
Nutanix Community Edition(CE)に関する話題はこちらへどうぞ。
Page 2 / 3

Userlevel 4
 +9
+9
- Nutanix Employee
- 92 replies
-
28 September 2022
1つ目のエラーメッセージでそれらしい内容としては、 /dev/sdf のディスクテストができないという表示がありますね…切り分けのために、いったん sdf に相当するディスクを外した状態でインストーラGUIが起動するかどうかをご確認いただくことは可能でしょうか?
screenが残らない件についても、↑のエラーでインストーラGUIの表示後にすぐに消える(あるいは表示に失敗する)、という挙動によるものかな推測しております。
ダミーのイメージの認識とは具体的にどのような手順を取ったのでしょうか。
ダミーのイメージの認識とは具体的にどのような手順を取ったのでしょうか。
私は ImgBurnでdummy.imgファイルを作成して、idracより認識させました。
お世話になっております。
nutanix CEのインストールプロセスが途中で止まってしまい、インストールに失敗してしまいます。
idracから仮想メディアとしてce-2020.09.16.isoをマウントし起動。上の方と同じようにストレージの問題で止まった時に、idracからリムーバブルディスクとして適当なimgファイルをマッピングして再度、./ce_installerで開始するのですが以下のようになり中断されてしまいます。
何か考えられる解決策はございますでしょうか。
以下のメッセージ出力後、20-30分ほど待ちが発生しその後、中断されてしまいます。
INFO Getting AOS version from /mnt/iso/images/svm/nutanix_installer_package.tar.p00, This may take a few minutes if phoenix is running from BMC
[root@phoenix ~]# ./ce_installer && screen -r
2022-10-31-10:06:15-UTC ./ce_installer: line 298: [: too many arguments
2022-10-31-10:06:15-UTC Loading drivers
2022-10-31-10:06:16-UTC Removing the built-in i40e driver and reloading the new i40e driver
2022-10-31-10:06:16-UTC Getting DHCP address for phoenix
2022-10-31-10:06:16-UTC dhclient(2556) is already running - exiting.
2022-10-31-10:06:16-UTC
2022-10-31-10:06:16-UTC This version of ISC DHCP is based on the release available
2022-10-31-10:06:16-UTC on ftp.isc.org. Features have been added and other changes
2022-10-31-10:06:16-UTC have been made to the base software release in order to make
2022-10-31-10:06:16-UTC it work better with this distribution.
2022-10-31-10:06:16-UTC
2022-10-31-10:06:16-UTC Please report for this software via the CentOS Bugs Database:
2022-10-31-10:06:16-UTC http://bugs.centos.org/
2022-10-31-10:06:16-UTC
2022-10-31-10:06:16-UTC exiting.
2022-10-31-10:06:18-UTC Running /ce_installer
2022-10-31-10:06:19-UTC INFO Installing /usr/lib/python2.7/site-packages/foundation_layout-99.0+r.1284.8348b43-py2.7.egg
2022-10-31-10:06:19-UTC INFO /root/components doesnt exist
[screen is terminating]
INFO Read IOPS on sda: 92
INFO Model detected: CommunityEdition
INFO vpd_info {'node_serial': u'HZ9K522', 'vpd_method': None, 'rackable_unit_serial': u'HZ9K522'}
INFO Using node_serial from FRU
INFO Using block_id from FRU
INFO Generating cluster_id
INFO node_serial = HZ9K522, node_uuid = c05194ad-bbe3-4160-be63-ab34ce58b90d, block_id = HZ9K522, cluster_id = 1162667810275882560, model = USE_LAYOUT, model_string = CommunityEdition, node_position =
INFO ESX boot disk is busy, waiting for 5 sec. ret=0, out=1, err=
INFO Getting NOS version from the CVM
INFO Getting AOS version from /mnt/iso/images/svm/nutanix_installer_package.tar.p00, This may take a few minutes if phoenix is running from BMC
smzksts 様
大変お世話になっております。
ご提示いただいた情報をもとに、まず故障したホストの削除を試みてみました。
nutanix@cvm$ ncli host rm-start id=xxxxxx skip-space-check=trueHost removal successfully initiated
※xxxxxxは、「ncli host list」で確認した値
その後、「ncli host get-remove-status」で確認しますと、
Host Id : xxxxxxxxxxxxxxxxxxxxxxxxxxxxxx
Host Status : MARKED_FOR_REMOVAL_BUT_NOT_DETACHABLE
Ring Changer Host Address : xx.xx.xx.xx
Ring Changer Host Id : xxxxxxxxxxxxxxxxxxxxx
この状態のまま変化がない状態が続いており、PEで見ると依然ホストが削除されないまま残っているように見えます。
念のため、タスクも「ncli progress-monitor list」で確認してみましたが、削除コマンド実行時の時間に近い(UTC表示でしたので、9時間足して確認しています)タスクは表示されませんでした。
追加:
最初の書き込みで書き忘れがありましたので、追記しておきます。
「ncli host list」の出力で、削除したいホストの「Metadata store status」は
Metadata store status : Node is removed from metadata store
となっております。
なおPrismCentralの接続解除は、ご提示いただいたKBの内容で正常に行えました。
仮想マシンは残っていますが、とりあえず一歩前進した感じです。PEで見ても「Prism Central に登録されていません」となっているので、大丈夫だと思います。
仮想マシンのテーブルに元のPCの仮想マシンが残っていることを気にしなければ、新規でPrismCentralをデプロイしても問題ないでしょうか。
ホストの削除は、時間がかかっているだけかもしれませんので、もう少し時間をおいて再度確認してみようと思います。
また進捗があればご報告させていただきます。
smzksts 様
大変お世話になっております。
Prism Centralを削除しなくても新規で接続するのは問題ないとのことで、また一つ前に進めそうです。
※すぐに使えないといけない予定も無いので、あとからじっくりやってみようと思います。
acli vm.delete は実行してみましたが、PCの仮想マシンは削除できませんでした。
試しに他の仮想マシンでもやってみましたが、以下のような結果でした。
・「仮想マシン」ー「テーブル」でグレーになっている仮想マシンはタスクが0%のまま進まない
・赤(停止中)で正常なホストにいる仮想マシンは何の問題もなく削除できる
・緑(起動中)の仮想マシンでは試していません
ホスト削除のncli host rm-start force=true も実行してみましたが、こちらも
Host removal successfully initiated
と応答はあるものの、前回同様にタスクが出てくる気配がない状態です。
何度かトライしているので裏で処理が進んでないタスクが残っているのではと思い、
https://next.nutanix.com/how-it-works-22/clear-out-stuck-tasks-31879?postid=39355#post39355
ここの情報を参考にして
ecli task.list include_completed=false
で表示されたタスクはすべて
~/bin/ergon_update_task --task_uuid=xxxxxxxxxxxxxxxxx --task_status=aborted
で中断してみましたが、ホストの削除もVMの削除も効果が無い状況です。
少しNutanixバイブル(日本語版)も見て確認してみたんですが、ncli vm.delete には force=trueのような強制するオプションは無いのですよね?
あと試してみたことは、削除できない仮想マシンのディスクを acli vm.disk_delete で削除してからならできないかな?とも思ったのですが、これ自体も0%のままで進みませんでした。
きっと障害が発生したときに、あとからホスト削除→再構築して再度追加ではなく、ブートディスク(USBメモリ)の復旧をすればこんなことにはならなかったと深く反省している次第です。
※何度もやっている手順でもあったので、作業者に指示しやすかった面もあったのですが・・・。
とりあえず、3台構成でもテストや評価は進められる部分も多いので、気長に対応していこうと思います。
Userlevel 4
+9
- Nutanix Employee
- 92 replies
-
9 January 2021
PCの削除もノードの削除もレスポンスが無いというのは気になりますね…。
他のVMの作成/削除には支障ない状態でしょうか?
ご認識のとおり、acli vm.delete にはforceオプションはありません。本来、デフォルトでforceな形で処理されるものです。
MARKED_FOR_REMOVAL_BUT_NOT_DETACHABLEをキーワードとして検索して、他に関連しそうな公開KBとしては下記のもの程度でした。
AHV | Node removal stuck after successfully entering maintenance mode
https://portal.nutanix.com/page/documents/kbs/details?targetId=kA00e0000009D6CCAU
もしもこちらの状況に合致するようであれば、回避策として、Acropolisサービスのマスターを再起動する、という方法も考えられます。
- 任意のCVMのCLIにログインし
links http://127.0.0.1:2030
というコマンドを実行すると、テキストベースのウェブブラウザが実行されます。 - Acropolisサービスの詳細が表示されますので「Acropolis Master」という項目を確認します。「this node」または他のCVMのIPアドレスが表示されます。
- Acropolis Masterの項目に表示されたCVMにアクセスし。下記のコマンドでacropolisサービスを再起動します。
genesis stop acropolis; cluster start - もしも手順3でも変化がない場合には、メンテナンスモードの無効化と有効化を手動で行います。
acli host.exit_maintenance_mode <host IP or uuid>
acli host.enter_maintenance_mode <host IP or uuid>
他にもKBを探してみたのですが、あいにくInternal向け(非公開)なものに限られておりました…不安定な状態で様々な対応を試行するのもリスキーな気もしています(商用版ならサポート部門が解析した上でより的確な対応策をご案内するのですが、なにぶんCEのため…)。
もしも大事なGuest VMがある&CEをインストール可能な機材が他にもありましたらAsync DRでデータの退避した上で再インストールを行うなどの対応も視野に入れておいて頂くのがよろしいかもしれません。
お世話なります。
こちらのトピックのコメント受付がクローズされていたのでこちらに投稿させていただきます。
不適切でしたら申し訳ありません。
MinisforumというメーカーのPCにNutanix CEのインストールを試みておりますが、エラーが起きてしまっているため、皆様の知恵をお借りして解決を図りたいと思っております。
<発生している事象>
Nutanix CEのインストールが、screen is terminatingのメッセージを出力して開始されません。
screen is terminatingの前に出力されるFATALエラーのメッセージは下記の通りです。
FATAL: Couldn’t find a hypervisor and an AOS installed, please package phoenix with a hypervisor and a AOS. Please refer to KB-9010 if repair host boot device workflow is performed during an active AOS upgrade. Please refer to Nutanix support portal for more information about this.
<ハードウェア情報>
PC: Minisforum UM480XT(ベアボーンに下記メモリとストレージを搭載して利用)
CPU: AMD Ryzen 7 4800H
メモリ: DDR4 32GB 1枚
接続ストレージ: NVME SSD 500GB・SATA HDD 500GB・USB3.0Gen1 USBメモリ 32GB
インストールメディア: USB2.0 USBメモリ16GB
<その他捕捉情報>
- 当初こちらのURLと同じようにNICの認識がされませんでしたが、下記URLで共有されているigc.koを移送してロードすることで認識されました。ただし、認識されたに./ce_installer && screen -rを実行すると今度は上述のFATALエラーが出るようになりました。
- BIOSにてAMD-Vはenableになっていることを確認しました。
- インストールメディアに使用しているUSBメモリにはこちらのURLの手順と同等の手順で「phoenix-ce2.0-fraser-6.5.2-stable-fnd-5.3.4-x86_64.iso」を書き込みました。
問題の解決方法・切り分け方法がわかればご教示いただけるようお願いいたします。
お世話になります。
勉強のためにNutanixCEを触り始めようと、ESXi上にNutanix CEを建てようとしておりますが、
以下の問題で躓いております。
Nutanix CE 2.0 よろず相談所側に書き込みしようと思いましたが
コメント書き込みがクローズしているようなので、こちらで投稿いたします。
お知恵をお借りできないかと思い書き込みさせていただきました。
何卒よろしくお願いいたします。
■環境
・VMware ESXi7.0u3 上の仮想マシン
・vCPU:8core
ハードウェア アシストによる仮想化をゲスト OS に公開: ON
・vMem:64GB
・vDisk
32GB: H(Hypervisor Boot)
500GB:C(CVM Boot)
2000GB:D(Data)
・互換対象: ESXi 7.0 U2 以降(仮想マシン ハードウェア バージョン 19)
・ゲスト OS ファミリ: Linux
・ゲスト OS バージョン: CentOS 7 (64 ビット)
・最新のCEを利用
■発生している問題
上記構成で3台作ろうとしていて、それぞれ違う問題に直面しております。
それぞれシングルノード構成で作成しています。
1. CVMが起動してもサービスがなかなか上がらずPrismにアクセスできない
SSHではアクセスできますが、cluster statusを実行するも
WARNING genesis_utils.py:1199 Failed to reach a node where Genesis is up. Retrying... (Hit Ctrl-C to abort)
が出続ける。
2. CVMのサービスも全て上がり、PrismにアクセスOK
最低限の設定をして、仮想マシンの作成、LinuxのISOメディアのアップロード完了
仮想マシンを起動してもBIOS/UEFI上の画面で止まったまま進まない。(キー入力も受け付けない、CTRL+ALT+DELも受け付けない)
3. CVMのサービスも全て上がり、PrismにアクセスOK最低限の設定完了
ISOイメージをアップロードし、アップロード進むものの、Updateタスクがエラーとなり
ISOイメージが登録されない
解決方法があれば教えていただけないでしょうか。
Userlevel 4
+9
- Nutanix Employee
- 92 replies
-
26 January 2021
Twitter等では紹介していたのですが、CE関連の資料を作ったのでコチラにも載せておきます!
Nutanix CE 5.18のインストールに関する詳細解説資料です。
インストール周りで躓きがちなポイントとその回避方法をたくさん載せてますので、
上手くいかないときにまずはご一読くださいませ。
(背景)
お世話になっております。keroro9と申します。業務ではスクラップ&ビルドが難しいので、個人の機材でいろいろやっております。普通にNutanixを入れるというところは到達できましたので、ハイパーバイザをESXi(+vCenter)で動かせないかと思い実験しています。
(現象)
phoenix-ce2.0-fraser-6.5.2-stable-fnd-5.3.4-x86_64.iso を用いて、ESXiのISOはVMware-ESXi-7.0.3-22348816-HPE-703.0.0.11.5.0.6-Oct2023.isoを用いて検証を行っております。インストーラは正常終了し、その後ESXiが起動。何度か再起動を繰り返し、インストール進捗に応じてCVMのVM名が変更されます。しばらく待つとFailed-installとVM名が変わります。この時、ストレージは
NTNX-local-ds-038819d1-Aというものができていますが、本来期待した容量よりはるかに小さく、正常に生成されていないと考えられます。
(お伺いしたい事)
・まず前提のログ調査などが行えていません。皆様にお伺いする際にざっと見たほうが良いログの調査方法、場所などご教示いただけませんか。
・一般的な知見において、Failed-installに落ちてしまう原因があれば教えてください。
(環境情報)
ProLiant DL360 Gen9
CPU E5-2690 v4 @ 2.60GHz *2
メモリ 128GB
SSD KingFast 256GB*2
SAS HDD 900GB*3
NVMe SSD 2TB
インストール時の構成は下記のとおりです。
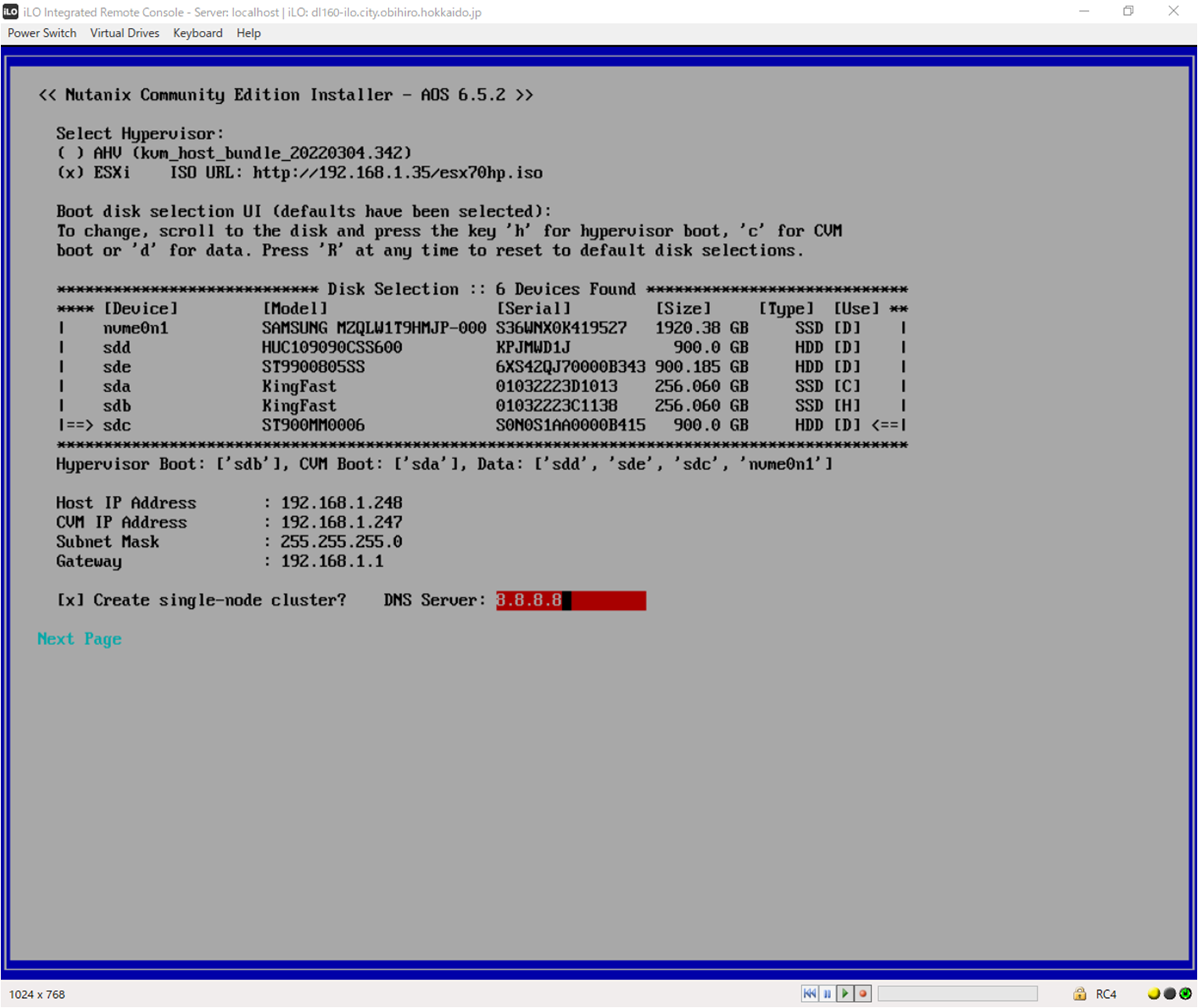
@smzksts お世話になっております。keroro9です。こちらこそreply気が付かずすみません。機材が実家にある関係で(VPN越しに触れはしますが)、あまり注力できていない現状はあります。それはされておき、状況についてご教示いただきありがとうございました。(非サポートとはいえ)こちらでも確認してみます。
こんにちは。
https://speakerdeck.com/smzksts/nutanix-ce-5-dot-18-deep-dive?slide=56
上記の56スライド目以降を拝見して、Nutanix CE 5.18にESXiをインストールするときに必要なLocal VMFS有効化を行おうとしましたが、インストール後リブート前に/dev/sdd5 をマウント時にdoes not exitと返されてしまい、/dev/sda5 の起動用のjsonファイルの該当箇所は元から
"user_vmfs?_datastore":"true"
となっているのですが、そのままrebootをかけるとFaild-Installになってしまいますが、
ssd5のパスは環境によってかわりますでしょうか。(ls /dev で確認したところssd1のみ確認できましたが/Nutanix以下のディレクトリはなし)
■試したESXiバージョン
7.0U2a-17867351
7.0-15843807
6.7-14320388
何卒宜しくお願い致します。
下記のエラーにてインストールができません。
INFO Using node_serial from FRU
INFO Using block_id from FRU
INFO Generating cluster_id
INFO node_serial = JPH831P27Q, node_uuid = 40a17dca-a766-4932-99cf-93e00e2a9dca, block_id = JPH831P27Q, cluster_id = 5310888448224724712, model = USE_LAYOUT, model_string = CommunityEdition, node_position =
INFO Host boot_disk: sda
INFO Mounting Hyper-V FAT32 partition
ERROR An error occured while trying to illuminate the chassis LED
FATAL An exception was raised: Traceback (most recent call last):
File "./phoenix", line 125, in <module>
main()
File "./phoenix", line 84, in main
params = gui.get_params(gui.CEGui)
File "/root/phoenix/gui.py", line 1853, in get_params
gp.allowed_actions = determine_actions()
File "/root/phoenix/gui_actions.py", line 42, in determine_actions
hyp_state = get_hyp_state()
File "/root/phoenix/system_state.py", line 40, in get_hyp_state
state = hyp_class(params, None).get_state()
File "/root/phoenix/hyperv.py", line 33, in get_state
return self.customizer.get_state()
File "/root/phoenix/customize_hyperv.py", line 106, in get_state
self.__mount_hyperv_partition()
File "/root/phoenix/customize_hyperv.py", line 132, in __mount_hyperv_partition
if part_info.type.encode("utf-8") != "vfat":
AttributeError: 'NoneType' object has no attribute 'encode'
対応方法をご教授頂けますか。
宜しくお願い致します。
Hyper-Vを意味するようなメッセージが出る場合、Windowsで作成したパーティションが誤って読み込まれてしまっている場合が多いです。
sdaに相当するデバイスのパーティションを読み込んでそのように表示されているようなので、手動でパーティションを削除してからリトライしてみていただけますでしょうか。
ご説明頂きました通り、「mkfs -t ext4 /dev/sda」を実行したところ、インストールが進みました。
追加で質問ですが、中古のWindowsを購入したのですが、そのSSDにWindowsのパーティションがあったから?
それともパーティションが切られると同様のエラーが再現する?
以上、ご教示の程宜しくお願い致します。
お世話になります。junk11と申します。
徹底解説のスライドを参照しCEの5.18インストールを試みているのですが20pの記載に従い
UEFI起動順を設定してもエラーになり、SSH経由でリトライしても[screen is terminating]となり
インストールに進めない事象となります。
https://speakerdeck.com/smzksts/nutanix-ce-5-dot-18-deep-dive?slide=20
H/W構成の概要は以下の通りです。
Lenovo ThinkCentre M75s Small Gen2
Ryzen7 PRO 4750G 32GB
samsung 970 EVO Plus 2TB(Hot Tier:nvme0n1)
Seagate ST8000DM004 8TB(Cold Tier:sdb)
intel SSDSA2M080G2GC 120GB(HV起動用:sda)
KIOXIA USB3.2 Gen1 32GB(iso起動用:sdc)
[root@phoenix ~]# lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
nvme0n1 259:0 0 1.8T 0 disk
sdb 8:16 0 7.3T 0 disk
sr0 11:0 1 1024M 0 rom
loop0 7:0 0 194M 0 loop
sdc 8:32 1 28.9G 0 disk
└─sdc1 8:33 1 28.9G 0 part /mnt/iso
sda 8:0 0 111.8G 0 disk
└─sda1 8:1 0 111.8G 0 part
事前の情報収集にてできるだけ実績のある(ありそうな)ものを
チョイスしたつもりですが、行き詰り、困り果てております。
何のどこから確認したものか、ヒントだけでもいただければ幸いです。
以上、よろしくお願いいたします。
Userlevel 4
+9
- Nutanix Employee
- 92 replies
-
2 March 2023
SSDにWindowsのファイルシステムでフォーマットされたパーティションがあったのが原因と考えられます。パーティションを切っただけなら大丈夫です。
Userlevel 4
+9
- Nutanix Employee
- 92 replies
-
2 March 2023
【お知らせとお願い】
Nutanix CE 2.0リリースに伴い、CEに関する話題は新しいスレッドに移行したいと思います。
こちらのスレッドも残しておきますが、今後は Nutanix CE 2.0 よろず相談所 をご活用ください。
UEFI起動順を設定してもエラーになり、SSH経由でリトライしても[screen is terminating]となり
インストールに進めない事象となります。
上記続報、自己レスです。
ストレージの接続や構成をいろいろと変更して試していたところ、起動用USBを含め、物理ストレージが4台以上となると上記の事象となる様です。
4台すべてUSB経由⇒NG
USBBoot+3台SATA接続⇒NG
SATABoot+2台SATA+1台nvme⇒NG
SATABoot+2台SATA⇒TUI起動するが、NextPageを選択で同様のスクリーンサイズ不足エラー発生。
(そもそもBoot imageを保持するディスクに対しH/C/Dを選択せざるを得ない構成)
SATAorUSB Boot+1台SATA+1台nvme⇒同上
今回利用しているLenovo M75s Gen2はSpeaker Deckのスライドp18にも言及があり、
インストールの実績があるものと思いますが成功された方はどのようなストレージ構成だったのでしょうか?
BIOS(UEFI)の設定変更やインストールスクリプトの変更などが必要なのでしょうか。
ご存じの方がいらっしゃいましたらぜひ情報提供をお願いします。
Userlevel 4
+9
- Nutanix Employee
- 92 replies
-
21 November 2021
junk01さん、すみません返信遅くなりました。
M75sでインストール成功しているのは私の自宅環境ですね。
このマシンだとブートデバイス優先度の変更では成功しなかったため、SSH経由でインストールしました。
また、ディスク構成は下記のとおりです。記載いただいている環境と大きな違いはないように思います…。
AHV→NVMe SSD(120GB)
CVM→SATA-SSD(2TB)
Data→SATA-SSD(2TB)
Screen is terminatingとなってしまう場合、Teraterm等のログ機能を使って、Terminatingの表示になる直前にどのようなエラーが表示されていたのかを確認すると解決のヒントになるかもしれません。
ご回答いただきありがとうございます。
改めてTeraerm利用しSSH経由で実施してみましたが、状況変わらずで、画面表示は以下の通りでした。
2021-11-23-06:45:58-UTC ./ce_installer: line 298: [: too many arguments
2021-11-23-06:45:58-UTC Loading drivers
2021-11-23-06:45:59-UTC Removing the built-in i40e driver and reloading the new i40e driver
2021-11-23-06:45:59-UTC Getting DHCP address for phoenix
2021-11-23-06:45:59-UTC dhclient(3699) is already running - exiting.
2021-11-23-06:45:59-UTC
2021-11-23-06:45:59-UTC This version of ISC DHCP is based on the release available
2021-11-23-06:45:59-UTC on ftp.isc.org. Features have been added and other changes
2021-11-23-06:45:59-UTC have been made to the base software release in order to make
2021-11-23-06:45:59-UTC it work better with this distribution.
2021-11-23-06:45:59-UTC
2021-11-23-06:45:59-UTC Please report for this software via the CentOS Bugs Database:
2021-11-23-06:45:59-UTC http://bugs.centos.org/
2021-11-23-06:45:59-UTC
2021-11-23-06:45:59-UTC exiting.
2021-11-23-06:46:01-UTC Running /ce_installer
2021-11-23-06:46:01-UTC INFO Installing /usr/lib/python2.7/site-packages/foundation_layout-99.0+r.1284.8348b43-py2.7.egg
2021-11-23-06:46:01-UTC INFO /root/components doesnt exist
INFO Model detected: CommunityEdition
INFO vpd_info {'vpd_method': None}
INFO Generating cluster_id
INFO node_serial = f4c4400e-d133-4eda-a9d0-139c3a6c1082, node_uuid = 53bca156-ef55-4e00-b196-e050faa32fd3, block_id = , cluster_id = 2739627187682289439, model = USE_LAYOUT, model_string = CommunityEdition, node_position =
INFO Getting NOS version from the CVM
INFO Phoenix ISO is already mounted
INFO Getting AOS version from /mnt/iso/images/svm/nutanix_installer_package.tar.p00, This may take a few minutes if phoenix is running from BMC
Terminal screen is not large enough to run the installation script. Please resize the terminal and rerun the script.
[screen is terminating]
[root@phoenix ~]#
個人的にはINFO /root/components doesnt existの表示が気になっているところです。
成功時の確認ですが、一般的なUSBメモリにて2020.09.16版のiso利用という事で良いでしょうか?
BIOS(UEFI)の設定も特に変更不要でしょうか?
質問ばかりで申し訳ありませんが、よろしくお願いいたします。
Userlevel 4
+9
- Nutanix Employee
- 92 replies
-
24 November 2021
Terminal screen is not large enough to run the installation script. Please resize the terminal and rerun the script.
というメッセージが最後に出ているので、SSHクライアントの縦横の表示文字数(ウィンドウサイズ)を目一杯広げてからインストーラーを再実行してみてはいかがでしょうか?
成功した環境ですとSSHクライアントはWindowsでTeraTermを使用し、縦横の表示文字数を増やして(ウィンドウサイズを大きくして)からインストーラーを再実行することで成功しています。
逆に、SSHクライアント経由でもウィンドウサイズを変えていなかったり、広げ方が不十分だったりすると、ローカルコンソールと同様に↑のメッセージが出て失敗します。TeraTermもデフォルトの80x24文字だと小さ過ぎてエラーになりました。BIOS設定は特に変更していなかったと記憶しています。
Userlevel 4
+9
- Nutanix Employee
- 92 replies
-
24 November 2021
> 成功時の確認ですが、一般的なUSBメモリにて2020.09.16版のiso利用という事で良いでしょうか?
こちらについては、一般的なUSBメモリで通常の2020.09.16版のISOを利用しています。NICドライバだけはオンボードのRealtekをインストーラーが自動認識できないので、自分でビルドしたものを使いました。
Page 2 / 3
Reply
Enter your E-mail address. We'll send you an e-mail with instructions to reset your password.