Hi All,
I’ve testing old Nutanix NX box demo with no MA support. The AOS version install is 5.10.6
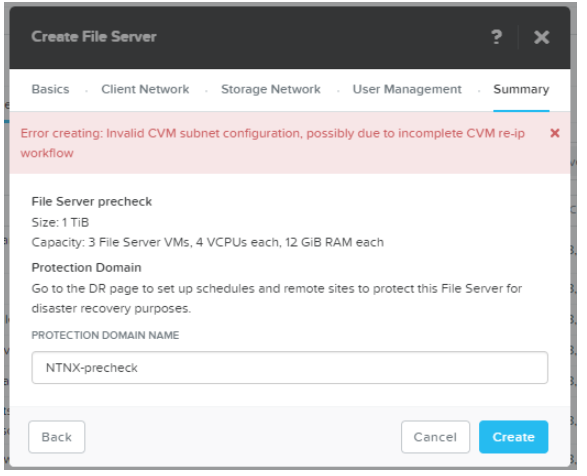
I tried to create file server using wizard in prism element.
In the last step of wizard when I prompt create the error message showing
Error creating: Invalid CVM subnet configuration, possibly due to incomplete CVM re-ip workflow
I’ve run ncc check and didn’t found subnet mismatch issue.
Please kindly advice how to fix this.