
Nutanix Community Edition(CE)に関する話題はこちらへどうぞ。
Page 1 / 3
@smzksts お世話になっております。keroro9です。こちらこそreply気が付かずすみません。機材が実家にある関係で(VPN越しに触れはしますが)、あまり注力できていない現状はあります。それはされておき、状況についてご教示いただきありがとうございました。(非サポートとはいえ)こちらでも確認してみます。

Userlevel 4
 +9
+9
- Nutanix Employee
- 92 replies
-
22 November 2023
すみません反応が遅れてしましました。
CE 2.0ではESXiのサポートはやめておりまして、やめたとは言っても一つ前のバージョンの仕組みがそのまま入った形になっているので動く場合もあるのですが、当時からESXiでのインストールは正直なところ鬼門です。大概はESXiがディスクを認識した際のシリアルのフォーマットが多岐にわたることで、CVMへのパススルー(RDM)を設定するところで処理用のスクリプトが対応しきれず失敗しています。
↓の資料は一つ前のCEとESXi 6.7系で起きていた症状に対するものですが、どうやら7.0系以降でも発生する場合があるようなので、参考になるかもしれません。
https://speakerdeck.com/smzksts/nutanix-ce-5-dot-18-deep-dive?slide=58
(背景)
お世話になっております。keroro9と申します。業務ではスクラップ&ビルドが難しいので、個人の機材でいろいろやっております。普通にNutanixを入れるというところは到達できましたので、ハイパーバイザをESXi(+vCenter)で動かせないかと思い実験しています。
(現象)
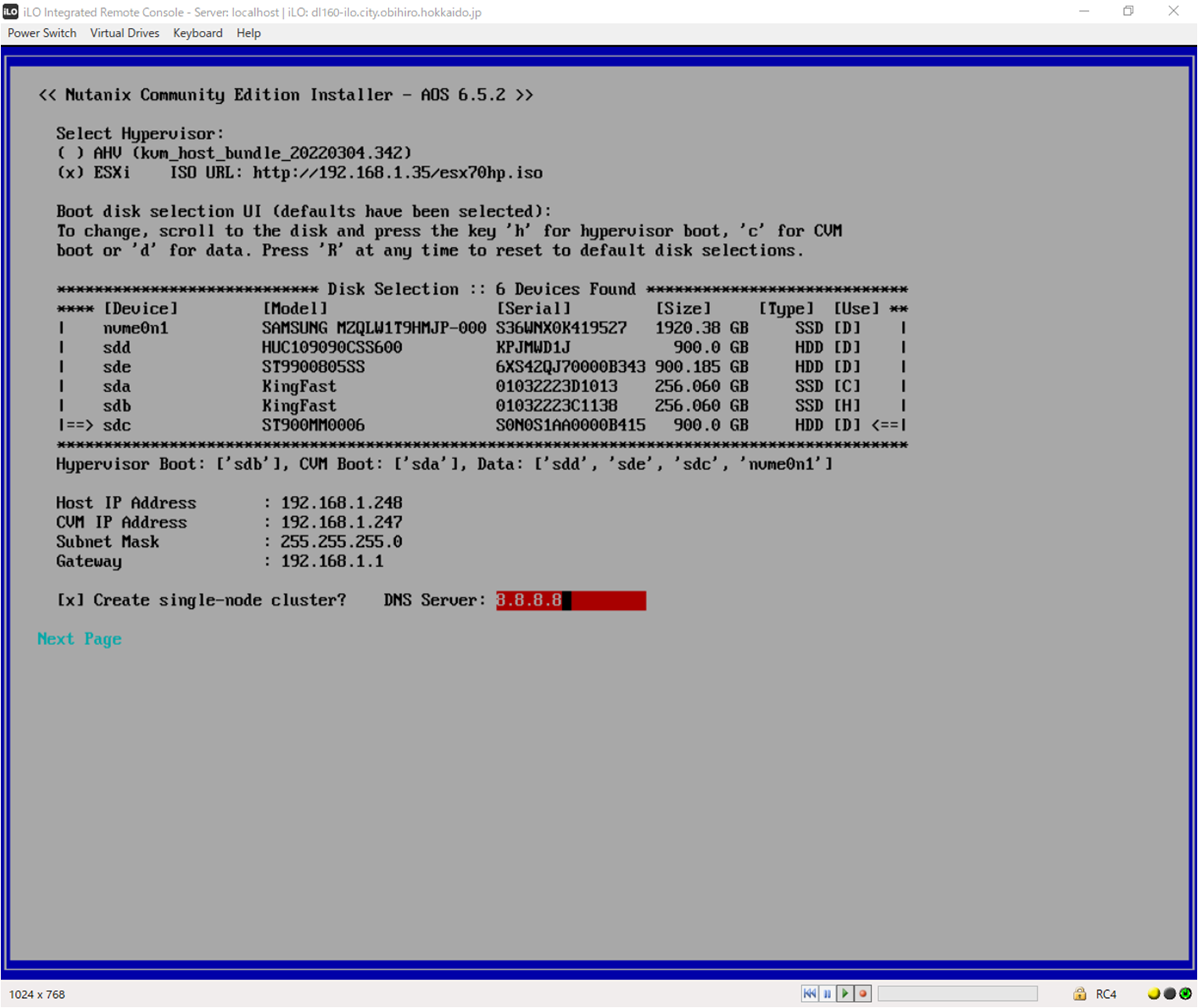
phoenix-ce2.0-fraser-6.5.2-stable-fnd-5.3.4-x86_64.iso を用いて、ESXiのISOはVMware-ESXi-7.0.3-22348816-HPE-703.0.0.11.5.0.6-Oct2023.isoを用いて検証を行っております。インストーラは正常終了し、その後ESXiが起動。何度か再起動を繰り返し、インストール進捗に応じてCVMのVM名が変更されます。しばらく待つとFailed-installとVM名が変わります。この時、ストレージは
NTNX-local-ds-038819d1-Aというものができていますが、本来期待した容量よりはるかに小さく、正常に生成されていないと考えられます。
(お伺いしたい事)
・まず前提のログ調査などが行えていません。皆様にお伺いする際にざっと見たほうが良いログの調査方法、場所などご教示いただけませんか。
・一般的な知見において、Failed-installに落ちてしまう原因があれば教えてください。
(環境情報)
ProLiant DL360 Gen9
CPU E5-2690 v4 @ 2.60GHz *2
メモリ 128GB
SSD KingFast 256GB*2
SAS HDD 900GB*3
NVMe SSD 2TB
インストール時の構成は下記のとおりです。
お世話になります。
勉強のためにNutanixCEを触り始めようと、ESXi上にNutanix CEを建てようとしておりますが、
以下の問題で躓いております。
Nutanix CE 2.0 よろず相談所側に書き込みしようと思いましたが
コメント書き込みがクローズしているようなので、こちらで投稿いたします。
お知恵をお借りできないかと思い書き込みさせていただきました。
何卒よろしくお願いいたします。
■環境
・VMware ESXi7.0u3 上の仮想マシン
・vCPU:8core
ハードウェア アシストによる仮想化をゲスト OS に公開: ON
・vMem:64GB
・vDisk
32GB: H(Hypervisor Boot)
500GB:C(CVM Boot)
2000GB:D(Data)
・互換対象: ESXi 7.0 U2 以降(仮想マシン ハードウェア バージョン 19)
・ゲスト OS ファミリ: Linux
・ゲスト OS バージョン: CentOS 7 (64 ビット)
・最新のCEを利用
■発生している問題
上記構成で3台作ろうとしていて、それぞれ違う問題に直面しております。
それぞれシングルノード構成で作成しています。
1. CVMが起動してもサービスがなかなか上がらずPrismにアクセスできない
SSHではアクセスできますが、cluster statusを実行するも
WARNING genesis_utils.py:1199 Failed to reach a node where Genesis is up. Retrying... (Hit Ctrl-C to abort)
が出続ける。
2. CVMのサービスも全て上がり、PrismにアクセスOK
最低限の設定をして、仮想マシンの作成、LinuxのISOメディアのアップロード完了
仮想マシンを起動してもBIOS/UEFI上の画面で止まったまま進まない。(キー入力も受け付けない、CTRL+ALT+DELも受け付けない)
3. CVMのサービスも全て上がり、PrismにアクセスOK最低限の設定完了
ISOイメージをアップロードし、アップロード進むものの、Updateタスクがエラーとなり
ISOイメージが登録されない
解決方法があれば教えていただけないでしょうか。
お世話なります。
こちらのトピックのコメント受付がクローズされていたのでこちらに投稿させていただきます。
不適切でしたら申し訳ありません。
MinisforumというメーカーのPCにNutanix CEのインストールを試みておりますが、エラーが起きてしまっているため、皆様の知恵をお借りして解決を図りたいと思っております。
<発生している事象>
Nutanix CEのインストールが、screen is terminatingのメッセージを出力して開始されません。
screen is terminatingの前に出力されるFATALエラーのメッセージは下記の通りです。
FATAL: Couldn’t find a hypervisor and an AOS installed, please package phoenix with a hypervisor and a AOS. Please refer to KB-9010 if repair host boot device workflow is performed during an active AOS upgrade. Please refer to Nutanix support portal for more information about this.
<ハードウェア情報>
PC: Minisforum UM480XT(ベアボーンに下記メモリとストレージを搭載して利用)
CPU: AMD Ryzen 7 4800H
メモリ: DDR4 32GB 1枚
接続ストレージ: NVME SSD 500GB・SATA HDD 500GB・USB3.0Gen1 USBメモリ 32GB
インストールメディア: USB2.0 USBメモリ16GB
<その他捕捉情報>
- 当初こちらのURLと同じようにNICの認識がされませんでしたが、下記URLで共有されているigc.koを移送してロードすることで認識されました。ただし、認識されたに./ce_installer && screen -rを実行すると今度は上述のFATALエラーが出るようになりました。
- BIOSにてAMD-Vはenableになっていることを確認しました。
- インストールメディアに使用しているUSBメモリにはこちらのURLの手順と同等の手順で「phoenix-ce2.0-fraser-6.5.2-stable-fnd-5.3.4-x86_64.iso」を書き込みました。
問題の解決方法・切り分け方法がわかればご教示いただけるようお願いいたします。
Userlevel 4
+9
- Nutanix Employee
- 92 replies
-
28 April 2023
CEインストーラーのカーネルは普通の(アップストリームの)Linuxカーネルをそのまま使用しているので、お使いのデバイスが Linuxとの相性等でHDDとして認識されている可能性があります。参考までに、当該のSSDのメーカーおよびモデル名を共有していただくことは可能でしょうか?
LinuxカーネルレベルでSSD/HDDのどちらで認識されているかの確認方法
[Ctrl] + C でインストーラーを終わらせて、コマンドラインで
cat /sys/block/<デバイス名>/queue/rotational
を実行して出力される結果が0ならSSD、1ならHDDとして認識されている状態です。
ディスクタイプを強制認識させる方法
echo 0 > /sys/block/<デバイス名>/queue/rotational
とすれば無理やりSSDとして認識させられますので、これを実行した後に
./ce_installer && screen -r
でインストーラーを再度起動して、SSDとして認識させられていればインストールを続行できる可能性が高いと思います。
お手数ですがご返信は下記トピックの方に書き込んでいただけますと幸いです。
最新のCE2.0で試してみましたが、同じ現象が発生しています。
「Hypervisor、ディスク構成、IPの設定入力」画面で内蔵ディスクがHDDとして認識されて、CVMブートディスクがSSDである必要との条件に引っ掛かって、インストールが進めません。
ご返事いただき、ありがとうございます。
最新のCE 2.0で試してみます。
Userlevel 4
+9
- Nutanix Employee
- 92 replies
-
27 April 2023
2020.09.16は古いバージョンですので、もしよろしければ最新の CE 2.0で試してみて頂けませんでしょうか?
https://next.nutanix.com/discussion-forum-14/download-community-edition-38417
こんにちは!
NutanixCE(2020.9.16)のインストールについて、教えてください。
物理サーバー(DELL PowerEdgeR620)にインストーラをブートしてインストールしようとしていますが、
「Hypervisor、ディスク構成、IPの設定入力」画面で内臓ディスクがHDDとして認識されて、
CVMブートディスクがSSDである必要との条件に引っ掛かって、インストールが進めません。
・ディスク構成:
sda SSD1TB(CVMブートディスク) ※内臓
sdb SSD1TB(データ) ※内臓
sdc USB256GB(AHVブートディスク) ※外付け
sdd USB32GB(インストーラ) ※外付け
何か解決方法があれば教えていただけないでしょうか。
Userlevel 4
+9
- Nutanix Employee
- 92 replies
-
2 March 2023
【お知らせとお願い】
Nutanix CE 2.0リリースに伴い、CEに関する話題は新しいスレッドに移行したいと思います。
こちらのスレッドも残しておきますが、今後は Nutanix CE 2.0 よろず相談所 をご活用ください。
Userlevel 4
+9
- Nutanix Employee
- 92 replies
-
2 March 2023
SSDにWindowsのファイルシステムでフォーマットされたパーティションがあったのが原因と考えられます。パーティションを切っただけなら大丈夫です。
Hyper-Vを意味するようなメッセージが出る場合、Windowsで作成したパーティションが誤って読み込まれてしまっている場合が多いです。
sdaに相当するデバイスのパーティションを読み込んでそのように表示されているようなので、手動でパーティションを削除してからリトライしてみていただけますでしょうか。
ご説明頂きました通り、「mkfs -t ext4 /dev/sda」を実行したところ、インストールが進みました。
追加で質問ですが、中古のWindowsを購入したのですが、そのSSDにWindowsのパーティションがあったから?
それともパーティションが切られると同様のエラーが再現する?
以上、ご教示の程宜しくお願い致します。
Userlevel 4
+9
- Nutanix Employee
- 92 replies
-
20 February 2023
Hyper-Vを意味するようなメッセージが出る場合、Windowsで作成したパーティションが誤って読み込まれてしまっている場合が多いです。
sdaに相当するデバイスのパーティションを読み込んでそのように表示されているようなので、手動でパーティションを削除してからリトライしてみていただけますでしょうか。
下記のエラーにてインストールができません。
INFO Using node_serial from FRU
INFO Using block_id from FRU
INFO Generating cluster_id
INFO node_serial = JPH831P27Q, node_uuid = 40a17dca-a766-4932-99cf-93e00e2a9dca, block_id = JPH831P27Q, cluster_id = 5310888448224724712, model = USE_LAYOUT, model_string = CommunityEdition, node_position =
INFO Host boot_disk: sda
INFO Mounting Hyper-V FAT32 partition
ERROR An error occured while trying to illuminate the chassis LED
FATAL An exception was raised: Traceback (most recent call last):
File "./phoenix", line 125, in <module>
main()
File "./phoenix", line 84, in main
params = gui.get_params(gui.CEGui)
File "/root/phoenix/gui.py", line 1853, in get_params
gp.allowed_actions = determine_actions()
File "/root/phoenix/gui_actions.py", line 42, in determine_actions
hyp_state = get_hyp_state()
File "/root/phoenix/system_state.py", line 40, in get_hyp_state
state = hyp_class(params, None).get_state()
File "/root/phoenix/hyperv.py", line 33, in get_state
return self.customizer.get_state()
File "/root/phoenix/customize_hyperv.py", line 106, in get_state
self.__mount_hyperv_partition()
File "/root/phoenix/customize_hyperv.py", line 132, in __mount_hyperv_partition
if part_info.type.encode("utf-8") != "vfat":
AttributeError: 'NoneType' object has no attribute 'encode'
対応方法をご教授頂けますか。
宜しくお願い致します。
お世話になっております。
nutanix CEのインストールプロセスが途中で止まってしまい、インストールに失敗してしまいます。
idracから仮想メディアとしてce-2020.09.16.isoをマウントし起動。上の方と同じようにストレージの問題で止まった時に、idracからリムーバブルディスクとして適当なimgファイルをマッピングして再度、./ce_installerで開始するのですが以下のようになり中断されてしまいます。
何か考えられる解決策はございますでしょうか。
以下のメッセージ出力後、20-30分ほど待ちが発生しその後、中断されてしまいます。
INFO Getting AOS version from /mnt/iso/images/svm/nutanix_installer_package.tar.p00, This may take a few minutes if phoenix is running from BMC
[root@phoenix ~]# ./ce_installer && screen -r
2022-10-31-10:06:15-UTC ./ce_installer: line 298: [: too many arguments
2022-10-31-10:06:15-UTC Loading drivers
2022-10-31-10:06:16-UTC Removing the built-in i40e driver and reloading the new i40e driver
2022-10-31-10:06:16-UTC Getting DHCP address for phoenix
2022-10-31-10:06:16-UTC dhclient(2556) is already running - exiting.
2022-10-31-10:06:16-UTC
2022-10-31-10:06:16-UTC This version of ISC DHCP is based on the release available
2022-10-31-10:06:16-UTC on ftp.isc.org. Features have been added and other changes
2022-10-31-10:06:16-UTC have been made to the base software release in order to make
2022-10-31-10:06:16-UTC it work better with this distribution.
2022-10-31-10:06:16-UTC
2022-10-31-10:06:16-UTC Please report for this software via the CentOS Bugs Database:
2022-10-31-10:06:16-UTC http://bugs.centos.org/
2022-10-31-10:06:16-UTC
2022-10-31-10:06:16-UTC exiting.
2022-10-31-10:06:18-UTC Running /ce_installer
2022-10-31-10:06:19-UTC INFO Installing /usr/lib/python2.7/site-packages/foundation_layout-99.0+r.1284.8348b43-py2.7.egg
2022-10-31-10:06:19-UTC INFO /root/components doesnt exist
[screen is terminating]
INFO Read IOPS on sda: 92
INFO Model detected: CommunityEdition
INFO vpd_info {'node_serial': u'HZ9K522', 'vpd_method': None, 'rackable_unit_serial': u'HZ9K522'}
INFO Using node_serial from FRU
INFO Using block_id from FRU
INFO Generating cluster_id
INFO node_serial = HZ9K522, node_uuid = c05194ad-bbe3-4160-be63-ab34ce58b90d, block_id = HZ9K522, cluster_id = 1162667810275882560, model = USE_LAYOUT, model_string = CommunityEdition, node_position =
INFO ESX boot disk is busy, waiting for 5 sec. ret=0, out=1, err=
INFO Getting NOS version from the CVM
INFO Getting AOS version from /mnt/iso/images/svm/nutanix_installer_package.tar.p00, This may take a few minutes if phoenix is running from BMC
ダミーのイメージの認識とは具体的にどのような手順を取ったのでしょうか。
私は ImgBurnでdummy.imgファイルを作成して、idracより認識させました。
ダミーのイメージの認識とは具体的にどのような手順を取ったのでしょうか。
Userlevel 4
+9
- Nutanix Employee
- 92 replies
-
28 September 2022
1つ目のエラーメッセージでそれらしい内容としては、 /dev/sdf のディスクテストができないという表示がありますね…切り分けのために、いったん sdf に相当するディスクを外した状態でインストーラGUIが起動するかどうかをご確認いただくことは可能でしょうか?
screenが残らない件についても、↑のエラーでインストーラGUIの表示後にすぐに消える(あるいは表示に失敗する)、という挙動によるものかな推測しております。
5.18を新規インストールしているのですが、特にエラー表示もないまま途中で停止してしまい、何を解消すれば良いのかわからない状態です。
もし関連するエラーをご存じの方がいましたら、次にどこを確認したら良さそうか教えていただけませんか?
インストーラUSBで起動時下記が表示されます。
FATAL An exception was raised: Traceback (most recent call last):
File "./phoenix", line 125, in <module>
main()
File "./phoenix", line 84, in main
params = gui.get_params(gui.CEGui)
File "/root/phoenix/gui.py", line 1802, in get_params
gp.factory_config = sysUtil.find_factory_config()
File "/root/phoenix/sysUtil.py", line 478, in find_factory_config
block_devs = collect_disk_info()
File "/usr/lib/python2.7/site-packages/foundation_layout-99.0+r.1284.8348b43-py2.7.egg/hardware_inventory/disk_info.py", line 220, in collect_disk_info
perf_cache[dev_info.dev].readIOPS = test_device_perf_rd(dev_info.dev)
File "/usr/lib/python2.7/site-packages/foundation_layout-99.0+r.1284.8348b43-py2.7.egg/hardware_inventory/disk_info.py", line 325, in test_device_perf_rd
raise StandardError("Disk test could not run: (%d, %s)" % (ret, err))
StandardError: Disk test could not run: (1, fio: failed opening blockdev /dev/sdf for size check
file:filesetup.c:699, func=open(/dev/sdf), error=No medium found
fio: pid=0, err=123/file:filesetup.c:699, func=open(/dev/sdf), error=No medium found)その後、sshで再接続して、 ./ce_installer && screen -r を実行しても、
[root@phoenix ~]# ./ce_installer
2022-09-27-19:13:47-UTC ./ce_installer: line 298: [: too many arguments
2022-09-27-19:13:47-UTC Loading drivers
2022-09-27-19:13:50-UTC Removing the built-in i40e driver and reloading the new i40e driver
2022-09-27-19:13:50-UTC Getting DHCP address for phoenix
2022-09-27-19:13:50-UTC dhclient(3398) is already running - exiting.
2022-09-27-19:13:50-UTC
2022-09-27-19:13:50-UTC This version of ISC DHCP is based on the release available
2022-09-27-19:13:50-UTC on ftp.isc.org. Features have been added and other changes
2022-09-27-19:13:50-UTC have been made to the base software release in order to make
2022-09-27-19:13:50-UTC it work better with this distribution.
2022-09-27-19:13:50-UTC
2022-09-27-19:13:50-UTC Please report for this software via the CentOS Bugs Database:
2022-09-27-19:13:50-UTC http://bugs.centos.org/
2022-09-27-19:13:50-UTC
2022-09-27-19:13:50-UTC exiting.
2022-09-27-19:13:52-UTC Running /ce_installer
2022-09-27-19:13:52-UTC INFO Installing /usr/lib/python2.7/site-packages/foundation_layout-99.0+r.1284.8348b43-py2.7.egg
2022-09-27-19:13:52-UTC INFO /root/components doesnt existと表示されて、screen が残らない状態になってしまいます。ifconfigで DHCPでIPアドレスが取得できていることは確認済みです。(/tmp/phoenix.log もほぼ同様の内容で追記無い状態です。)
SSD(2TB) x2, HDD(2TB) x2, NIC x2 は認識済み
smzksts 様
各CVMから外部への通信はできており、またESXi側でのプロミスキャスモードの有効化もすべて行っております。。。
といろいろ試行錯誤しながらやっていると、別ノードのCVMからクラスタ構成を実行するとなんと成功しました。
原因が結局よくわからない状態ですが、なんとかマルチノードクラスタ構成は何とか完成しました。
一体何が原因だったのだろう・・・という状態ですが、取り急ぎ検証を進めます。
有難うございました。
Userlevel 4
+9
- Nutanix Employee
- 92 replies
-
31 August 2022
ESXi上でネストする際のネットワーク周りのお作法というと、ESXi側でのプロミスキャスモードの有効化くらいですね…ズバリ「これです!」というお答えが出来ず申し訳ありません。
現状、各CVMから外部へ向けての通信についても特に問題ない状態でしょうか?
CVM→自ノードのAHV、CVM→他ノードのAHV、CVM→他ノードのCVM、CVM→その他のIPアドレス、といった順序で切り分けをして行くのが良さそうに思います。
また、一手間掛かりますが、各ノードで一旦それぞれシングルノードクラスタを構成して、シングルノードクラスタ上のゲスト間の通信が正常であるか、といった確認をするのも1つの手かと思います。
smzksts 様
お世話になっております。
CEの勉強を始めているのですが、まずは環境をと思い、空いている物理ホストのESXi7.0U3上に3台のCE環境を準備し、マルチノードクラスターを構成しようとしているのですが、どうもうまくいきません。
それぞれのCVMにはpingが通るのですが、お互いCVM間の通信が不安定なようで、
cluster -s 172.30.0.211,172.30.0.212,172.30.0.213 create
を実行すると、
INFO cluster:2729 Executing action create on SVMs 172.30.0.211,172.30.0.212,172.30.0.213
CRITICAL cluster:975 Could not discover all nodes specified. Please make sure that the SVMs from which you wish to create the cluster are not already part of another cluster. Undiscovered ips : 172.30.0.212,172.30.0.213
となり、構成ができないようです。
当初pingはDUPになっていたので、物理ホストの物理NICが2枚なので、片方をスタンバイにすると重複はなくなったのですが、どうもpingが1回目はロストし、2回目以降に通信可能になり、clusterコマンドで失敗すると言う感じです。
CVMへの外部からの通信は問題ないので、CEノード間のCVMの通信に問題がありそうです。なにかマルチキャストの制御などの設定変更が必要なのでしょうか?
お作法等あればご教示いただきたく、宜しくお願いいたします。
お世話になります。
ASRock DeskMini H470上にce-2020.09.16環境を構築しようとしています。
インストール後、AHVにログインするとNICが認識しなくなり手詰まっています。
インストール時に認識しないという情報は沢山あるのですが、インストール後の事例が無く右往左往しています。
対策方法ありましたらご教示お願いします。
[構成]
ASRock DeskMini H470
Intel Corei5-11400
Team SO-DIMM PC4-25600 32GB x2
WD Blue PC M.2-2280 SATA WDS100T2B0B-EC
Seagate 2.5inch SATA HDD 1TB ST1000LM048
TRANSCEND TS32GJF720S
Nutanix Community Edition 5.18 徹底解説に沿って作業することでインストールは出来ました。
NICがI219-Vですので下記のe1000e.koドライバをロードすることで認識できました。https://smzklab.net/downloads
AHVにログインすると下記エラーとなり次に進まなくなってしまいます。
/etc/sysconfig/network-scripts/ifup-eth[9999]:Device eth0 dose not seem to be present, delaying initialization.
Faild to start LSB: Bring up/down networking.
network.service faild.
ifcfg-eth0の内容
-----------------
Device=eth0
TYPE=Ethernet
NM_CONTROLLED=no
NOZEROCONF=yes
ONBOOT=yes
BOOTPROTO=none
HWADDR=aa:aa:aa:aa:aa:aa
-----------------
HWADDRはインストール時に"ip a"で見えたMACアドレスが書き込まれています。
インストール時に設定したIPアドレスが書き込まれていない?
modprobeで読み込んでifupしても認識せず。
もう一度insmodで入れようとすると"signature not signed with a trusted key"となります。
セキュアブートはOFFですし、"mokutil --sb-state"でもSecureBoot disabledとなっています。
徹底解説にある方法で自前でドライバをmakeしても同じ現象になりました。
何か考えられる原因はあるでしょうか?
よろしくお願いします。
Page 1 / 3
Reply
Enter your E-mail address. We'll send you an e-mail with instructions to reset your password.