証はSSDのクラスタで行っていたので、これでクリアだと考えていました。ランダムWriteの劣化はトータルのIOPSがもっと高いAll-NVMeプラットフォームのみで発生したのです:SSD 45Kに対してNVMeでは120K。レイテンシのスパイクとは異なり、我々はこの問題を我々のStargateの内部の負荷生成機であるperf_testでも再現させることができました。問題は明らかにStargateです。

上記のテストは単一ノード上で1分間に渡って実施しました。ワーキングセットが小さいため、複製されたログベースのデータストア(oplog)は完全にワークロードを吸収してしまいました。oplogはバースト的なランダムWriteのためのステージングエリアとして機能しており、あとから最終的な保管場所へとドレイン(吸い出し)されていきます。以下のダイアグラムはoplogがデータパスのどこに位置しているかを示しています。
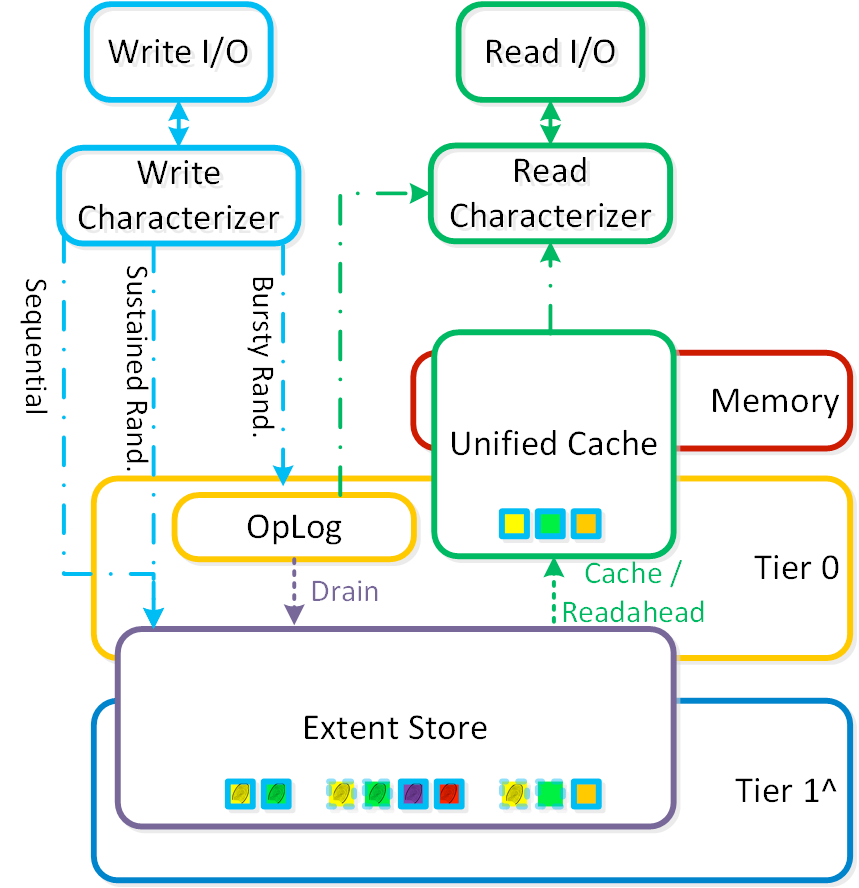
我々は、なぜ3.10上よりも5.10バージョンでoplogが遅いのかを明らかにしなければなりません。
検証環境のレイアウト
問題を完全に理解するため、まずはAll-NVMeクラスタ上のディスクレイアウトについて見ていきましょう。我々はoplogのパフォーマンスに注意を払っているため、oplogのディスク選択ポリシーについて確認します:
- もしもNVMeデバイスがある場合、oplogはNVMe上にのみ配置される
- 最大で12台のディスクまでoplogに利用される
NVMeディスクが8台搭載されたAll-NVMeクラスタ上にはブートディスク2台(ext4)と6台のディスクがStorage Performance Development Kit(SPDK)経由で接続されています。以下の絵では、ブートディスクが、カーネルが提供するシステムコールAPI(“Original Method(従来手法)”の側)。非ブートディスクはカーネルを完全にSPDKで避けています(“BlockStore + SPKD”の側)。BlockStore と SPDKによる経路はext-4管理下のディスクに比べ遥かに低いレイテンシと優れたパフォーマンスを提供します。
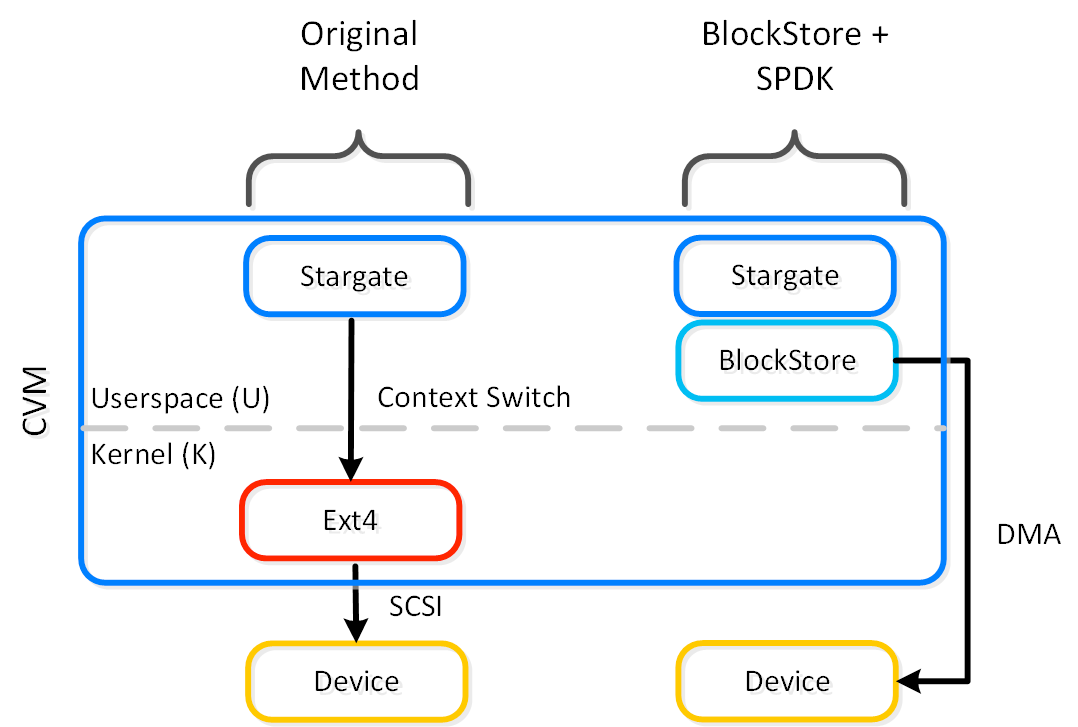
様々な実験
最初は、何らかの理由でSPDKのパフォーマンスが3.10の頃のそれよりも5.10で低いのではないかということを疑いました。この想定に基づいてepoll設定、StargateのSPDKの変数調整、様々なパッチについての実験を行いましたが、どれにも手がかりはありませんでした。続いて我々は社内のツールを利用して、NVMeディスクをそのままStargateからではなくSPDK経由で直接で接続、指定したワークロードを流した場合に劣化が発生するかどうかを見てみました。このテストを同じ物理ディスクで流した際には3.10と5.10のカーネル間に違いは見られませんでした。ですが、ディスク毎にパフォーマンスにばらつきがあることを発見しました。結果としてはすべての比較要素は同じ物理ディスク、同じクラスタ上で行うべきだと考えました。
SPDKは5.10上では遅くはなっていなかったので、oplogをSPDKのディスクのみに限定して試してみることにしました。この変更を加えたところ、パフォーマンスはほぼ同等になったのです!
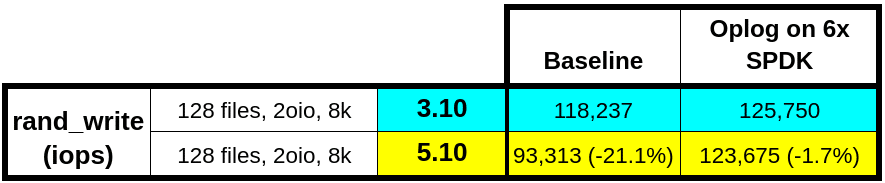
この実験からの面白い発見は、3.10のパフォーマンスも改善されたことです。Nutanixではこの改善を今後のAOSのリリースにも取り込む予定です。6台のNVMeデバイスがあれば、oplogの要件を満たすためには、SPDKで接続されたディスクの低遅延と帯域は充分以上であることは明らかです。実際、oplogをブートディスク上にも保持することはパフォーマンスに影響を及ぼします。我々は当初、oplogをSPDKディスクのみに制限することがこの劣化についてのソリューションであると考えました。しかし、この変更はすべてのプラットフォームで可能なわけではありません。NVMeが4デバイスしかないような構成では、oplogを2台のNVMeデバイスだけに限定すると、最大のスループットを達成することはできませんでした。根本原因を見つけ出す必要がありました。
根本原因
Oplogをすべてのディスク上に保持する構成で、perf_testを走らせ、topコマンドの出力結果からカーネルスレッド(kworker/<cpu>)が膨大な量のCPUを消費していることが確認できました。カーネルは kworker threads を利用して、カーネルが必要とするあらゆる全てのワークを実行しています。5.10が3.10よりも良い点の一つとして、カーネルがkworkerスレッドの名前に、そのスレッドが現在行っている作業を付加することで、デバッグに役立つという点があります。
ランダムWriteワークロードの最中、kworker/<cpu>-dio スレッドが top -Hの出力結果で上位に表示され、膨大な量のワークを行っていることが示されました。カーネルコードを掘り進めていくと、このdioはdirect-ioであることがわかりました。
16888 nutanix -11 0 84.3g 154216 115448 S 19.1 0.2 0:07.45 oplog_disk_81
16880 nutanix -11 0 84.3g 154216 115448 S 16.5 0.2 0:07.57 oplog_disk_65
16886 nutanix -11 0 84.3g 154216 115448 S 16.2 0.2 0:07.01 oplog_disk_77
16884 nutanix -11 0 84.3g 154216 115448 S 15.8 0.2 0:07.27 oplog_disk_73
16890 nutanix -11 0 84.3g 154216 115448 S 15.8 0.2 0:06.99 oplog_disk_85
16892 nutanix -11 0 84.3g 154216 115448 R 15.8 0.2 0:07.50 oplog_disk_88
...
6586 root 20 0 0 0 0 I 0.7 0.0 0:00.26 kworker/4:0-dio
12022 root 20 0 0 0 0 I 0.7 0.0 0:00.22 kworker/5:2-dio
28054 root 20 0 0 0 0 I 0.7 0.0 0:00.13 kworker/2:1-dio
この問題はようやく完全な姿を顕し始めました。レイテンシのスパイクの問題で議論してきたように、我々は様々なNutanixサービスをリアルタイム優先順位で稼働させています。特に、Stargateは最も多くのCPU数を利用して稼働しています。我々はoplogをext4のブートディスク上でも動作させています。Oplogがdirect-ioのWriteを発行すると、それはkworkerスレッドによるdirect-ioのワークを発生させることになります。もしもkworkerスレッドがdirect-ioのワークをStargateが稼働しているCPUにおいて発生させると、スケジューラーはリアルタイムのStargateの利用を、通常優先順位のkworkerスレッドとバランスさせる必要が出てきます。
この結果、システムはkworkerスレッドをリアルタイムのStargateのワークよりもあとに優先順位付けしてしまうのです。Stargateはカーネルのdirect-ioワークを生成しますが、一方でStargateがそのワークの実行を妨げてしまい、ext4ディスクにおけるパフォーマンスを低下させてしまうのです。その一方で、SPDKディスクはすべてのI/Oを投げ込むワークをStargateプロセス内部でハンドルしていますので影響を受けません、ですから、カーネルに処理が入ることはなく、スケジュールを行う必要もないのです。
この考えを検証するため、マニュアルですべてのkworkerスレッドのプライオリティをStargateと同じに変更しました。この変更を行うと、パフォーマンスは3.10のレベルに戻りました…が、時々だけです。
我々はkworkerスレッドが一時的なものであると気が付きました。これらは生まれては消えていくだけでなく、その時どきで異なるワークを処理しているのです。ですから、マニュアルでそのプライオリティを変更しても短時間しか効果がなく、長期的なソリューションであるとは言えません。我々はこの値を実行時に変更するインフラサービスをCVM上に持つこともできません。スケジューリングポリシーと優先順位を変更するカーネルレベルでの変更が必要になります。結果として、我々はすべてのカーネルが生成するワーカースレッドをリアルタイムにし、Stargateと同じ優先順位とするカーネルパッチを作成しました。
commit 2991f4fd2aa83e4974988812f7304ebedfe80e94 (HEAD -> master)
Author: Harshit Agarwal <harshit.agarwal@nutanix.com>
Date: Thu Aug 26 22:09:11 2021 +0000
Assigning RR RT scheduling policy with priority 10 to kernel threads
diff --git a/kernel/kthread.c b/kernel/kthread.c
index 36be4364b313..442f90975964 100644
--- a/kernel/kthread.c
+++ b/kernel/kthread.c
@@ -370,7 +370,7 @@ struct task_struct *__kthread_create_on_node(int (*threadfn)(void *data),
}
task = create->result;
if (!IS_ERR(task)) {
- static const struct sched_param param = { .sched_priority = 0 };
+ static const struct sched_param param = { .sched_priority = 10 };
char name[TASK_COMM_LEN];
/*
@@ -383,7 +383,7 @@ struct task_struct *__kthread_create_on_node(int (*threadfn)(void *data),
* root may have changed our (kthreadd's) priority or CPU mask.
* The kernel thread should not inherit these properties.
*/
- sched_setscheduler_nocheck(task, SCHED_NORMAL, ¶m);
+ sched_setscheduler_nocheck(task, SCHED_RR, ¶m);
set_cpus_allowed_ptr(task,
housekeeping_cpumask(HK_FLAG_KTHREAD));
}
~
このパッチは以前議論したレイテンシのスパイクの問題も解決します。この1つのカーネルパッチを利用することですべてのksoftirqd, kworkerそしてそれ以外のカーネルスレッドをリアルタイム化し、望んだ優先順位にセットすることができます。Nutanixのパフォーマンスチームはすべての性能劣化について修正がなされたことを確認済みです。
終わりに
カーネル5.10の検証において我々が出くわしたすべてのパフォーマンス問題には共通したテーマがありました。それら全てはリアルタイムスケジューリングに関連していたのです。バージョン3.10ではリアルタイム優先順位のユーザータスクが、何らかのカーネルワークのスレッドのパフォーマンスを食いつぶすことはありませんでした。カーネルスレッドは、リアルタイムの競合するユーザータスクと、高いと言えないまでも平等な優先度で取り扱われていたようです。topとchrtコマンドの出力結果で確認する限り、3.10と5.10のバージョン間でカーネルスレッドのスケジューリング設定に変更はありませんでしたが、そのふるまいは明らかに2つのカーネル間で異なっていました。実際、5.10の振る舞いは理想として期待したとおりで、これらのカーネルスレッドは標準のスケジューリングポリシーを利用していました。
カーネルのスケジューリングの変更を注意深く見ていくと、カーネルはユーザーに、リアルタイムタスクの実行を開始したらすぐに、すべてのスケジューリングポリシーを指示してほしいと考えていることがわかります。カーネルは、必要な関連情報が不足しているため、自ら正しい判断を下すことができません。我々が kthreadの優先順位を上げた第一の理由はパフォーマンスでしたが、いずれ、検知やデバッグがより難しい、リソースを食いつぶされたほかのカーネルタスクが生じても発見できるでしょう。
スケジューラー内でのカーネルスレッドのハンドリングについて、何が異なるのかを見つけ出していくのは今後の課題です。私たちが検討したいもう1つのアプローチは、リアルタイムスケジューリングポリシーをNutanixのデータサービス全体から取り除き、その代わりにサービス間の優先順位を優れたレベルで理解した別のスケジューラーを利用することでしょう。