I want to test Microsegmentation on prism central, but "AHV Free Memory Minimum 1GB for each Prism Central VM" showed up. And I can't enable Enable Microsegmentation check box. 20gb memory assigned to prism central. What was the problem ?
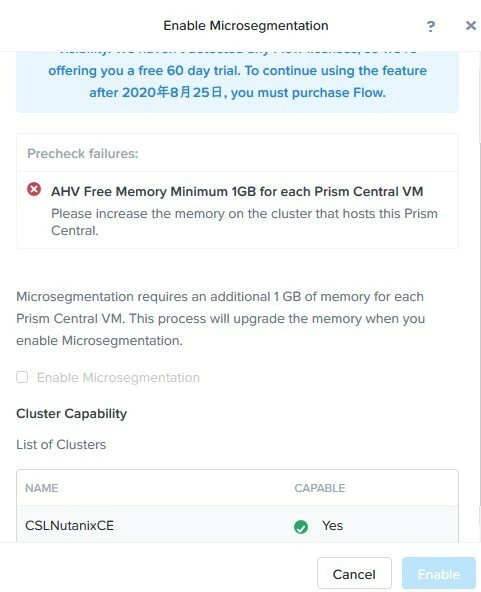


I want to test Microsegmentation on prism central, but "AHV Free Memory Minimum 1GB for each Prism Central VM" showed up. And I can't enable Enable Microsegmentation check box. 20gb memory assigned to prism central. What was the problem ?
Best answer by AnishWalia20
Hey
Please make sure that AHV hosts, where Prism Central VMs are running, have at least 1 Gb of memory free. You can check this on Hardware page in Prism or
If you want to check memory usage from the command line, then check "Memory Free" column in "Hosts" section of Scheduler page on Acropolis master for the particular host where PC-VM is running:
You can get to know the Acropolis master amongst the CVM using the commands mentioned in this KB http://portal.nutanix.com/kb/2305
SSH to the CVM which is the acropolis master and run this command below to go to the Acropolis Links page: cvm$ links http:0:2030/sched <----- on the acropolis master
NOTE: Do not use "free -h", "top", "cat /proc/meminfo" commands, as AHV reserves all free memory and output of these commands will in most cases show that almost no free memory is left.
If there is enough memory available on AHV host, where Prism Central VMs are running, then please make sure that time between Prism Central VMs and Prism Element CVMs is in sync. If time is not in sync, then it needs to be fixed. Flow enablement workflow relies on Prism element statistics stored in IDF, so if time is not synced, we will not be able to query for most recent host memory usage and precheck will fail.
So to troubleshoot NTP issues you can use this awesome KB http://portal.nutanix.com/kb/4519 .
If the issue still persists and you are not clear then you can always go ahead and open a support case with us so that a technical expert can take a closer look and help.
Let me know if you need anything else.
Enter your E-mail address. We'll send you an e-mail with instructions to reset your password.




 Enable Microsegmentation.
Enable Microsegmentation. .
.