



Here I discuss the effects of Enabling or Disabling Deduplication on a container even if the Container has data already written to it.
The benefit of Compression and Fingerprinting+Deduplication is to hold more data in the container, by reducing the stored size and avoiding duplicate data, respectively.
Nutanix’s intelligent selection of dedupable candidates prevents deduplication being performed where the benefit would be low.
Deduplication Best Practices:
| Enable deduplication | Do not enable deduplication |
|
|
Enabling Dedupe:
Fingerprinting is method of creating signatures of the data in Metadata. Fingerprint-on-write (Cache-Tier-Deduplication) is a method of seeding data into the container in order to be eligible for deduplication. This process increases the metadata. Since the data is not localized to any one particular Node, it is averaged across all node in the cluster.
When Deduplication is turned ON,
-
The fingerprinting process is started on all the new write-on-disk. Only the ‘new’ data will be fingerprinted-on-write.
In order to fingerprint the existing data, if turning ON deduplication on an existing container, manual steps needs to be taken, But if the data is frequently overwritten, then eventually all the data will be fingerprinted and be used for deduplication.
Disabling Dedupe:
Deduplication can be disabled anytime on the container.
-
Data which is deduped remains in this state even after the feature is disabled. So in this case, any space saved will not bloat up if the feature is disabled.
The simplest way to un-dedupe the data is to storage vmotion the data to a container where deduplication is turned OFF. This will reduce the metadata load gained by fingerprinting the data.
You can see realistic space-saving by running the command below or from the storage section in your Prism UI:
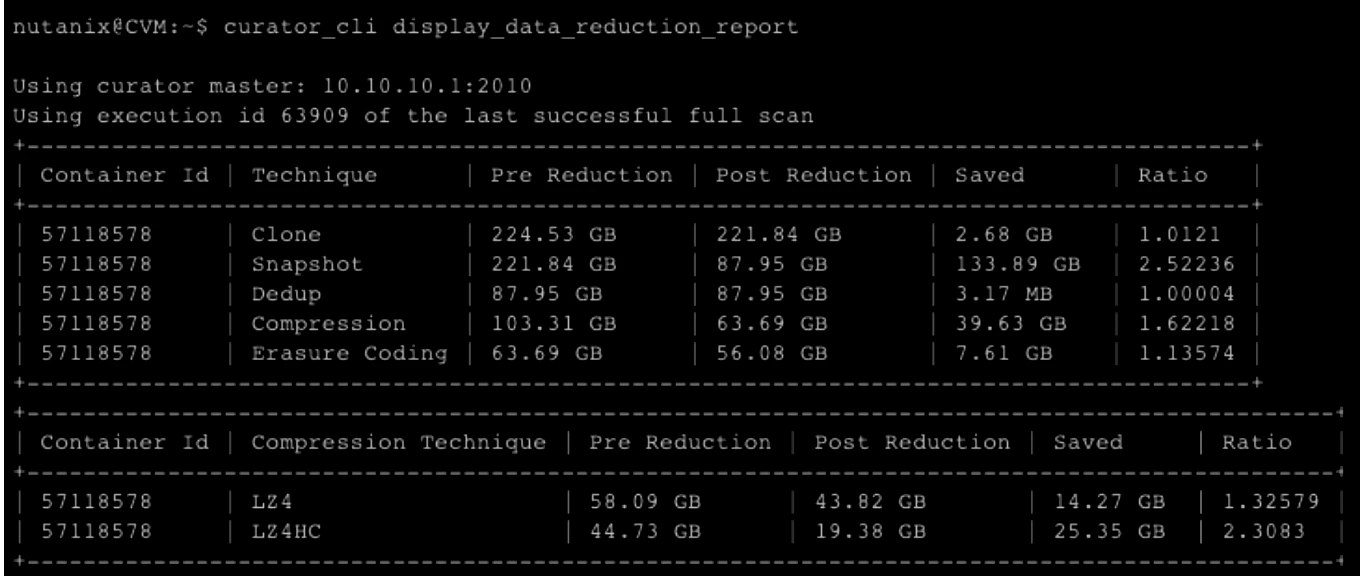
Deduplication:
How to Fingerprint existing vDisks: (Turning on Deduplication is a must in order to fingerprint existing data)