

I would like to take full blame for people thinking self healing solves all problems with Nutanix Cloud Clusters (NC2). The self-healing is pretty awesome for bad nics, hard drives and nodes but there are some instances where the portal can’t take action.
Status checks on AWS are performed every minute, returning a pass or a fail status in the Cloud Portal. If all checks pass, the overall status of the instance is OK. If one or more checks fail, the overall status is impaired.
There are two types of status checks, system status checks, and instance status checks. System status checks monitor the AWS systems on which instance runs. Instance status checks monitor the software and network configuration of individual instances.
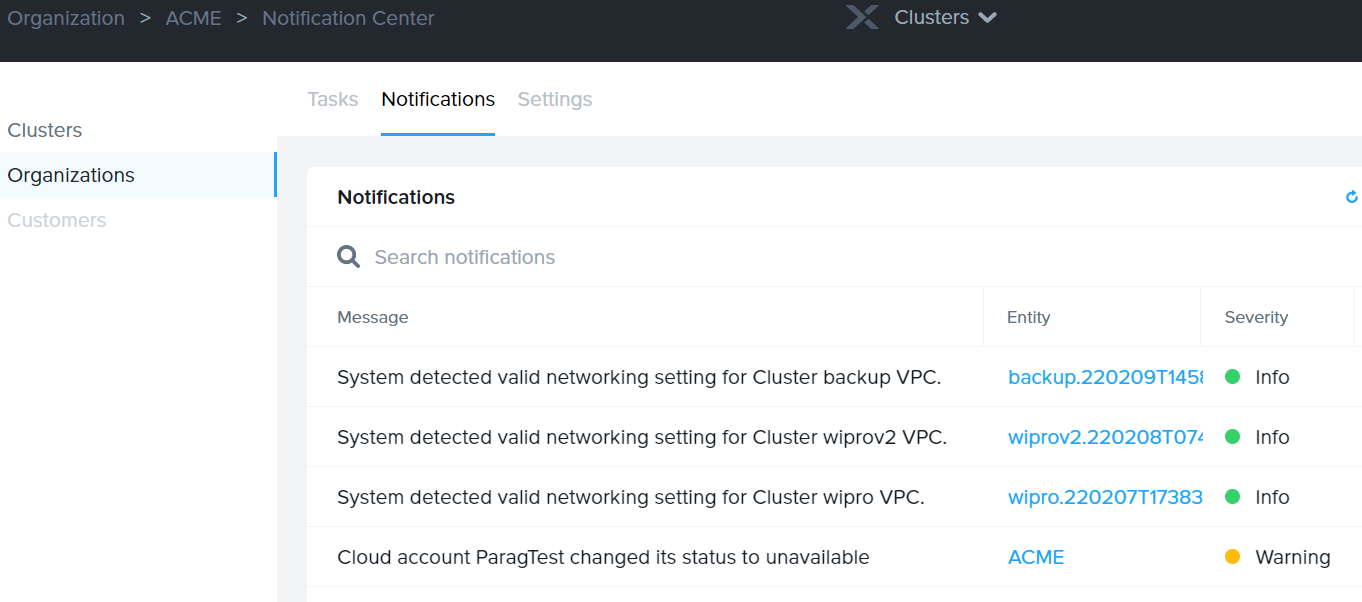
Notification Center in the Clusters Portal
The Clusters portal has an notification service that keeps track of all informational, warnings and critical alerts. Like most Cloud based services there is no support for SNMP in the portal but does have the ability to send email addresses. It’s our recommendation to utilize a service like PagerDuty that can start any additional workflows that may be needed.
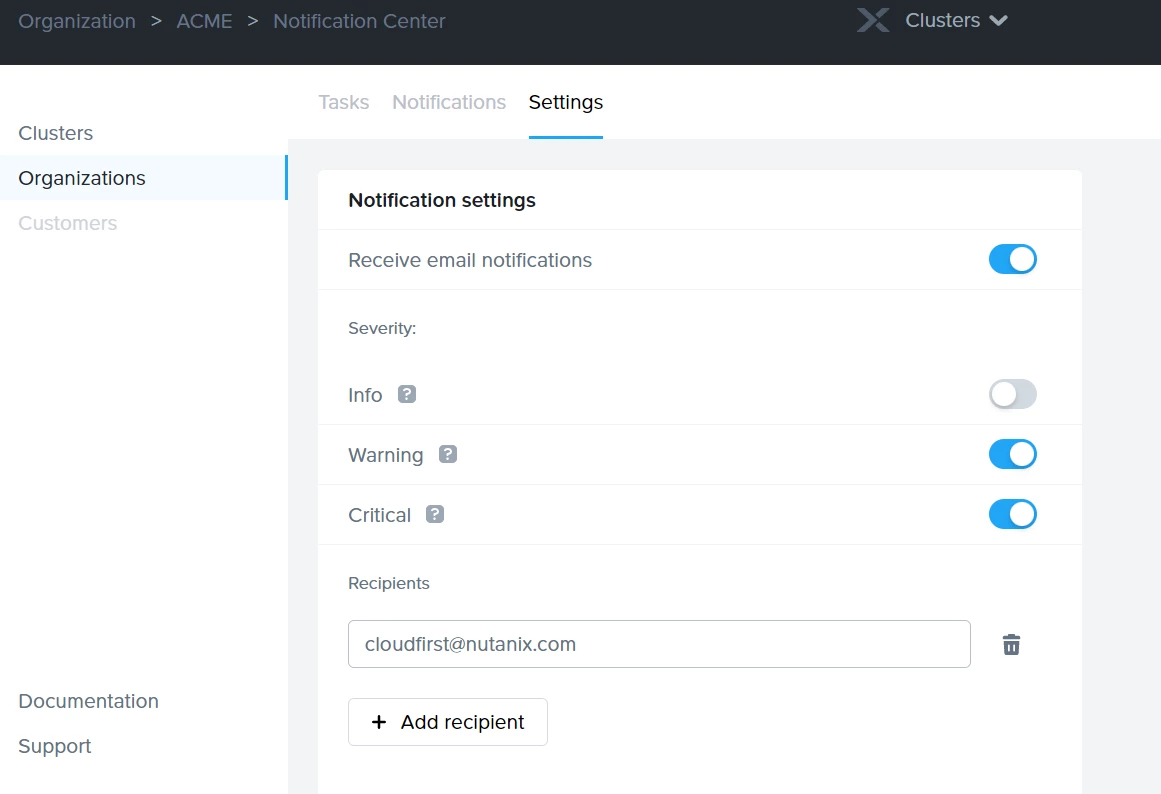
Make sure to configure this option before your deploy NC2. More info in KB9704 on the Nutanix Portal,
Happy Clouding.