


This post was authored by Marc Waldrop, Principal Product Manager, Files, Eric Wang, Staff Engineer, Files, Anish Jain, Senior Technical Manager, Business Continuity and Disaster Recovery
Way back in a time long, long ago (okay, not that long ago), we released Nutanix Files Storage version 4.4. With that release, we introduced our first support for Files Storage running in a Metro cluster configuration. At that time, the release only supported Nutanix Files Storage running in a Metro cluster configuration with the VMware ESXi hypervisor. If you are interested - shameless plug for an earlier blog on this subject - you can read more about that HERE.
Being a software-defined data services offering and Nutanix having this other hypervisor, a few people may have heard of named AHV, we still had a little work to do. So we hammered away on the keyboard, worked day and night, drank endless amounts of soda, and ate more pizza than we are comfortable admitting to. Through lots of hard work and cross collaboration between the Files Storage and BCDR (business continuity and disaster recovery) teams here at Nutanix, we are proud to announce that we have circled that square, dotted that “i”, crossed that “t” and got our ducks in a row to bring you the ability to run Files Storage on our AHV hypervisor in a Metro configuration with synchronous replication.
The blog will walk through key technical details of what we built. We will be peeling back the onion and diving deep into the weeds to give you a behind-the-scenes look at how our Metro offering helps support high-availability use cases. However, before we do, let's talk about “Why Metro”. The why begins with understanding business needs. There are a number of businesses and industries that are considered mission-critical, requiring both data and applications that are replicated and protected at a level that ensures high levels of protection and availability. Some of these industries include banking, capital markets, insurance, healthcare, and emergency life support services. Industries where uptime is key for the business to function unhindered. Businesses where the cost of data loss and unavailability can be measured in minutes, impacting $10s to $100s of thousands of dollars. Typically, these businesses require features like synchronous replication and RPOs of zero for both data and applications. Combined with recovery times (RTO) as low as possible. This is where Metro solutions and synchronous replication come into play.
To get started, let's first walk through what makes up a file server on the Nutanix Cloud Platform solution. We start out with a set of highly available File Server virtual machines (FSVMs) that get deployed on the Nutanix platform. These FSVMs are backed by a few virtual entities, namely virtual disks (vdisks) and Volume Groups or VGs (a grouping of vdisks). These entities are then mounted to the FSVMs. The FSVMs are then aggregated together to form a single namespace that becomes the file server name the end users access (i.e., \\files.hq.com). As users mount exports or map drives to the shares, the data written to the file server is stored within these entities.
When focusing on disaster recovery and data availability with synchronous replication, the need to protect these entities that make up the file server is where a Metro cluster configuration comes into play. It is accomplished through creating a synchronous replication relationship using AHV Metro Availability for VMs and VGs. Internally, this translates to using our entity-centric disaster recovery capability, leveraging protection policies with RPO 0 and recovery plans for orchestrating the protection and recovery at entity-level granularity.
When Metro is configured, whether for Files Storage or user application VMs, we are synchronously replicating the entities themselves. With the assistance of the Nutanix Witness Service feature and the Prism Central (PC) multi-cluster manager, when a failure is detected that results in the primary cluster becoming unavailable, all file server entities will be brought up on the cluster configured as the secondary site.
With that understanding, what follows is a deep dive into more technical details. We will cover what happens when failure or service-impacting events arise. These events can range from one side of the relationship going offline, whether planned or unplanned, to the link between primary and secondary going down / offline, or the management layer, i.e., Prism Central, not being available. So, without further delay, let's dive in!
Failure Scenarios
To fully explain how the solution works end-to-end, let's examine some common failure scenarios and see how the system maintains high availability.
For the above exercise, let’s consider a typical deployment scenario:
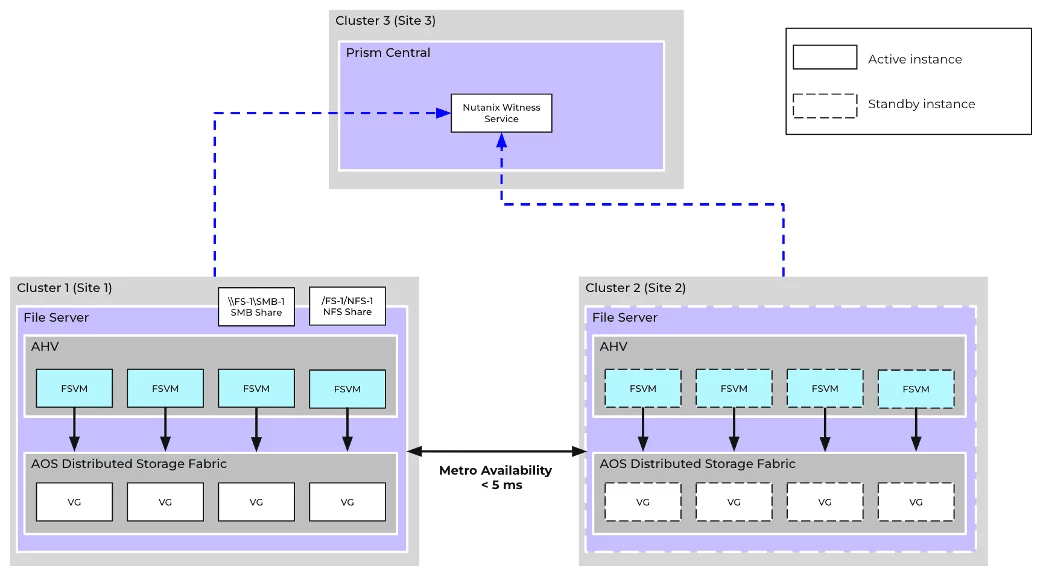
The deployment spans across 3 different sites:
- Cluster 1 on Site 1 hosts the active Files Storage instance, which consists of Files Server VMs (FSVMs) deployed across different nodes of the cluster, consuming Volume Groups (VGs) backed by the AOS distributed storage fabric.
- Cluster 2 hosts replicas of the FSVMs, VGs, and required data and metadata for consumption in the case of disasters. These resources are offline and will be promoted (started) when a service-impacting event (planned or unplanned) on Site 1 impacts the active file server availability.
- Cluster 3 hosts:
- Nutanix Witness Service: A component that provides tie-breaker functionality in the case of network partitions to ensure that only one instance of the file servers is active at a time. As a part of this deployment, the Witness service is hosted inside the Prism Central
- Nutanix Prism Central: The management plane responsible for overseeing components managed across sites. It is typically a centralized management service that provides visibility, configuration, and monitoring capabilities
In the scenarios below, the file server will be active on Cluster 1 to begin with.
Scenario #1: Production Site (Site 1) Failure
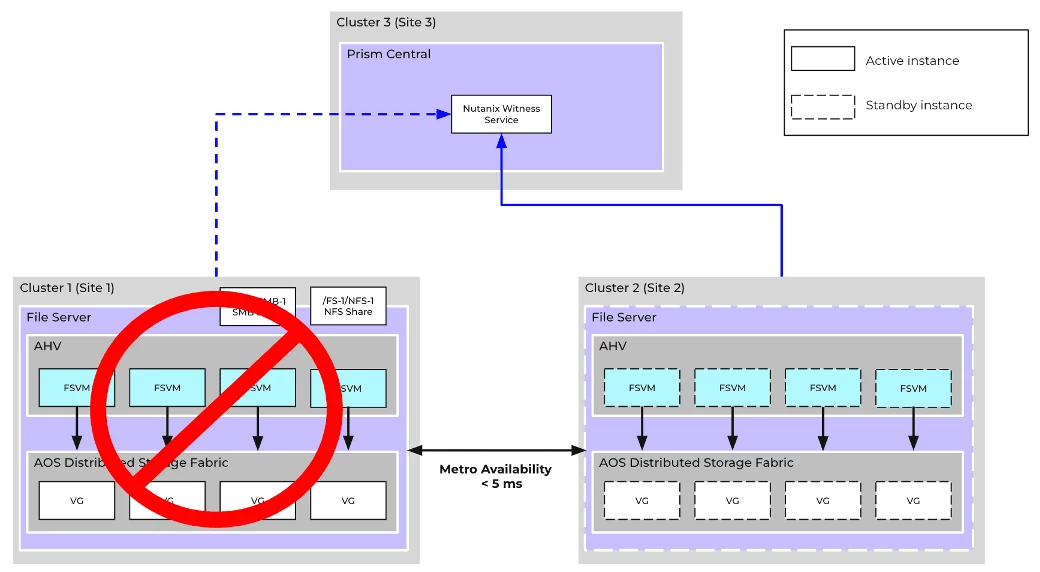
Recovery Procedure
- Each cluster should be in active Metro availability with data available on both clusters before the outage occurs.
- Cluster 2 detects an outage on Cluster 1 due to heartbeat failures
- After the user-configured timeout (default = 30 secs), Cluster 2 will attempt to acquire exclusive ownership of the file server via the Witness Service and succeed.
- Unplanned failover is initiated on Cluster 2
- This results in the file server on Cluster 2 becoming independent and no longer in synchronous replication, with all further updates persisted locally
- Once all file server entities (FSVMs + VGs) have failed over, the file server is promoted (activates and starts).
- After the file server completes initialization, the shares and exports will be accessible to clients again.
- No administrative operations are necessary.
- When Cluster 1 recovers later, synchronous replication is automatically re-established for the file server, and any delta changes are synced to get back into metro availability.
- As a part of the above process, the now stale FSVMs and VGs on Cluster 1 are automatically cleaned up since the file server is now active on Cluster 2
Scenario #2: Network Partition between sites, but both sites can access the 3rd site
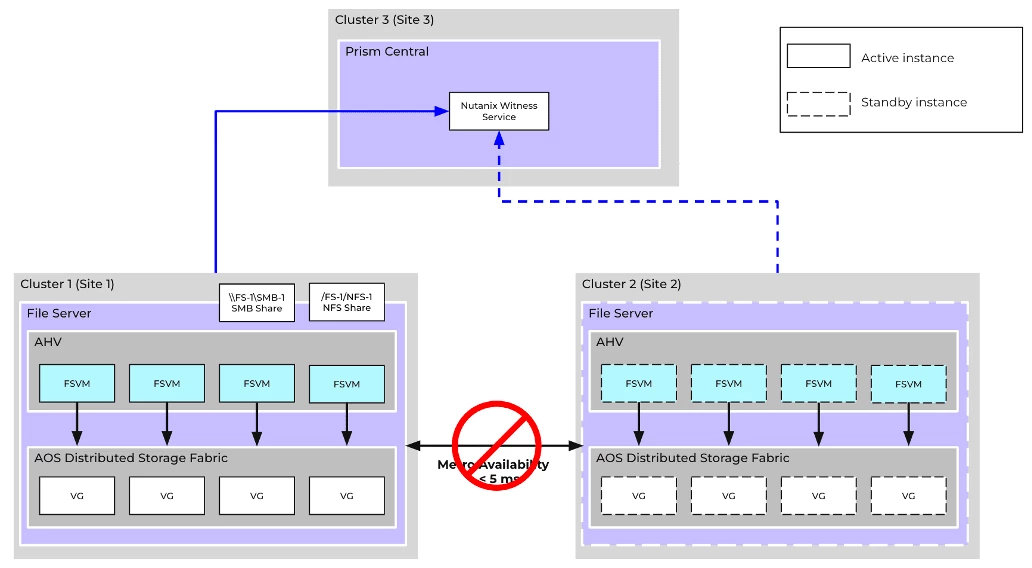
Recovery Procedure
- Cluster 1 and Cluster 2 will consider the other as not reachable due to heartbeat failures
- After the user-configured timeout (default = 30 secs), both clusters will attempt to claim exclusive ownership of the file server via the Witness Service
- Witness Service will resolve the tie, and the winner (in this case, Cluster 1) will become the exclusive owner of the file server
- Synchronous replication will be paused on Cluster 1, and all further updates to the file server entities (FSVMs + VGs) will be persisted locally
- No administrative operations are necessary
- Once the network partition is resolved, the administrator can manually resume synchronous replication on the file server to get it back into metro availability. This can be done through Files UI on PC.
Scenario #3: DR Site Failure
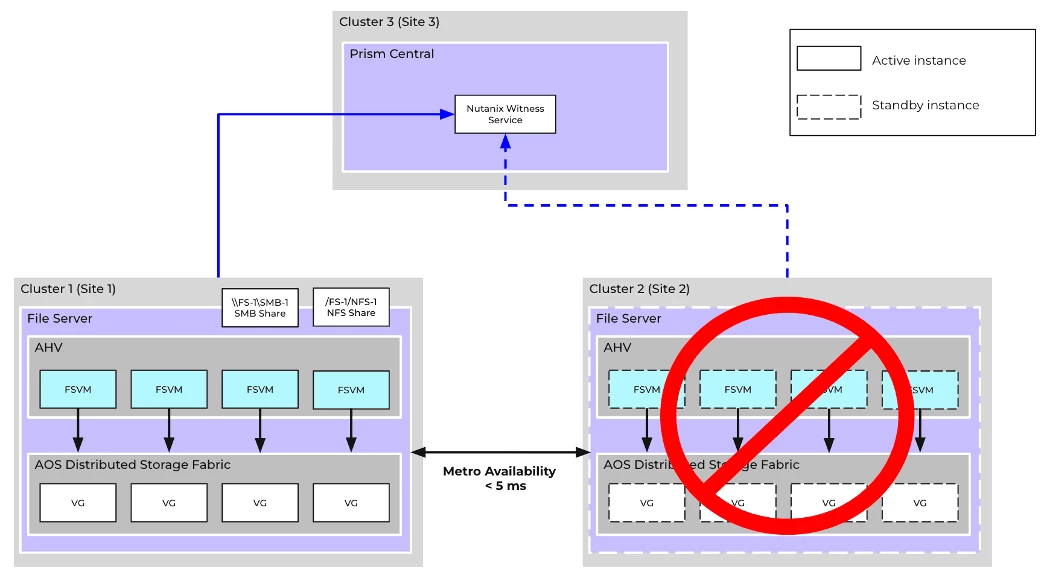
Recovery Procedure
- Cluster 1 detects an outage on Cluster 2 due to heartbeat failures
- After the user-configured timeout (default = 30 secs), Cluster 1 will attempt to claim exclusive ownership of the file server via the Witness Service and succeed
- Synchronous replication will be paused on Cluster 1, and all further updates to the file server entities (FSVMs + VGs) will be persisted locally
- No administrative operations are necessary
- Once the network partition is resolved, the administrator can manually resume synchronous replication on the file server to get it back into Metro availability. This can be done through Files UI on PC.
Scenario #4: Production Site Network Isolation
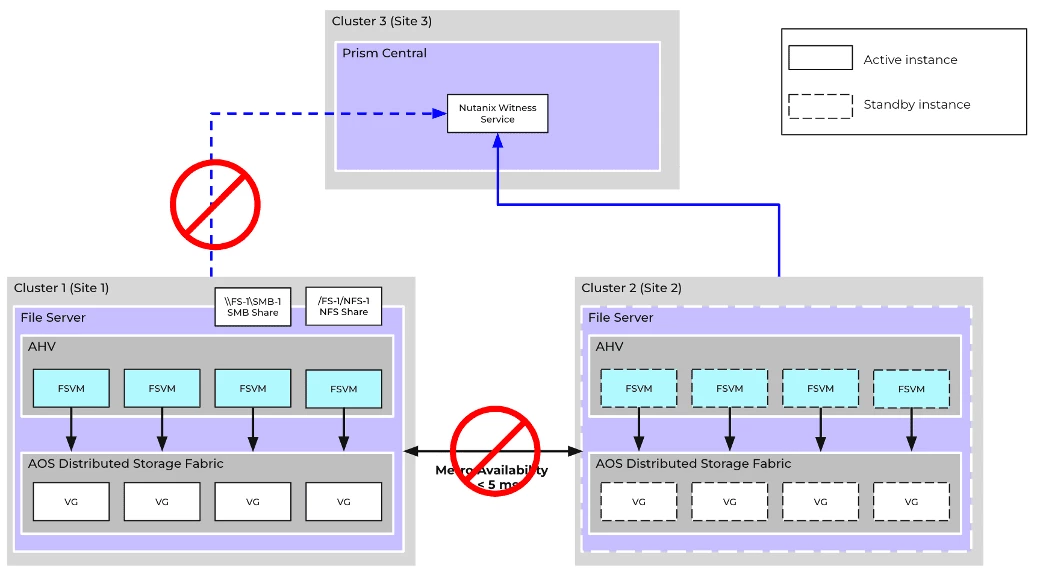
Recovery Procedure
- Cluster 1 and Cluster 2 will detect heartbeat failures from their respective peers.
- Cluster 1 and Cluster 2 will both periodically attempt to contact Witness Service on Cluster 3
- However, Cluster 1 will be unable to reach the Witness Service for a sustained period and will pre-emptively revoke storage access to the file server entities (FSVMs + VGs)
- This action is taken to prevent the file server from being accessible from both clusters simultaneously
- The FSVMs will be powered off
- After the user-configured timeout (default = 30 secs), Cluster 2 will acquire exclusive ownership of the file server via the Witness Service and initiate an unplanned failover
- This results in the file server on Cluster 2 becoming independent and no longer in synchronous replication, with all further updates persisted locally.
- Once all file server entities have failed over, the file server is promoted (activates and starts).
- After the file server completes initialization, the shares and exports will be accessible to clients again.
- No administrative operations are necessary
- If Cluster 1 recovers later, synchronous replication is automatically re-established for the file server, and any delta changes are synced to get back into metro availability.
- As a part of the above process, the now stale FSVMs and VGs on Cluster 1 are automatically cleaned up since the file server is now active on Cluster 2
Scenario #5: Prism Central outage
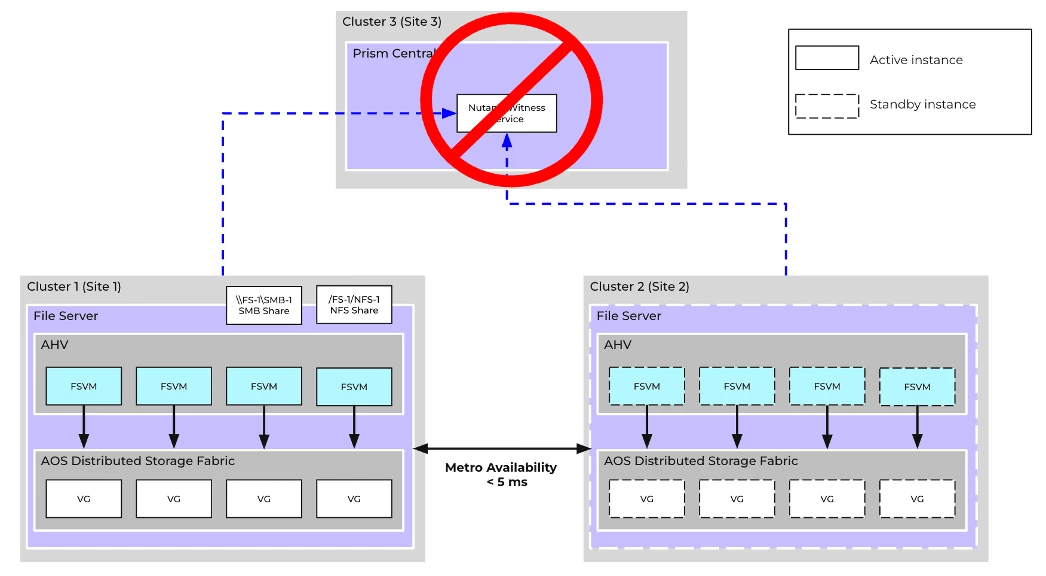
If Cluster 3, which hosts the Witness Service, experiences an outage, there is no impact on existing file server workloads. They will continue to operate.
However, if another failure occurs alongside the outage, such as a network partition between Site 1 and Site 2, it would impact the running workloads and the file server could experience downtime.
Final Thoughts / Wrapping Up
There is more to all of this, but we hope this gives you a good idea of how it all works. For more information, check out our documentation on Metro Availability and Files Storage on the Nutanix customer portal. From the above-mentioned blog on Files Metro on VMware ESXi, we included a chart highlighting the different data replication and synchronization capabilities. We are including it here again because it helps to know what is what.
|
| PD Based DR | Smart DR | Metro Cluster / Synchronous Replication | Smart Sync |
| Data Services Granularity | File Server | File Share | File Server | Folder Path within a share |
| Data Management | Asynchronous | Asynchronous | Synchronous | Asynchronous |
| Use Case | File Server DR | File Server DR at a Share level | File Server HA | Data consolidation / Backup / VDI Profile sync |
As you can see from the above, Nutanix Files Storage offers several options to provide data services that ensure high availability and recoverability for unstructured data storage. If you have been waiting for this or anything else within our unified storage offering, don’t hesitate to reach out to your local Nutanix or Partner account team! We are certain they would love to walk you through in more detail what is possible.
Additional Resources
- Nutanix Unified Storage Product Page
- Business Value of Nutanix Unified Storage - White Paper
- Evaluate ROI/TCO of deploying Nutanix Unified Storage for your business - Access the ROI tool.
- Test Drive: Test Drive Unified Storage
- Videos: YouTube Playlist
© 2025 Nutanix, Inc. All rights reserved. Nutanix, the Nutanix logo, and all Nutanix product, feature and service names mentioned herein are registered trademarks or trademarks of Nutanix, Inc. in the United States and other countries. Nutanix, Inc. is not affiliated with VMware by Broadcom or Broadcom. VMware and the various VMware product names recited herein are registered or unregistered trademarks of Broadcom in the United States and/or other countries. Other brand names mentioned herein are for identification purposes only and may be the trademarks of their respective holder(s). This post may contain links to external websites that are not part of Nutanix.com. Nutanix does not control these sites and disclaims all responsibility for the content or accuracy of any external site. Our decision to link to an external site should not be considered an endorsement of any content on such a site. Certain information contained in this post may relate to or be based on studies, publications, surveys and other data obtained from third-party sources and our own internal estimates and research. While we believe these third-party studies, publications, surveys and other data are reliable as of the date of this post, they have not independently verified, and we make no representation as to the adequacy, fairness, accuracy, or completeness of any information obtained from third-party sources.