

本記事は2020年3月9日にJosh Odgers氏が投稿した記事の翻訳版です。
このシリーズでは、Nutanix AOSソリューションがvSAN / VxRAILと比較して、多くのアーキテクチャ上の利点があることを学んできました。
この記事では、実世界のネットワークトラフィックがパフォーマンスに与える影響の例を紹介します。これまでに説明してきたコンセプトの多くが証明できます。この例では、ビッグデータのインジェスト処理のような書き込みの多いワークロードを見てみましょう。
ベースラインとなるテスト:
2つの同一構成の4ノード・クラスターを使用します。完全にアイドル状態になるのを待って 、X-Rayを使ってビッグデータ取り込みのシナリオを開始しました。2つのプラットフォームは同じくらいの時間でデータの取り込みを完了しました。
Nutanix AOSは13分、VMware vSANは14分でした。
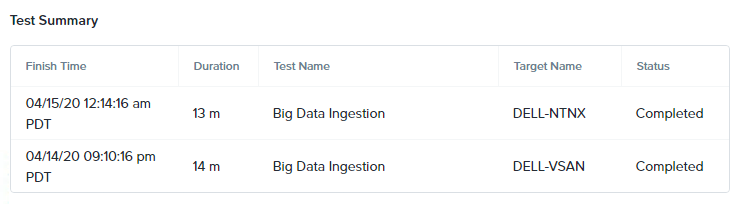
テスト中のネットワーク使用率は、どちらのソリューションも約2GBpsで、vSANはテストが半分ほど経過したところで約1.5GBpsに低下しました。
次に、各ホスト上でiPerfを実行し、実世界のシナリオをシミュレートしました。ストレージトラフィックだけでなくVM間やクライアント・サーバ間のトラフィックを処理する環境です。
iPerfでネットワークトラフィックを生成した環境でのテスト
次のグラフは、テスト全体のネットワーク帯域幅を示しています。この中にはiPerf(~6GBps)で生成されるトラフィックとX-Rayのシナリオで生成されるビッグデータ取り込み(前のグラフのように~2GBps)の両方のトラフィックが含まれています。これらは両プラットフォームで同様の条件です。
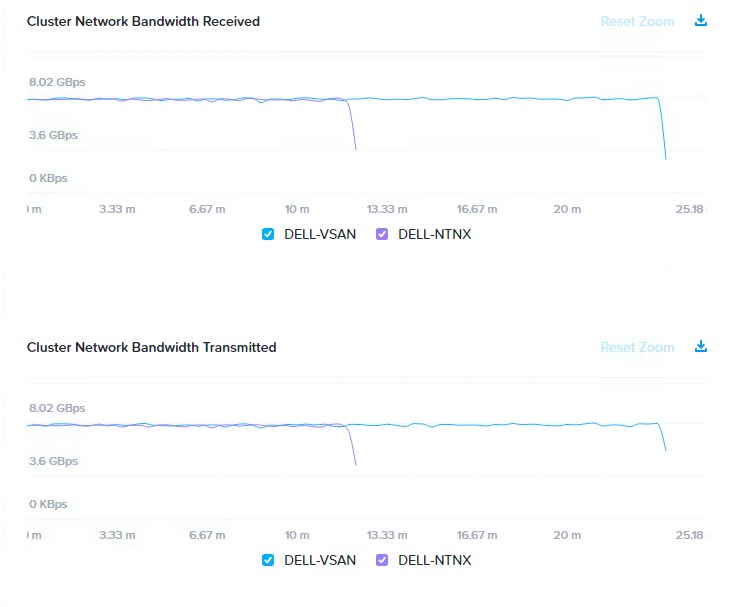
当然のことながら、いくつかの影響が見られました。このテストは100%書き込みで、両方のプラットフォームが書き込みレプリカにネットワークを使用しなければならないためです。
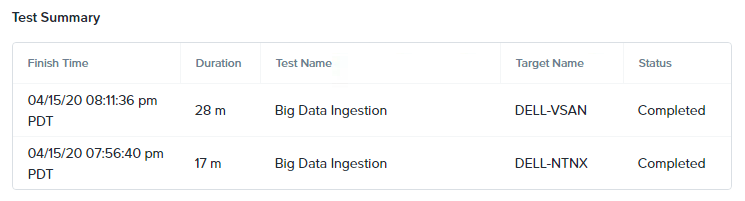
Nutanixへの影響としては、シナリオ完了までに4分(~31%増)多くの時間がかかりました。vSANは14分(~100%増)多くかかりました。
なぜこんなにも差がでるのでしょうか?
俯瞰的に見れば、両方のクラスターのネットワークトラフィックはほぼ同じで、どちらも2つのレプリカ(NutanixではRF2、vSANではFTT1)を使用しているため、この結果は納得できるものではありません。
確かに、過去の記事で解説したように、マーケティングのスライドからだけでなく、両方の製品の根本的なアーキテクチャの違いを見極めない限り 、この結果は理解ができません。
このシリーズの以前の記事の、書き込みI/Oパスの比較では、Nutanixがクラスタの容量利用率とパフォーマンスに基づいて、クラスタ全体にレプリカを能動的に分散させることを説明しました。一方、vSANは静的なオブジェクトストアベースでの分散処理を行っているため、単一のノードやネットワークのパフォーマンスの制約を許容したり軽減したりする柔軟性がありません。
これは公平な比較なのでしょうか?
この比較は、X-RayがVMをデプロイし、VMが作成されたホスト上で負荷試験を実行するため、vSANにとっては最良のシナリオです。つまり、(運が良かったとはいえ)可能な限り最大のデータのローカリティを享受できるということです。もしこのテスト中にVMが移動されたとしたら、特にVMのオブジェクトをホストしていないホストに移動されたとしたら、書き込みの100%(両方のレプリカ)がネットワーク経由で行われることになります。
こちらの方がより現実的なシナリオとなります。HCI環境ではVMが移動することがあるためです。ですから、もし私が製品間のより大きな違いを示そうとするなら、テスト前またはテスト中にVMをvMotionさせるでしょう。
まとめ:
ネットワーク(HCI環境ではネットワークも基本的はストレージファブリックです)が、実際の環境のように適度に使用されている場合(ここでは25GBのNICを8GBpsで使用)、vSANのパフォーマンスは大きく変化します。Nutanixでは真の分散型ストレージファブリックとインテリジェントな(書き込み)レプリカの配置のおかげで、影響ははるかに合理的です。
プラットフォームを比較する際には、iPerfのようなツールを使用して、少なくともいくらかのネットワークトラフィックを生成することが重要です。これにより、アイドル状態のクラスターで4Kランダムリードの「ピークパフォーマンス」ベンチマークを実行するよりも、より現実的なシナリオをシミュレートすることができます。