

Nutanix Community Edition(CE)に関する話題はこちらへどうぞ。
- Community
- International Forums
- 日本語フォーラム (Japanese)
- Nutanix CE よろず相談所
Nutanix CE よろず相談所
- July 14, 2020
- 63 replies
- 20009 views
This topic has been closed for replies.
63 replies

- Adventurer
- July 14, 2020
NutanixCEについてご教示ください。
物理サーバー(RX1330 M4 ベアメタル)を購入し、 NutanixCEをUSBブートにて導入しようとしておりますが、 機器がUEFIブートしか対応しておりませんでした。 そのため、フォーマットがFAT32でしかブートの認識をしてくれないのですが、 4GBを超えるNutanixCEイメージをFAT32形式でUSBに保存できません。 何か解決方法があれば教えていただけないでしょうか。
 +9
+9- Author
- Nutanix Employee
- July 14, 2020
ご質問ありがとうございます。
Nutanix CEのブートUSBを作成する際は、フォーマット済みのUSBメモリにファイルを放り込むのではなく、imgファイル自身がディスクイメージ(内部にパーティションやファイルシステムがある)なので、イメージ書込みツールやddコマンド等で書き込む必要があります。(USBメモリ自体を事前に何らかのファイルシステムでフォーマットする必要はありません)
下記の記事における手順4が当該の部分です。
一度こちらの方法をご確認いただけますでしょうか?
https://blog.ntnx.jp/entry/2020/02/24/152143
- Adventurer
- July 15, 2020
ご返信ありがとうございます。
USBWriterで書き込むと、BootOptionでUSBが選択肢に出てきません。
おそらくUEFI対応のみで、CSMの設定がない機種なので
FAT32形式でフォーマットし、imgファイルを配置しないと選択出来ないと思っております。
(NTFSやexFATだとブートの選択ができませんでした)
※Windowsの場合ですが下記記事などを参考にしています。
https://syobon.jp/blog/2017/07/24/melancholy-of-windows-server-manager-tips-01/
もし、無理なようであればESXiで仮想環境に導入したいと考えています。
+9- Author
- Nutanix Employee
- July 15, 2020
すみません、問題点を読み違えておりました…
[4枚目]Nutanix Advent Calendar 2019 にご投稿いただいた記事に、まさにという情報がありました。こちらでいかがでしょうか?

- Trailblazer
- October 29, 2020
お世話になります。1点質問よろしいでしょうか。
Nutanix CEのクラスタからホストを削除するところで引っかかっております。
4ノードクラスタを構成し稼働させていました。VM用のVLANを設定したタイミングだと思うのですが、ホスト1台が見えなくなってしまいました。
確認するとそのホストのCVMが起動不能になっていましたのでAHVのCLIからvirsh startで起動を試みましたがやはり起動しませんでした。
今まで何度かホストの入れ替え(スペックを上げるために1台クラスタから削除して1台追加する、といった感じ)は行っておりましたので、同じように問題のあるホストを削除して、再セットアップしたホストをあらためて追加しようとしたのですが、該当ホスト上で稼働していた4つの仮想マシン(+Prism Centralの仮想マシン)がPrism Elementで見ると、On(緑)、Off(赤)のところがunknownという灰色のマークになっており、マイグレーションも起動もできない状態のため、クラスタから外すこともできません。
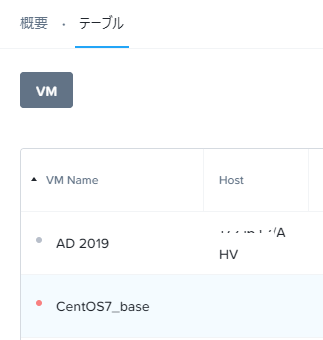
「ハードウェア」-「ホスト」で該当ホストをポイントすると、リスト下のメニューは「Being Removed」の表示になっています。

恐らく、この灰色の表示になったunknownのステータスのVMをどうにかできれば正常にホストを削除できると思うのですが、何か良い方法は無いでしょうか。
なお問題が起きたホストは、現状USBメモリから再セットアップを行った状態です。
バージョン情報は以下のとおりです。
AOS:2019.11.22
AHV:20191030.415
NCC:3.10.1
Foundation:foundation-4.5.4.2-94510908
以上、よろしくお願いいたします。
+9- Author
- Nutanix Employee
- December 28, 2020
遅レスになってしまいましたが、疎通不能なノードの強制削除についてはこちらのKBがご参考になるかと思いますので貼らせて頂きます。
Removing Unreachable or Powered-off Nodes From Nutanix Clusters
https://portal.nutanix.com/page/documents/kbs/details?targetId=kA032000000TSnZCAW
Prism Central VMもグレーアウトしてしまっているとのことなので、もしも仮にPrism Central配下からの強瀬離脱も必要となった場合のための情報として、こちらもご参考まで。
Unregister cluster from Prism Central and cleanup | Force unregister PE from PC after PC is deleted
https://portal.nutanix.com/page/documents/kbs/details?targetId=kA00e000000XeZjCAK
How to delete a Prism Central VM
https://portal.nutanix.com/page/documents/kbs/details?targetId=kA00e000000LKnuCAG
- Trailblazer
- January 4, 2021
- Trailblazer
- January 6, 2021
smzksts 様
大変お世話になっております。
ご提示いただいた情報をもとに、まず故障したホストの削除を試みてみました。
nutanix@cvm$ ncli host rm-start id=xxxxxx skip-space-check=trueHost removal successfully initiated
※xxxxxxは、「ncli host list」で確認した値
その後、「ncli host get-remove-status」で確認しますと、
Host Id : xxxxxxxxxxxxxxxxxxxxxxxxxxxxxx
Host Status : MARKED_FOR_REMOVAL_BUT_NOT_DETACHABLE
Ring Changer Host Address : xx.xx.xx.xx
Ring Changer Host Id : xxxxxxxxxxxxxxxxxxxxx
この状態のまま変化がない状態が続いており、PEで見ると依然ホストが削除されないまま残っているように見えます。
念のため、タスクも「ncli progress-monitor list」で確認してみましたが、削除コマンド実行時の時間に近い(UTC表示でしたので、9時間足して確認しています)タスクは表示されませんでした。
追加:
最初の書き込みで書き忘れがありましたので、追記しておきます。
「ncli host list」の出力で、削除したいホストの「Metadata store status」は
Metadata store status : Node is removed from metadata store
となっております。
なおPrismCentralの接続解除は、ご提示いただいたKBの内容で正常に行えました。
仮想マシンは残っていますが、とりあえず一歩前進した感じです。PEで見ても「Prism Central に登録されていません」となっているので、大丈夫だと思います。
仮想マシンのテーブルに元のPCの仮想マシンが残っていることを気にしなければ、新規でPrismCentralをデプロイしても問題ないでしょうか。
ホストの削除は、時間がかかっているだけかもしれませんので、もう少し時間をおいて再度確認してみようと思います。
また進捗があればご報告させていただきます。
+9- Author
- Nutanix Employee
- January 6, 2021
ご報告ありがとうございます。
どうやらノードが削除できていないようですね…。
ncli host rm-startコマンドに force=true というオプションを追加すると成功するかもしれません。
また、古いPCは、PrismのGUI操作では削除できませんが、CVMのコマンドラインで
acli vm.delete <Prism Central VM name> で消せるのではないかと思います。
(私自身も過去何度か、この操作で削除しています)
ただ、古いPCが残っていてもディスク容量の消費以外、干渉したりすることは無いはずですので、新しいPCをデプロイし、接続して頂いても問題ないと思います。
- Trailblazer
- January 7, 2021
smzksts 様
大変お世話になっております。
Prism Centralを削除しなくても新規で接続するのは問題ないとのことで、また一つ前に進めそうです。
※すぐに使えないといけない予定も無いので、あとからじっくりやってみようと思います。
acli vm.delete は実行してみましたが、PCの仮想マシンは削除できませんでした。
試しに他の仮想マシンでもやってみましたが、以下のような結果でした。
・「仮想マシン」ー「テーブル」でグレーになっている仮想マシンはタスクが0%のまま進まない
・赤(停止中)で正常なホストにいる仮想マシンは何の問題もなく削除できる
・緑(起動中)の仮想マシンでは試していません
ホスト削除のncli host rm-start force=true も実行してみましたが、こちらも
Host removal successfully initiated
と応答はあるものの、前回同様にタスクが出てくる気配がない状態です。
何度かトライしているので裏で処理が進んでないタスクが残っているのではと思い、
https://next.nutanix.com/how-it-works-22/clear-out-stuck-tasks-31879?postid=39355#post39355
ここの情報を参考にして
ecli task.list include_completed=false
で表示されたタスクはすべて
~/bin/ergon_update_task --task_uuid=xxxxxxxxxxxxxxxxx --task_status=aborted
で中断してみましたが、ホストの削除もVMの削除も効果が無い状況です。
少しNutanixバイブル(日本語版)も見て確認してみたんですが、ncli vm.delete には force=trueのような強制するオプションは無いのですよね?
あと試してみたことは、削除できない仮想マシンのディスクを acli vm.disk_delete で削除してからならできないかな?とも思ったのですが、これ自体も0%のままで進みませんでした。
きっと障害が発生したときに、あとからホスト削除→再構築して再度追加ではなく、ブートディスク(USBメモリ)の復旧をすればこんなことにはならなかったと深く反省している次第です。
※何度もやっている手順でもあったので、作業者に指示しやすかった面もあったのですが・・・。
とりあえず、3台構成でもテストや評価は進められる部分も多いので、気長に対応していこうと思います。
+9- Author
- Nutanix Employee
- January 9, 2021
PCの削除もノードの削除もレスポンスが無いというのは気になりますね…。
他のVMの作成/削除には支障ない状態でしょうか?
ご認識のとおり、acli vm.delete にはforceオプションはありません。本来、デフォルトでforceな形で処理されるものです。
MARKED_FOR_REMOVAL_BUT_NOT_DETACHABLEをキーワードとして検索して、他に関連しそうな公開KBとしては下記のもの程度でした。
AHV | Node removal stuck after successfully entering maintenance mode
https://portal.nutanix.com/page/documents/kbs/details?targetId=kA00e0000009D6CCAU
もしもこちらの状況に合致するようであれば、回避策として、Acropolisサービスのマスターを再起動する、という方法も考えられます。
- 任意のCVMのCLIにログインし
links http://127.0.0.1:2030
というコマンドを実行すると、テキストベースのウェブブラウザが実行されます。 - Acropolisサービスの詳細が表示されますので「Acropolis Master」という項目を確認します。「this node」または他のCVMのIPアドレスが表示されます。
- Acropolis Masterの項目に表示されたCVMにアクセスし。下記のコマンドでacropolisサービスを再起動します。
genesis stop acropolis; cluster start - もしも手順3でも変化がない場合には、メンテナンスモードの無効化と有効化を手動で行います。
acli host.exit_maintenance_mode <host IP or uuid>
acli host.enter_maintenance_mode <host IP or uuid>
他にもKBを探してみたのですが、あいにくInternal向け(非公開)なものに限られておりました…不安定な状態で様々な対応を試行するのもリスキーな気もしています(商用版ならサポート部門が解析した上でより的確な対応策をご案内するのですが、なにぶんCEのため…)。
もしも大事なGuest VMがある&CEをインストール可能な機材が他にもありましたらAsync DRでデータの退避した上で再インストールを行うなどの対応も視野に入れておいて頂くのがよろしいかもしれません。
- Trailblazer
- January 18, 2021
smzksts 様
他のホストは正常に動作していますので、グレー以外の仮想マシンの変更や新規作成には問題ありません。
ホスト(クラスタ)の再構築は最終手段としてある程度覚悟はしていました。
スペックはかなり落ちるものの、一時的な受け皿とするための機材は何とかなりそうですので、最悪そうしないといけないね、と内輪では話をしていた感じです。
仰るとおり、かなりいろいろなテストをしたりホストの差し替えを頻繁に行ったりで無茶している環境ではありますので、このあたりですっきりと整理しても良いかなと思っています。
まだご提示いただいたKBの内容は読み切れていませんが、なんとなく一致しそうな気がしています。
Acropolisサービスのマスター再起動はまた後日試してみて、解決しなければ一時的に別のクラスタ作ってAsyncDRで逃がしてクラスタを1から再構成することを計画しようと思います。
CE版にも関わらず、いろいろアドバイスいただけてむしろ感謝しております。
また少し間が空くと思いますが、結果などは報告させていただきますのでよろしくお願いします。
+9- Author
- Nutanix Employee
- January 26, 2021
Twitter等では紹介していたのですが、CE関連の資料を作ったのでコチラにも載せておきます!
Nutanix CE 5.18のインストールに関する詳細解説資料です。
インストール周りで躓きがちなポイントとその回避方法をたくさん載せてますので、
上手くいかないときにまずはご一読くださいませ。
- Trailblazer
- February 17, 2021
smzksts 様
だいぶ間が開いてしまい恐縮ですが、一部仮想マシンが削除できない&ホストも削除できないの件で、少し前進しました。
Acropolisのマスター再起動はまだ試していませんが、別のクラスタをシングルノードで構築してリモートDRでクラスタ跨いでスナップショットを取る、というのをやってみました。
結果としては、灰色になって起動も削除もできなかった仮想マシンを含め(少々驚きました)、スナップショットの取得に成功、別のクラスタ上で正常に起動することも確認できました。
灰色になった仮想マシンの復旧方法としても使えそうです。
とりあえず必要そうな仮想マシンを新しいクラスタに一旦退避して、何が起きても大丈夫な状態でAcropolisのマスター再起動も試してみようと思います。
業務の合間で試しているのでなかなか進みませんが、また報告させていただきます。
- Trailblazer
- March 16, 2021
smzksts 様
お世話になっております。
また大分時間が開いてしまいましたが、破損ホストの削除不可、一部仮想マシンの操作不能(グレー表示)の件で結果報告いたします。
Acropolisのマスター再起動は、既に試していたようです。
残してあった操作のメモ見たら、同じKBを参照して対応していました。
残念ながらAcropolis再起動では解決しなかったようです。
仮のクラスタは問題なくリモートDRで仮想マシンの移動ができて動作確認もできましたので、すべてのホストを新規クラスタで作り直しました。
現在は、仮クラスタの仮想マシンを戻し、すべて正常に動作するようになりました。
ありがとうございました!
※いろんなテストをしていたので、かえってこれでスッキリきれいな環境になってうれしい面もあります。
今回の一件で、NutanixCEでいろいろテストしていく上で結構リモートDRは良いなぁと感じました。
最悪クラスタを破壊するようなことがあっても、あっさり戻せるのは安心感があります。
※10GLANということもあるかもしれませんが、あまりに速くて逆に心配になったくらいです。
NGTを入れていない仮想マシンも多かったので、今回は仮想マシンをシャットダウンしてからスナップショットを取るようにして移行しましたが、NGTを入れておけば活動中でも大丈夫そうです。
このあたりはもう少しテストしてみようと思います。
さて、再構築したときに気付いたのですが、いつの間にか新しいバージョンがリリースされていたのですね。
こまめにPrismでアップデートの確認していてもNCCとFoundation以外は出てきていなかったので、そのまま2019.11.22版で再構築したのですが、コミュニティ見ると2020.09.16版になっていて驚きました。
Prismのアップデートでは検出されませんでしたが、「バイナリのアップロード」でアップデートしても問題は無いでしょうか?
なんとなく順序としては、
- AOSのアップデート
- AHVのアップデート
- PrismCentralのアップデート
こんな感じなのかなと思っていますが、合ってますでしょうか。
- Trailblazer
- March 22, 2021
いつもお世話になっております。
以下リンク先の内容に沿って、アップグレードを実行してみました。
https://blog.ntnx.jp/entry/2020/09/30/235747
4台ホストのクラスタ中、1台だけは普通にアップグレードが完了(タスク一覧で100%になりました)したように見えましたが、残り3台が73%のまま数日待っても変化無しという状態です。
あまりに状況に変化が無いままでしたので、一旦クラスタを停止して、ホストの再起動を行ったところ、クラスタが起動しなくなってしまいました。
cluster start
→WARNING genesis_utils.py:1199 Failed to reach a node where Genesis is up. Retrying... (Hit Ctrl-C to abort) ※24行くらい繰り返し
Waiting on xx.xx.xx.xx (Up, ZeusLeader) to start: IkatProxy IkatControlPlane SSLTerminator SecureFileSync Medusa DynamicRingChanger Pithos Mantle Stargate InsightsDB InsightsDataTransfer Ergon Cerebro Chronos Curator Athena Prism CIM AlertManager Arithmos Catalog Acropolis Uhura Snmp SysStatCollector NutanixGuestTools MinervaCVM ClusterConfig Mercury Aequitas APLOSEngine APLOS Lazan Delphi Flow Anduril XTrim ClusterHealth
Waiting on xx.xx.xx.xx(Up) to start: IkatProxy IkatControlPlane SSLTerminator SecureFileSync Medusa DynamicRingChanger Pithos Mantle Stargate InsightsDB InsightsDataTransfer Ergon Cerebro Chronos Curator Athena Prism CIM AlertManager Arithmos Catalog Acropolis Uhura Snmp SysStatCollector NutanixGuestTools MinervaCVM ClusterConfig Mercury Aequitas APLOSEngine APLOS Lazan Delphi Flow Anduril XTrim ClusterHealth
Waiting on xx.xx.xx.xx (Up) to start: IkatProxy IkatControlPlane SSLTerminator SecureFileSync Medusa DynamicRingChanger Pithos Mantle Stargate InsightsDB InsightsDataTransfer Ergon Cerebro Chronos Curator Athena Prism CIM AlertManager Arithmos Catalog Acropolis Uhura Snmp SysStatCollector NutanixGuestTools MinervaCVM ClusterConfig Mercury Aequitas APLOSEngine APLOS Lazan Delphi Flow Anduril XTrim ClusterHealth
Waiting on xx.xx.xx.xx (Down) to start:
~中略~
The state of the cluster: Unknown
Lockdown mode: Disabled
CVM: xx.xx.xx.xx Down →4台分
と表示されています。
genesisが起動していないのかなと思い、
genesis start
すると、already runningとなるので起動はしているように見えます。
CVMから「ping 192.168.5.1」は4台すべて通っています。
何かクラスタを復旧する方法は無いでしょうか?
- Trailblazer
- March 22, 2021
その後、クラスタのステータスなどを調べて、4台中3台のCVMでscavengerサービスが起動していないことがわかりました。
起動しているのはアップデートが正常完了?したホストの1台だけです。
また、ncliやacliを実行するとconnection refusedとなり、zookeeper.outにも同様に
ZOO_ERROR@handle_socket_error_msg@2185: Socket [xx.xx.xx.xx:9876] zk retcode=-4, errno=111(Connection refused): server refused to accept the client
が延々と記録されている状況です。
ここがクリアになれば先に進める気がするのですが、何か情報は無いでしょうか?
- Trailblazer
- March 23, 2021
smzksts 様
上記の状態ですが、例えば途中で中断したアップグレードを再開させるコマンドなどは無いでしょうか?
途中で再起動するようなことをしてしまっているのでうまく完了するとは限らないのですが、試してみる価値は無いでしょうか。
- Voyager
- May 30, 2021
Nutanix Filesについてご教示ください。
CE(202009)にてサポートされたと聞き試行したところ、毎回タスクが下記メッセージにてエラー停止します。
「Cannot complete request in state InvalidVmState: Cannot complete request in state Paused」
確かにVMタブを見ていると、いったんFile Server VMがパワーオンし、その後ポーズ状態に遷移し削除されています。何か思い当たる解決策がありましたら、ご教示ください。
- Voyager
- September 18, 2021
こんにちは。
https://speakerdeck.com/smzksts/nutanix-ce-5-dot-18-deep-dive?slide=56
上記の56スライド目以降を拝見して、Nutanix CE 5.18にESXiをインストールするときに必要なLocal VMFS有効化を行おうとしましたが、インストール後リブート前に/dev/sdd5 をマウント時にdoes not exitと返されてしまい、/dev/sda5 の起動用のjsonファイルの該当箇所は元から
"user_vmfs?_datastore":"true"
となっているのですが、そのままrebootをかけるとFaild-Installになってしまいますが、
ssd5のパスは環境によってかわりますでしょうか。(ls /dev で確認したところssd1のみ確認できましたが/Nutanix以下のディレクトリはなし)
■試したESXiバージョン
7.0U2a-17867351
7.0-15843807
6.7-14320388
何卒宜しくお願い致します。
- Voyager
- September 19, 2021
こんにちは。
https://speakerdeck.com/smzksts/nutanix-ce-5-dot-18-deep-dive?slide=56
上記の56スライド目以降を拝見して、Nutanix CE 5.18にESXiをインストールするときに必要なLocal VMFS有効化を行おうとしましたが、インストール後リブート前に/dev/sdd5 をマウント時にdoes not exitと返されてしまい、/dev/sda5 の起動用のjsonファイルの該当箇所は元から
"user_vmfs?_datastore":"true"
となっているのですが、そのままrebootをかけるとFaild-Installになってしまいますが、
ssd5のパスは環境によってかわりますでしょうか。(ls /dev で確認したところssd1のみ確認できましたが/Nutanix以下のディレクトリはなし)
■試したESXiバージョン
7.0U2a-17867351
7.0-15843807
6.7-14320388
何卒宜しくお願い致します。
自己解決済み
7.0U2a-17867351
7.0-15843807
→VMFS参照不可
6.7-14320388
→VMFS参照可,CVMの起動に失敗していたので,スライド62以降の手順でpyスクリプトの修正・再実行・Clusterの手動作成にて無事Prsim起動いたしました。
Enter your E-mail address. We'll send you an e-mail with instructions to reset your password.