

Hi team, i have questions about capacity calculator
let say i have config for 3 node like the picture below,
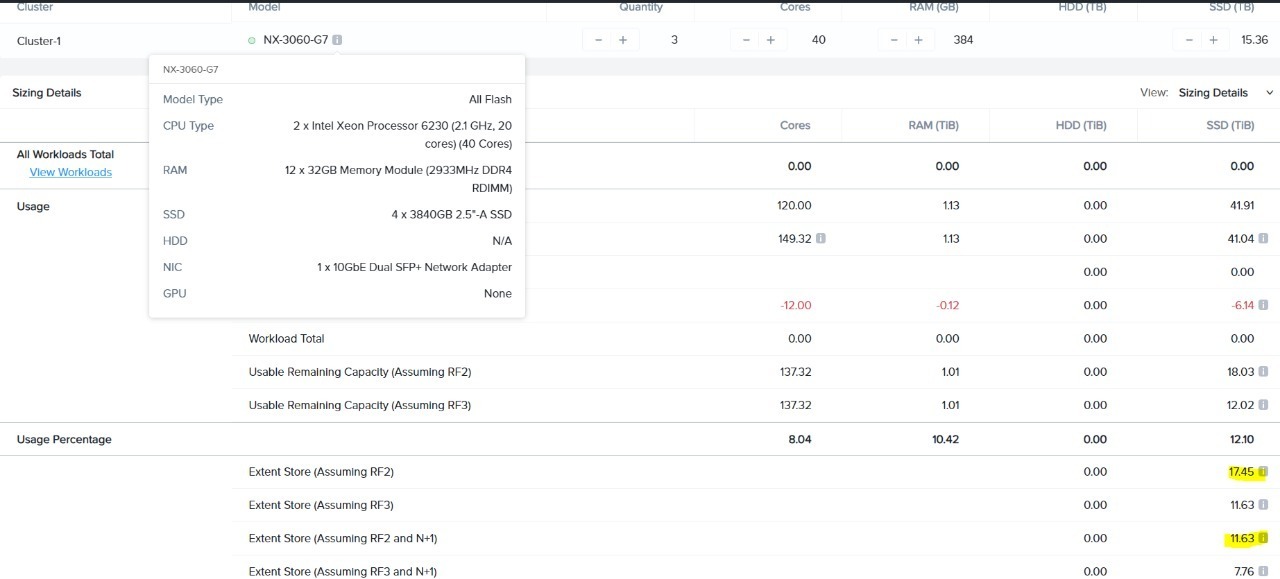
so in prism will show me 17TB logical capacity correct?
and i have concern in extent store RF2 and N+1 (11TB) in sizer tool, what happen if i have data 15TB which is bigger than RF2 and N+1 size (11TB)?


