


This blog was authored by Gourab Baksi Principal Product Manager Nutanix
This first blog in the three-part series on Metro Availability for AHV focuses on how to achieve zero data loss with Protection Policies in Prism Central at VM granularity.
For mission-critical applications in various industry sectors like banking, capital markets, insurance, healthcare, and emergency life support services, 24x7x365 uptime is key for the business to function unhindered. In such cases, applications need to have transparent visibility into underlying IT infrastructure failures, including hardware components (disk, network cards, power supply), racks, clusters, or sites. A 2014 Gartner study puts the cost of downtime at $5,600 per minute and can go as high as $540,000 per hour for mission-critical applications.
One of our core principles at Nutanix is to ensure the continuous availability of data for all applications running on the platform. To achieve seamless business continuity, we have built High Availability and Data Protection right into our AOS platform with the assumption that the hardware components are prone to failure. While this prevents customers from experiencing component failures in a cluster, what happens when entire clusters go down? The answer is Metro Availability. Metro Availability will extend the realm of continuous availability to another cluster. Customers can configure their deployments to seamlessly keeping mission-critical applications online even in the case of entire site failures.
The Journey to Metro Availability on AHV
As Nutanix AHV continues to rapidly gain adoption across all verticals and their mission-critical workloads, offering business continuity with Metro Availability is essential.
Our goal with Metro Availability on AHV is to build a 0-RPO (zero data loss), 0-RTO (transparent failovers), and 0-Touch (Witness) driven HA solution for all Nutanix workloads: VMs, Volumes, Files, and Calm Apps.

Metro Availability on AHV will be the sum of three parts:
- 0 RPO - Synchronous Replication: Synchronous replication of VM data, metadata, and associated policies, including Flow and Calm blueprints.
- 0 RTO - Cross-cluster Live Migration of VMs: Live migration of VMs and Volumes across clusters. The orchestration of live migration along with the associated environment is carried out by Recovery Plans.
- 0 Touch - Witness orchestrated automated failovers: A witness to monitor for failures of fault domains and arbitrate a fault domain for business continuity upon failure.
Our journey to this vision will be delivered in three phases, with 0-RPO in the first phase followed by 0-RTO and 0-Touch following thereafter.
0 RPO - Synchronous Replication
To provide continuous availability of data, achieving zero data loss is imperative. This involves maintaining a second copy of all data i.e. VM data, VM attributes and policies applied to VMs across two clusters in two different fault-domains/sites.
In this phase, the following features will be available:
- Synchronous replication at VM granularity with Protection Policies.
- Failovers (planned and unplanned) with Recovery Plans.
- Backup ecosystem support for VMs protected by synchronous replication
Achieving 0-RPO with 1-click Protection Policies
Traditional 3-tier MetroCluster solutions are complex to design, deploy, and maintain—often defeating the primary goal of continuous availability they were built for. At Nutanix, our fundamental design principle is simplicity, and we want users to be able to deploy, monitor, and leverage synchronous replication for VMs at scale from a single pane of glass without having to learn the complex constructs of stretched clusters that traditional approaches have forced on them in the past. With Protection Policies in Prism Central, we have made it easy to configure the RPO of your choice for any VM(s) across multiple AHV clusters with the use of constructs like categories.
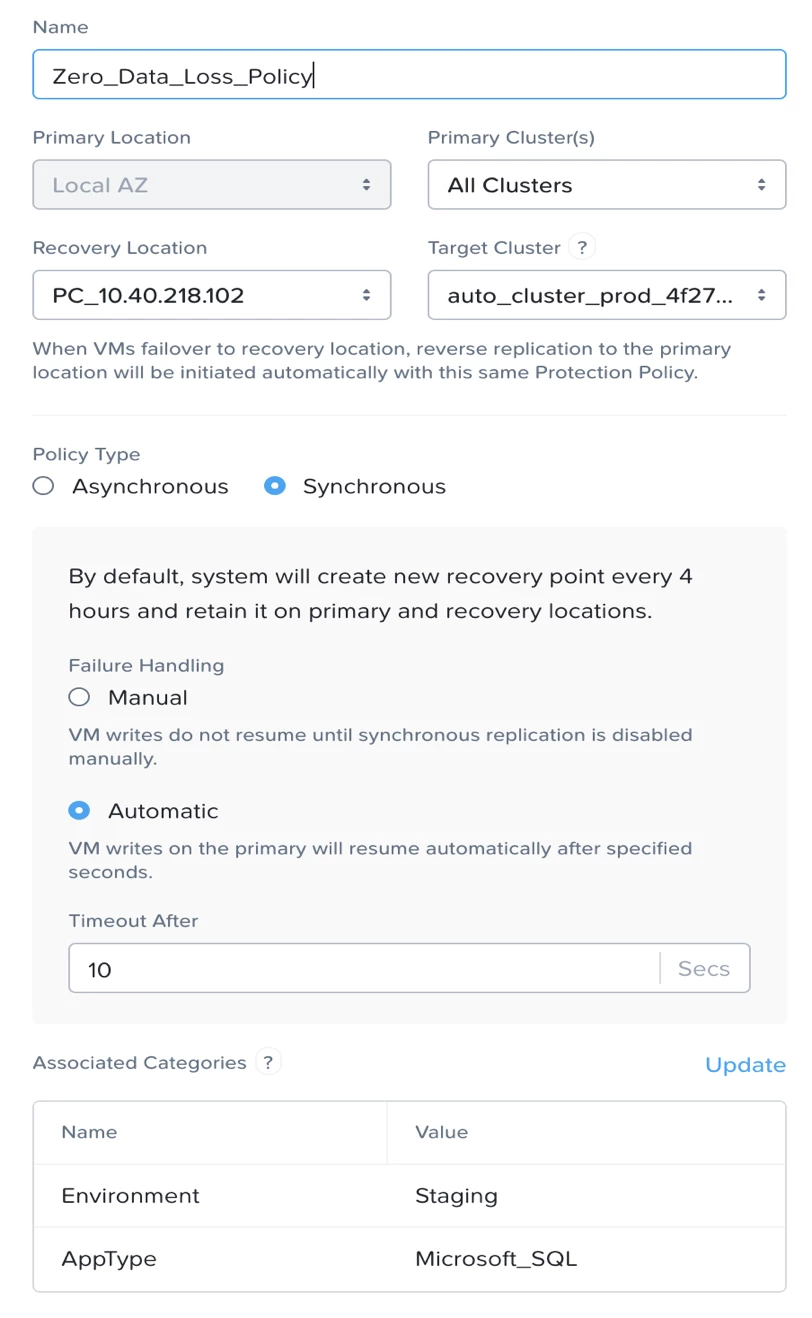
To protect VMs with synchronous replication, you will have to provide the following information in the Protection Policy:
- Recovery Cluster: Name the cluster in a different fault domain from which you want to synchronously replicate and failover your VMs transparently in a DR scenario.
- Replication Policy: To set up synchronous policy for your VMs, just choose the radio button with the synchronous option. The nature of synchronous replication requires two clusters being operational at the same time because writes have to be in sync. However, there can be scenarios where the recovery cluster is down or network connectivity is lost between two sites. In such scenarios, for the application to continue, unhindered users can choose to isolate the primary from the secondary manually or automatically after a specified time.
- Categories: Last but not least, we have focused on making the tedious and error-prone job of protecting VMs simple with categories. Once you have added a particular category to a Protection Policy, every VM that is tagged with the same category is immediately protected by the policy that protects that category. This means you can now auto-protect VMs as and when they are spun up by just simply adding a category to the VM either in Prism or via API.
Monitoring Synchronous Replication
Once you have set up synchronous replication for your mission-critical VMs, we have made it incredibly easy to know the state of your protection with a very simple, VM-centric view.

Fortify Your DR Strategy with Recovery Plans
Enterprise applications are often complex, involving multiple tiers and strict dependencies between in-guest application services spanning multiple VMs. Bringing up such applications during recovery means splitting them into multiple stages in sequence. Often even more intricate controls need in-guest script execution to start and verify various services, adding delays between the stages.
Additionally, when users want to perform a disaster recovery drill to measure their DR readiness, they want zero impact on the production environment. This means the DR solution has to provide the ability to map different networks for DR testing, which are isolated from production networks that are used for planned and unplanned failovers.
All of the above can be achieved with Recovery Plans in Prism Central. Every execution of a Recovery Plan gives you detailed insights and reports that can be shared across the organization for analysis, audit, and compliance purposes.
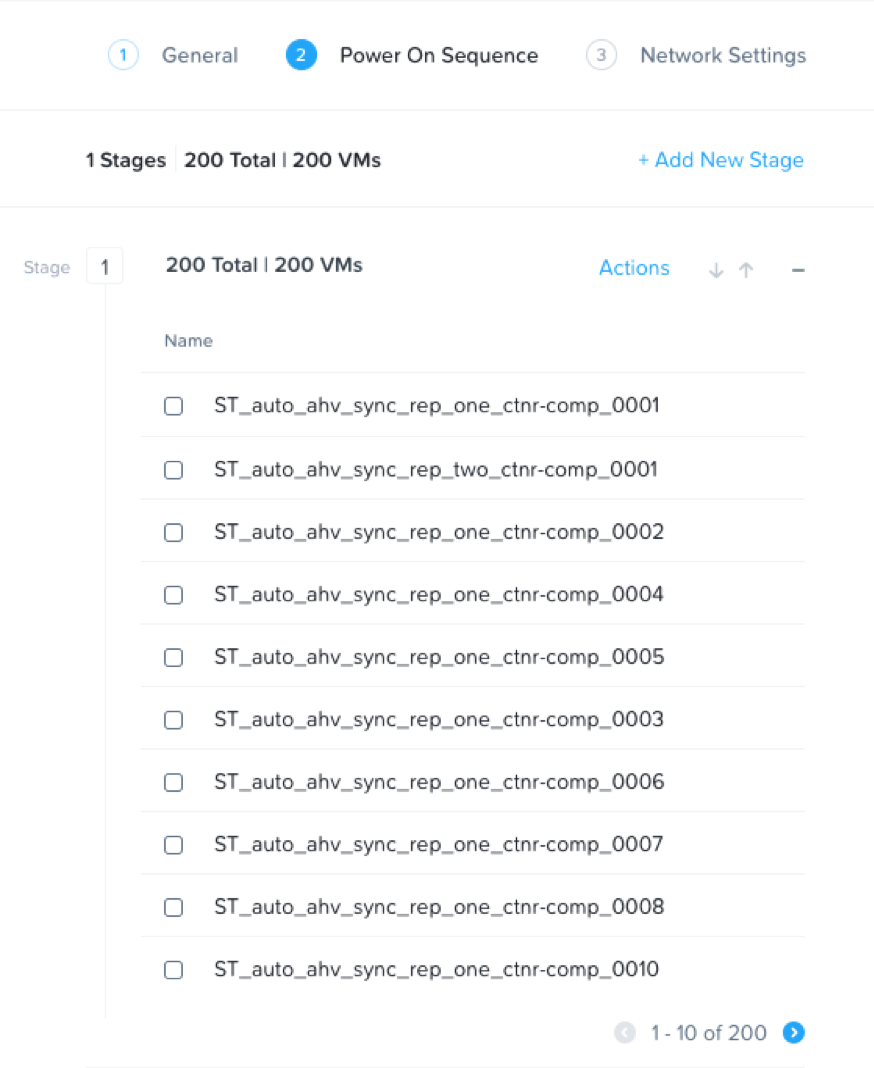
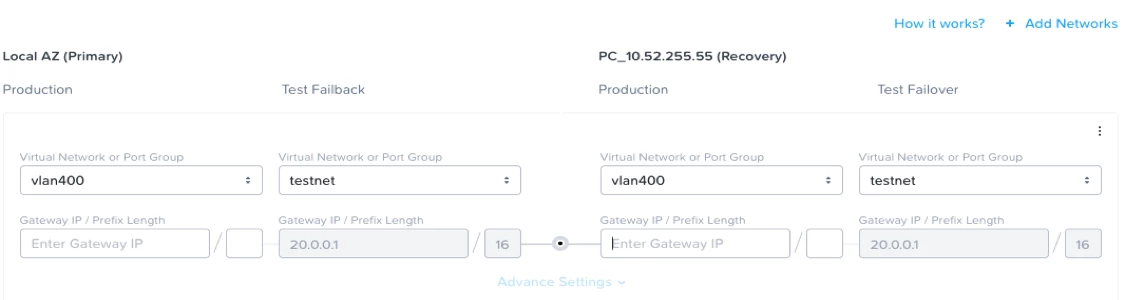
Handling Disasters is Now Simple
In the event of an actual disaster, users can leverage these powerful Recovery Plans to recover applications without any data loss using the synchronously replicated data on the recovery cluster with just a few clicks.
Just choose the Recovery Plan and select unplanned failover from the latest Recovery Point and watch your VMs boot in the specified order while you relax with confidence.
A Strong Backup Ecosystem Done Right
With the evolution of AHV, we have built a strong ecosystem with our backup partners: Commvault, Veritas, Veeam, and HYCU. Our backup ecosystem was built on a strong foundation of change-block-tracking APIs that ensure fast and efficient backups that leverage our data-locality capabilities as well as the incremental nature of our native snapshots. This eliminates the needs of any backup agents to be run inside VMs, thus offloading all the heavy-lifting data path tasks during the backup window to AOS.
All AHV VMs protected by synchronous replication will also be protected by backup software leveraging these existing change-block-tracking-APIs.
What’s next?
If you are interested in taking AHV Synchronous Replication feature for a test-drive and experiencing its zero data loss capabilities, please reach out to your local Nutanix Sales team and we will be happy to give you a sneak peek of what we are building. Stay tuned for our second blog in this series, which will demonstrate the ability to seamlessly move VMs protected by synchronous replication across AHV clusters with Recovery Plans.
Forward Looking Statements
This blog includes forward-looking statements concerning our plans and expectations relating to new product features and technology that are under development, including Metro-Availability on AHV, the capabilities of such product features and technology and our plans to release product features and technology in future releases. These forward-looking statements are not historical facts, and instead are based on our current expectations, estimates, opinions and beliefs. The accuracy of such forward-looking statements depends upon future events, and involves risks, uncertainties and other factors beyond our control that may cause these statements to be inaccurate and cause our actual results, performance or achievements to differ materially and adversely from those anticipated or implied by such statements, including, among others: the introduction, or acceleration of adoption of, competing solutions, including public cloud infrastructure; a shift in industry or competitive dynamics or customer demand; and other risks detailed in our Annual Report on Form 10-K for the fiscal year ended July 31, 2019, filed with the Securities and Exchange Commission, or SEC, on September 24, 2019. Our SEC filings are available on the Investor Relations section of the company’s website at ir.nutanix.com and on the SEC’s website at www.sec.gov. These forward-looking statements speak only as of the date of this blog and, except as required by law, we assume no obligation to update forward-looking statements to reflect actual results or subsequent events or circumstances.
 2019 Nutanix, Inc. All rights reserved. Nutanix, the Nutanix logo and the other Nutanix products and features mentioned herein are registered trademarks or trademarks of Nutanix, Inc. in the United States and other countries. All other brand names mentioned herein are for identification purposes only and may be the trademarks of their respective holder(s). This blog contains links to external websites that are not part of Nutanix.com. Nutanix does not control these sites and disclaims all responsibility for the content or accuracy of any external site. Our decision to link to an external site should not be considered an endorsement of any content on such a site.
2019 Nutanix, Inc. All rights reserved. Nutanix, the Nutanix logo and the other Nutanix products and features mentioned herein are registered trademarks or trademarks of Nutanix, Inc. in the United States and other countries. All other brand names mentioned herein are for identification purposes only and may be the trademarks of their respective holder(s). This blog contains links to external websites that are not part of Nutanix.com. Nutanix does not control these sites and disclaims all responsibility for the content or accuracy of any external site. Our decision to link to an external site should not be considered an endorsement of any content on such a site.



