Hello Nutanix Community,
I’m reaching out for help after spending a significant amount of time troubleshooting an issue where a Nutanix cluster cannot complete initialization. I would truly appreciate any insight from the community, as I believe I have exhausted all standard troubleshooting paths.
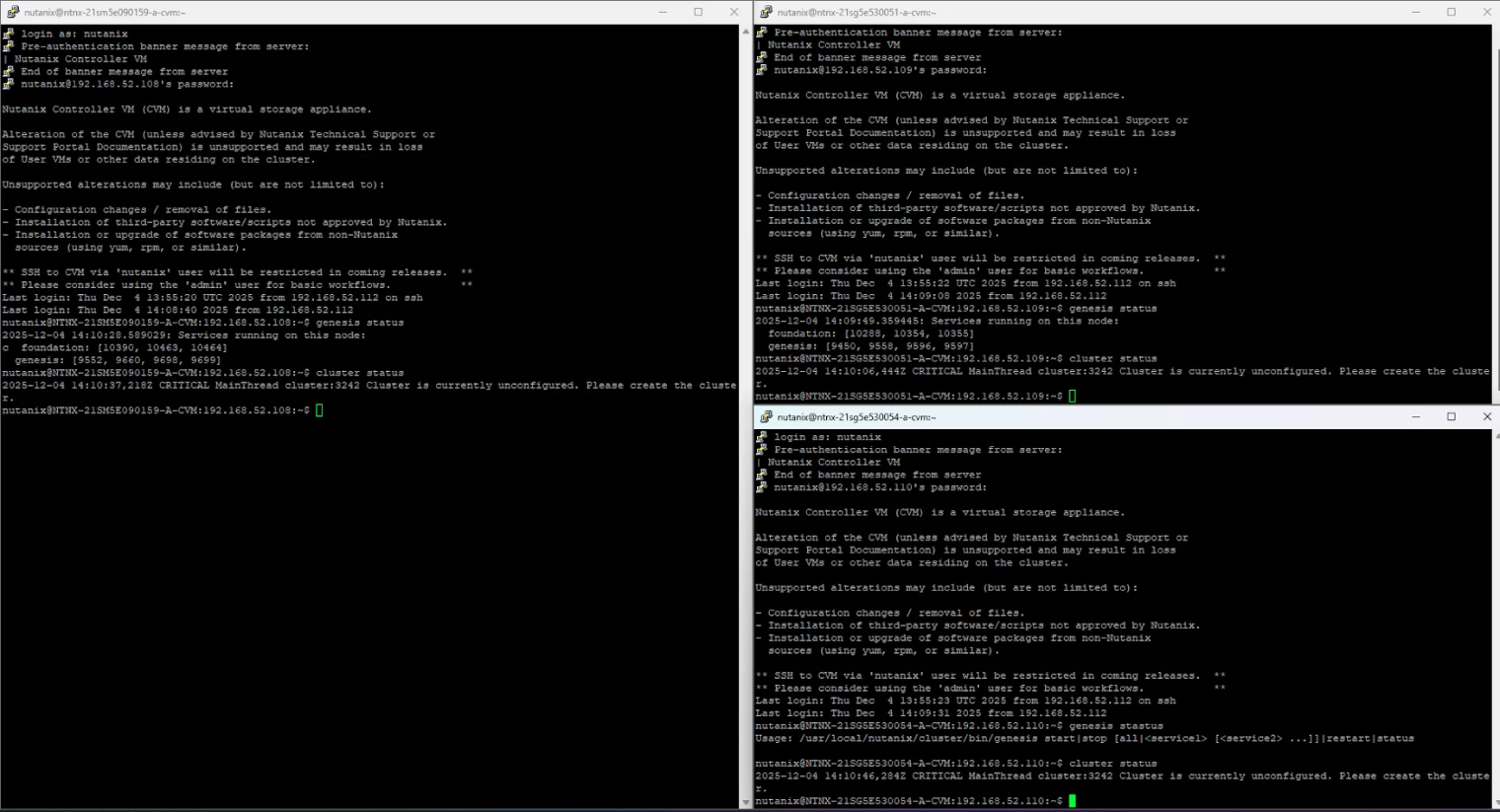
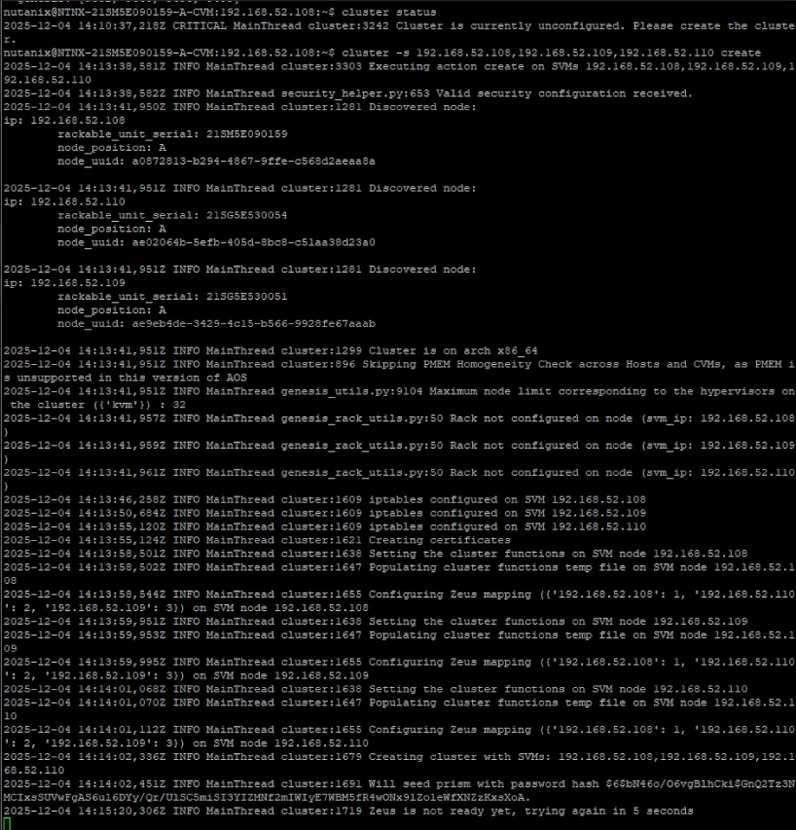
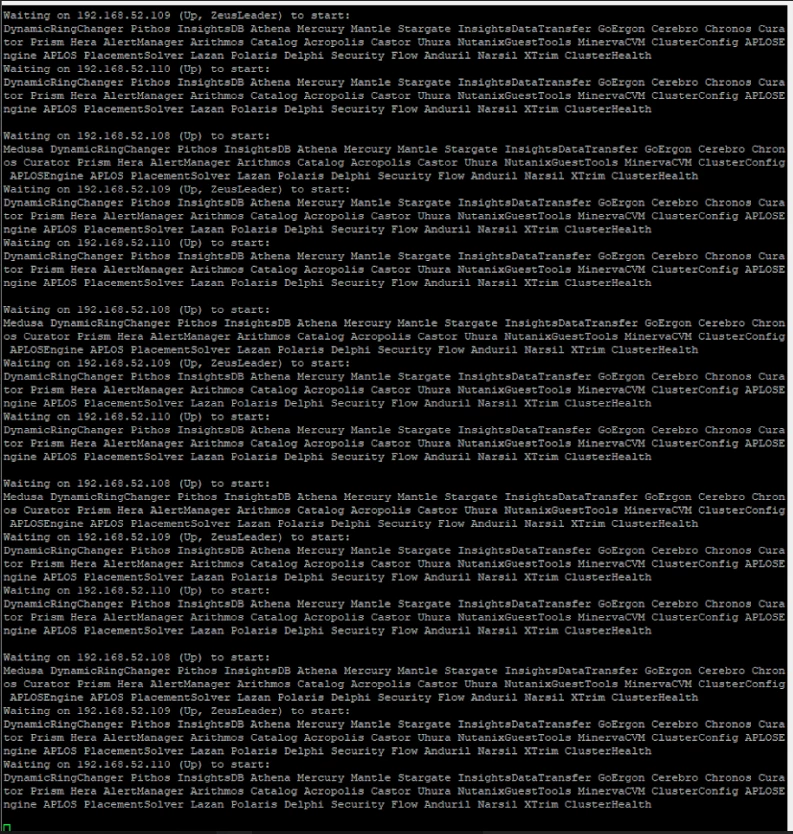
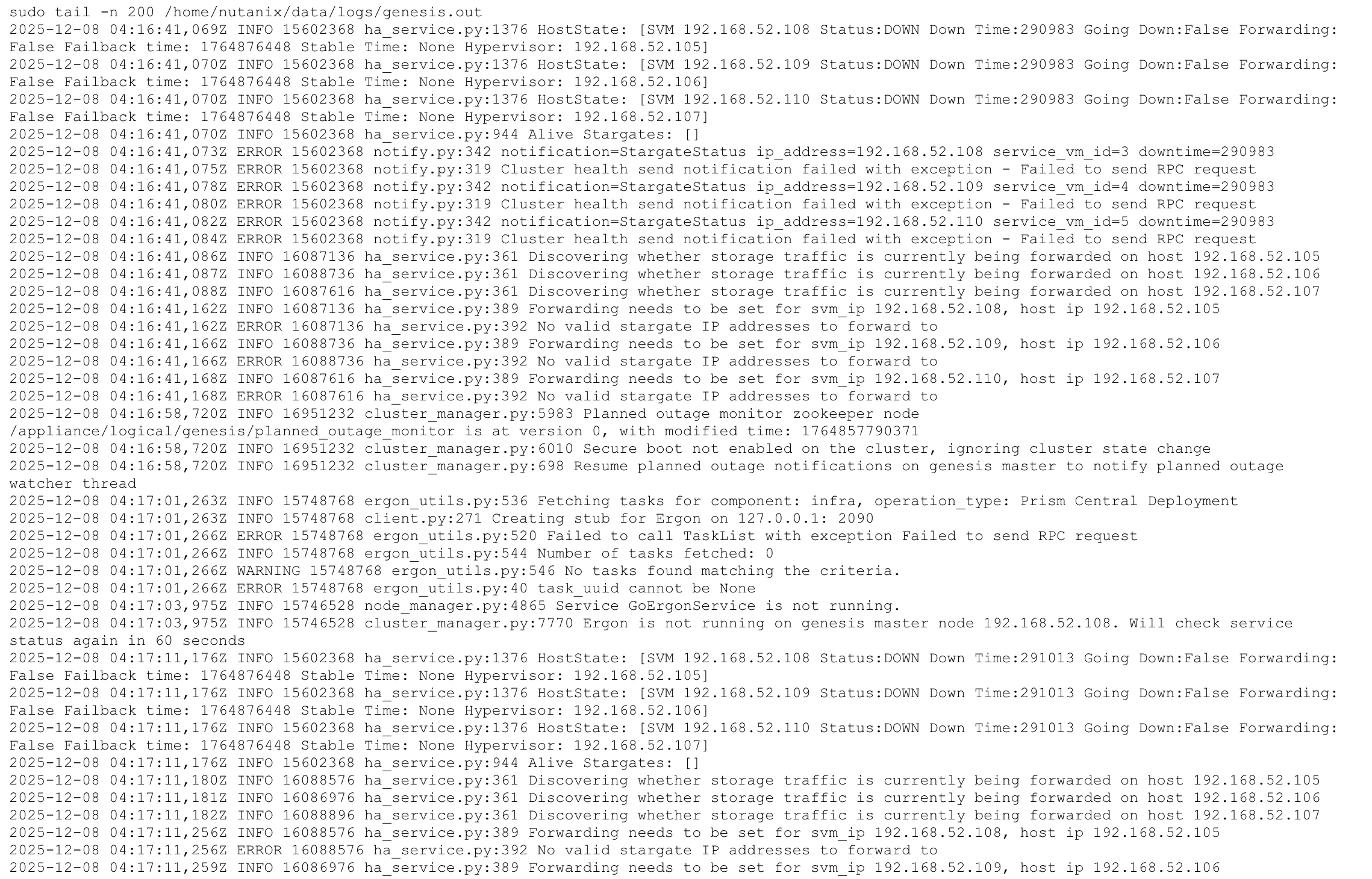
This cluster was previously created successfully and had been running in production without issues.
However, due to security-related changes in our IT infrastructure, we were required to re-address the entire environment, including:
-
CVM IPs
-
Hypervisor IPs
-
IPMI IPs
Because of this requirement, I intentionally chose the cleanest and officially recommended approach, which was:
-
Reclaim licenses
-
Stop the cluster
-
Destroy the cluster
-
Rebuild the cluster from scratch using Nutanix Foundation
This was not an accidental failure during a first-time installation.
The issue only started after performing a controlled teardown and reinstallation due to the IP address changes.
Support experience and request for community help
I have already contacted Nutanix Support in my region regarding this issue.
Unfortunately, I was informed that this case is considered out of scope, and therefore no further assistance could be provided.
I must say that this is deeply disappointing, as we have renewed Maintenance & Support (MA) every year and have always expected to receive full technical support when encountering critical issues such as this — especially on hardware and clusters that were previously running successfully.
At this point, I sincerely hope that the Nutanix community can help provide insight, guidance, or direction to resolve this problem.
Any advice, experience, or suggestion would be greatly appreciated.
Thank you very much in advance for your time and support.